Conversation Relay integration for AI agent observability
Legal notice
Conversation Intelligence (classic) is not PCI compliant and must not be enabled in Conversation Relay workflows that are subject to PCI. Conversation Intelligence (classic) for Messaging (Private Beta) isn't a HIPAA Eligible Service and shouldn't be used in workflows that are subject to HIPAA.
Conversation Intelligence (classic) integrates with Conversation Relay to provide built-in support for AI agent observability. This integration lets you analyze AI agent conversations and gain insights into their performance.
Connecting Conversation Relay to Conversation Intelligence (classic) enables the following features:
- Persist Conversation Relay Transcripts: Send the transcript of the interaction between the AI agent and the customer to Conversation Intelligence (classic)'s historical log for future reference and analysis. By default, Conversation Relay transcripts are not stored by Twilio.
- Run Post-Call Language Operators: Trigger configured Language Operators in Conversation Intelligence (classic) to generate AI-powered insights and automate actions after the call has concluded.
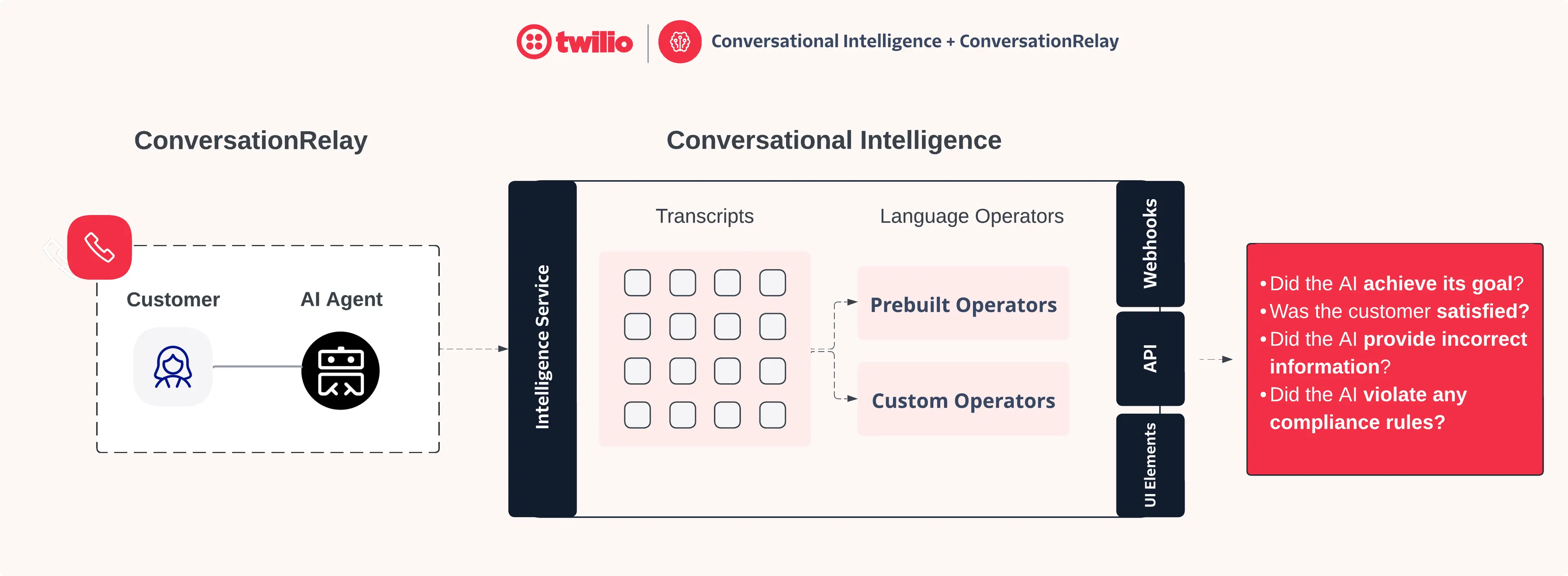
Through the use of Conversation Intelligence (classic) Language Operators, you can implement customized observability for your Twilio AI agents – enabling you to quantitatively measure key quality assurance indicators like:
- Did the AI agent achieve its intended goal?
- Was the customer satisfied with their AI agent interaction?
- Did the AI agent provide factually incorrect information?
- Did the AI agent violate any compliance rules?
This guide assumes that you have already:
- Successfully set up Conversation Relay. For a detailed walkthrough and sample implementation, please see this blog post.
- Created an Intelligence Service.
The following steps guide you through the process of integrating Conversation Relay with Conversation Intelligence (classic) for AI Agent observability.
