Liebt mich, liebt mich nicht: Klassifizieren von Texten mit TensorFlow und Twilio
Lesezeit: 5 Minuten
February 12, 2020
Autor:in:

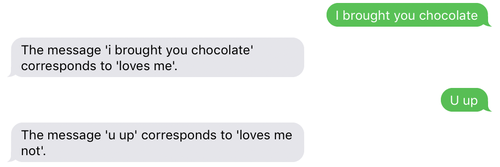
Der Valentinstag steht kurz bevor und nicht nur die Liebe sondern auch maschinelles Lernen liegen in der Luft. Manche würden wohl die althergebrachten Blütenblätter verwenden, um herauszufinden, ob jemand ihre Liebe erwidert, aber Entwickler würden vermutlich eher auf ein Tool wie TensorFlow zurückgreifen. In diesem Blog zeige ich, wie eine binäre Textklassifizierung mit neuronalen Netzwerken über Twilio und TensorFlow in Python durchgeführt wird. Wir können eine Textnachricht an +16782767139 senden, um diese Textklassifizierung zu testen.
Voraussetzungen
- Ein Twilio-Konto. Melde dich hier für ein kostenloses Konto an und du erhältst ein Guthaben von 10 $, wenn du über diesen Link ein Upgrade durchführst.
- Eine Twilio-Telefonnummer mit SMS-Funktion. Hier kannst du eine Nummer konfigurieren.
- Einrichten der Python- und Flask-Entwicklerumgebung. Stelle sicher, dass du Python 3 und ngrok heruntergeladen hast.
Einrichtung