Analyzing AI agent conversations with Twilio Conversation Intelligence (classic) is as simple as passing a single additional attribute to the <ConversationRelay> TwiML noun. This attribute is called intelligenceService, which specifies the Conversation Intelligence (classic) Service (accepts Service SID or Unique Name) where Twilio should send the transcript:
1<?xml version="1.0" encoding="UTF-8"?>2<Response>3<Connect action="https://myhttpserver.com/connect_action">4<ConversationRelay5url="wss://mywebsocketserver.com/websocket"6welcomeGreeting="Hi! Ask me anything!"7intelligenceService="GAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"8/>9</Connect>10</Response>
The Intelligence Service passed in the intelligenceService attribute must be a valid Service SID or Unique Name, and belong to the same Twilio account as the one originating the Conversation Relay session.
Transcripts become available in Conversation Intelligence (classic) when either of the following two conditions are met:
- After the call has ended
- When you send the Conversation Relay session end message
Conversation Relay sends the transcribed utterances, but not the audio of the call to Conversation Intelligence (classic). The audio isn't available in the Transcripts Viewer or the API.
Note that if PCI mode is enabled for your account, the Conversation Relay transcript will be rejected by Conversation Intelligence (classic) and no Language Operators will run. This is done to avoid PCI compliance violations related to using Conversation Intelligence (classic) which is not a PCI compliant product.
Important note about Language Settings
If the Language set on the Conversation Relay session is different from the Language set on the Intelligence Service, the transcript will be stored but Language Operators will not run. To ensure Language Operators run, make sure that the transcriptionLanguage set on the Conversation Relay session matches the language set on the Intelligence Service.
Relatedly, if the language settings initially match but you switch the language during an active Conversation Relay session, the transcript will be stored, and Conversation Intelligence (classic) will attempt to run Language Operators. However, the Operator results may be inaccurate for multi-language Conversation Relay transcripts.
The intelligenceService attribute is optional. If you do not specify it, the Conversation Relay will not send the transcript to Conversation Intelligence (classic). This attribute does not impact any other functionality of the Conversation Relay AI agent.
Once you have added the intelligenceService attribute to your <ConversationRelay> TwiML, you can confirm that the transcripts are being persisted in Conversation Intelligence (classic) using either the Transcripts Viewer in the Console, or by using the Transcripts API.
In the Console, these transcripts have a Source of Conversation Relay and a Channel set to Voice as shown below:
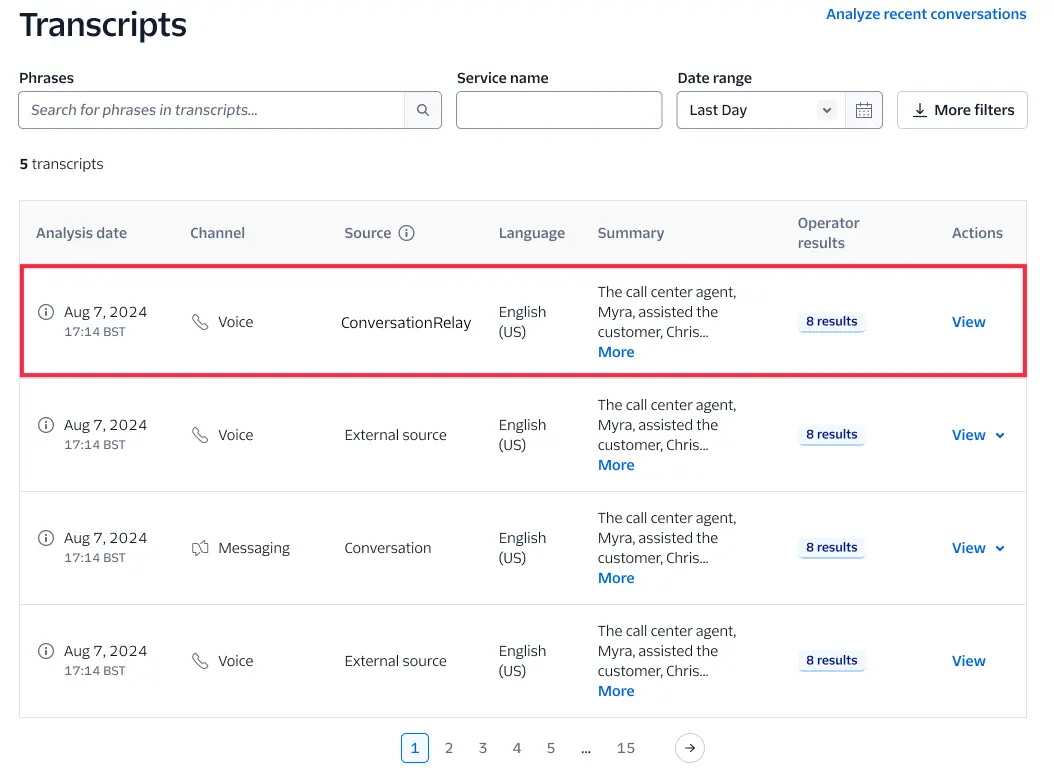
Note that the Console also supports filtering Transcripts by Source (click More filters, check Conversation Relay, then Apply), so you have the ability to narrow down your search to only Conversation Relay transcripts.