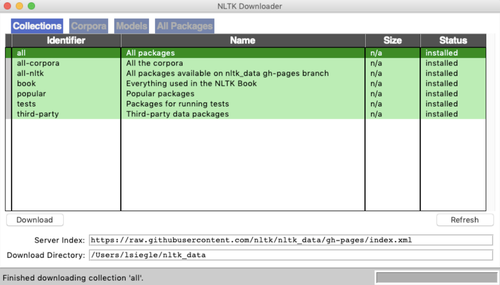
Wir aktivieren eine virtuelle Umgebung in Python 3 und laden diese requirements.txt-Datei herunter. Wir müssen darauf achten, dass wir Python 3.6.x für TensorFlow verwenden. In der Befehlszeile führen wir pip3 install -r requirements.txt aus, um alle erforderlichen Bibliotheken zu importieren. Zum Importieren von nltk erstellen wir ein neues Verzeichnis mit mkdir nltk_data. Wir fügen cd ein und führen dann den Befehl python3 -m nltk.downloader aus. Wir sollten folgendes Fenster sehen. Wir wählen alle Pakete aus, wie im folgenden Screenshot dargestellt:
Unsere Flask-App muss im Internet sichtbar sein, damit Twilio Anfragen an die App senden kann. ngrok vereinfacht dieses Verfahren. Wir führen bei installiertem ngrok den Befehl ngrok http 5000 in dem Verzeichnis aus, in dem sich unser Code befindet.
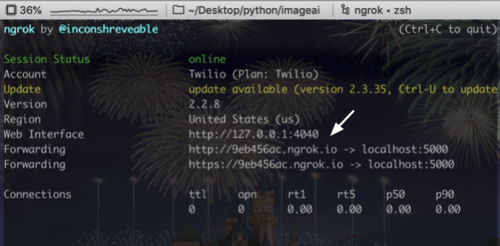
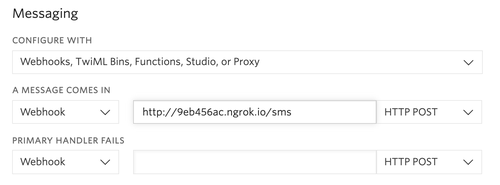
Wir sollten den oben abgebildeten Bildschirm sehen. Wir kopieren diese ngrok-URL, um unsere Twilio-Nummer zu konfigurieren:
Vorbereiten der Trainingsdaten
Wir erstellen eine neue Datei mit dem Namen data.json, die zwei Arrays mit Sätzen enthält, die entweder dem Label „loves me“ (Liebt mich) oder „loves me not“ (Liebt mich nicht) entsprechen. Wir können die Sätze in den Arrays beliebig abändern oder eigene Sätze hinzufügen (je mehr Trainingsdaten, desto besser; dieses Beispiel enthält zwar bei Weitem nicht genug Daten, aber es ist ein guter Start.)
Wir erstellen eine Python-Datei mit dem Namen main.py. Am Anfang der Datei importieren wir die erforderlichen Bibliotheken. Dann erstellen wir die Funktion open_file, um die Daten von data.json als data-Variable zu speichern.
Lesen von Trainingsdaten
In diesem Blog verwenden wir eine Lemmatisierung, um zur Grundform eines Wortes zu gelangen, z. B. wird dabei „geht“ in „gehen“ umgewandelt. Für diese Aufgabe könnte auch eine Stammformreduktion, bei der Wörter auf ihren Wortstamm reduziert werden, verwendet werden. Allerdings erkennt die Stammformreduktion nicht, dass „gut“ ein Lemma von „besser“ ist. Lemmata erfordern zwar mehr Zeit bei der Verwendung, sind aber effizienter. Wir können bei der Arbeit mit der linguistischen Datenverarbeitung (Natural Language Processing, NLP) sowohl mit der Stammformreduktion als auch der Lemmatisierung experimentieren.
Direkt unterhalb der data-Variablendeklaration initialisieren wir die Lemmatisierung und stellen diese Funktion so ein, dass der Stamm jedes Wortes gebildet wird:
Die nächste Funktion liest die Trainingsdaten, entfernt Satzzeichen, verarbeitet Kontraktionen und extrahiert Wörter aus jedem Satz und fügt diese einer Wortliste an.
Als Nächstes bestimmen wir die möglichen Labels („loves me“ und „loves me not“), an denen das Modell trainiert werden soll, und initialisieren eine leere json_data-Liste, in der Tupel von Wörtern aus dem Satz und der Name des Labels enthalten sind. Die training_words-Liste enthält alle eindeutigen Wortstämme aus den JSON-Trainingsdaten und binary_categories enthält die möglichen Kategorien für die Klassifizierung.
Die zurückgegebenen json_data ist eine Liste mit Wörtern aus jedem Satz und entweder loves_me oder loves_me_not. Beispiel: Ein Element in dieser Liste ist (["do", "you", "want", "some", "food"], "loves_me"). Diese Liste enthält zwar nicht alle möglichen Kontraktion, aber das Prinzip sollte klar sein:
Anschließend bilden wir den Stamm jedes Wortes, um Duplikate zu entfernen, und rufen die read_training_data-Funktion auf.
Damit TensorFlow diese Daten auch versteht, müssen die Zeichenfolgen in Zahlen umgewandelt werden. Diese Aufgabe kann mit dem Bag-of-Words-NLP-Modell erledigt werden. Dabei wird die Gesamtanzahl der Vorkommen der am häufigsten verwendeten Wörter erfasst. Beispiel: Der Satz „Never gonna give you up never gonna let you down“ könnte folgendermaßen dargestellt werden:

Für die Labels loves_me und loves_me_not wird eine Bag-of-Words als Liste mit tokenisierten Wörtern initiiert, die hier vector genannt wird. Wir durchlaufen die Wörter im Satz, wobei wir die Wortstämme bilden und sie mit jedem einzelnen Wort im Wortschatz abgleichen. Wenn der Satz ein Wort aus unseren Trainingsdaten oder dem Wortschatz enthält, wird dem Vektor eine 1 angefügt. Das signalisiert, zu welchem Label das Wort gehört. Falls das nicht der Fall ist, wird eine 0 angefügt.
Am Ende hat unser Trainingsdatenset ein Bag-of-Words-Modell und eine Ausgabezeile, die dem Label entspricht, zu dem die Bag-of-Words gehört.
Jetzt setzen wir die zugrunde liegenden Diagrammdaten zurück und löschen bei jedem Ausführen des Modells festgelegte Variablen und Operationen aus der vorherigen Zelle. Als Nächstes erstellen wir ein neuronales Netzwerk mit drei Schichten:
- Die
input_data-Eingabeschicht dient der Eingabe oder dem Einspeisen von Daten in ein Netzwerk. Die Eingabe in das Netzwerk hat die Größelen(data[0])für die Länge unserer kodierten Bag-of-Words und den kodierten Labels. - Dann erstellen wir zwei vollständig verbundene Zwischenschichten mit 32 verborgenen Einheiten oder Neuronen. Während manche Funktionen mehr als eine Schicht zum Ausführen benötigen, machen mehr als drei Schichten wahrscheinlich keinen großen Unterschied. Deshalb sind zwei Schichten ausreichend und sollten auch nicht zu rechenintensiv sein. Wir verwenden in diesem Fall die
softmax-Aktivierungsfunktion, da die Labels exklusiv sind. - Schließlich erstellen wir das endgültige Netzwerk aus der Estimator-Schicht, z. B. Regression. Vereinfacht gesagt, unterstützt die Regression (linear oder logistisch) Vorhersagen zum Ausgang eines Ereignisses anhand der Eingabedaten. Neuronale Netzwerke haben mehrere Schichten, um kompliziertere Abstraktionsbeziehungen aus den Eingabedaten besser zu lernen.
Ein Deep Neural Network (DNN) führt automatisch Klassifizierungsaufgaben für das neuronale Netzwerk durch, z. B. das Trainieren des Modells und Vorhersagen, die auf den Eingabedaten basieren. Das Training wird durch Aufrufen der fit-Methode gestartet. Zusätzlich wird der Gradientenabstiegsalgorithmus angewendet, ein allgemeiner Deep-Learning-Algorithmus für die Optimierung erster Ordnung. n_epoch gibt an, wie oft das Netzwerk alle Daten sieht, und batch_size ist die Größe, in die die Daten zum Trainieren des Modells aufgeschlüsselt werden.
Ähnlich wie bei der Verarbeitung der Daten für das Bag-of-Words-Modell müssen diese Daten in die numerische Form umgewandelt werden, die an TensorFlow übergeben werden kann.
Um das ohne Textnachrichten zu testen, könnten wir Folgendes hinzufügen:
Dadurch wird die predict-Methode für das Modell aufgerufen, wobei die Position des größten Werts abgerufen wird, der die Vorhersage darstellt.
Wir werden das mit Textnachrichten testen. Dazu erstellen wir eine Flask-Anwendung.
Erstellen einer Flask-App
Wir fügen den folgenden Code hinzu, um eine Flask-App zu erstellen. Dann rufen wir die eingehende Textnachricht ab, erstellen einen Tensor und rufen das Modell auf.
Wir öffnen neben dem Terminal, in dem ngrok ausgeführt wird, ein neues Terminalfenster. In dem Ordner, der unseren Code enthält, führen wir die Telefonnummer aus und senden an diese Nummer einen Satz, z. B. „get someone else to do it“. Wir sollten Folgendes sehen:

Der vollständige Code und die requirements.txt-Datei befinden sich hier auf GitHub.
Wie geht es weiter?

Was steht als Nächstes zur Klassifizierung an? Wir könnten das Universal Sentence Encoder-Modul von TensorFlow verwenden, um ähnliche Textklassifizierungen in JavaScript durchzuführen, wir könnten Telefonanrufe oder E-Mails klassifizieren, eine andere Aktivierungsfunktion wie z. B. sigmoid verwenden, wenn wir Kategorien haben, die sich gegenseitig ausschließen, und vieles mehr. Ich würde gern erfahren, an was du arbeitest. Hinterlasse einen Kommentar oder kontaktiere mich online.
- GitHub: elizabethsiegle
- Twitter: @lizziepika
- E-Mail: lsiegle@twilio.com



Ähnliche Ressourcen
Twilio Docs
Von APIs über SDKs bis hin zu Beispiel-Apps
API-Referenzdokumentation, SDKs, Hilfsbibliotheken, Schnellstarts und Tutorials für Ihre Sprache und Plattform.
Ressourcen-Center
Die neuesten E-Books, Branchenberichte und Webinare
Lernen Sie von Customer-Engagement-Experten, um Ihre eigene Kommunikation zu verbessern.
Ahoy
Twilios Entwickler-Community-Hub
Best Practices, Codebeispiele und Inspiration zum Aufbau von Kommunikations- und digitalen Interaktionserlebnissen.