When viewing an individual Conversation Relay transcript, you'll notice that Twilio automatically tags the virtual agent as one of the two participants:
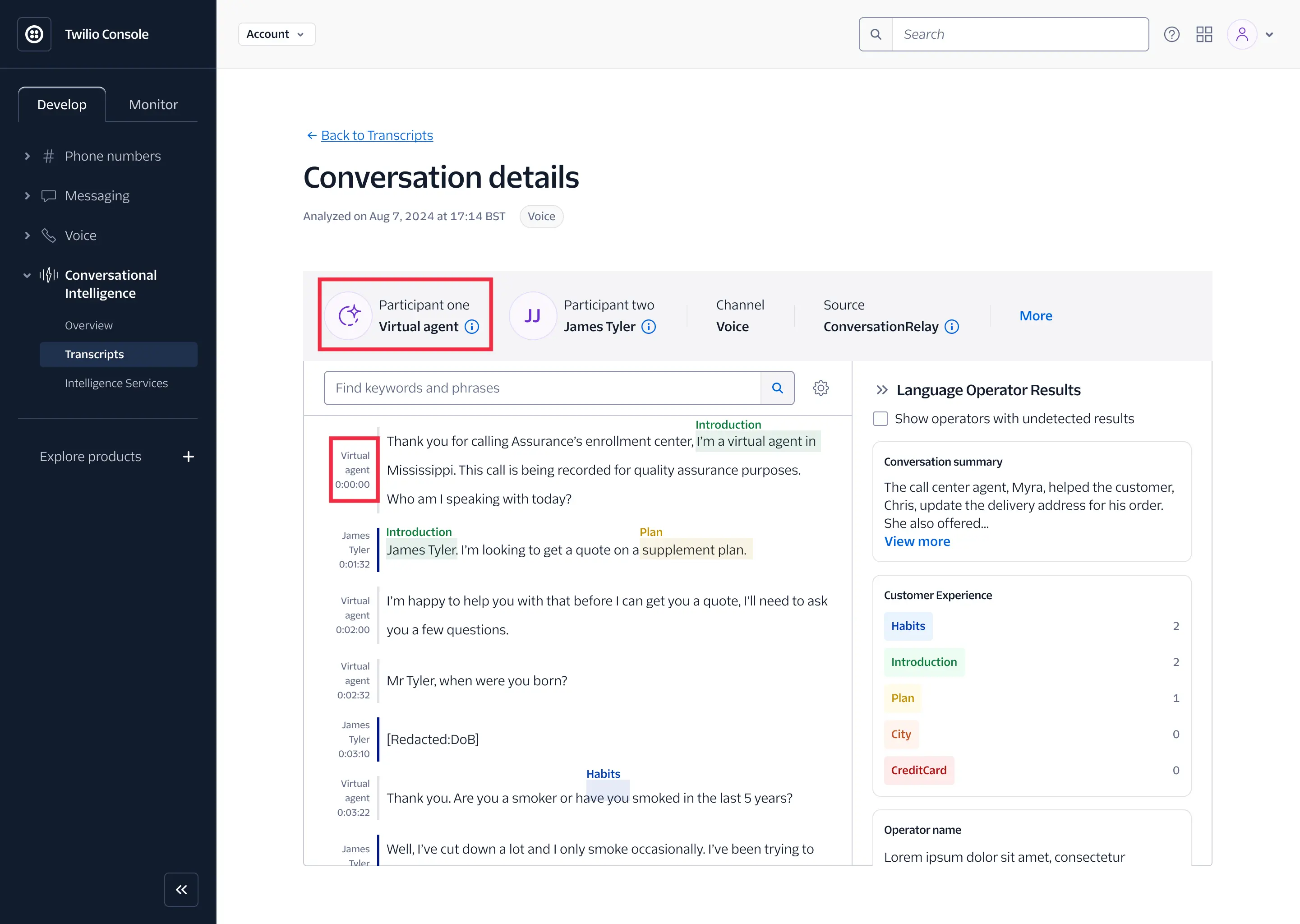
If you're fetching Conversation Relay transcripts via the API, you can see channel.media_properties.source set to ConversationRelay and channel.type set to voice in the Transcripts API response:
1{2...other transcript properties...3"channel": {4"type": "voice",5"media_properties": {6"source": "ConversationRelay",7"source_sid": "VX00000000000000000000000000000000"8}9}10}
Info
For accessing specialized Language Operators for virtual agent observability vetted by Twilio's Machine Learning team, please refer to the Specialized Custom Operators for AI Agents section below.
Language Operators are the main feature of Conversation Intelligence (classic) that allow you to analyze the conversation for AI agent observability and automation purposes. Twilio executes Language Operators upon finalization of the transcript, which occurs when the call ends or when you send the Conversation Relay session end message.
Conversation Intelligence (classic) supports two types of Language Operators:
- Pre-built Operators: Operators maintained by Twilio for common use cases.
- Custom Operators: Operators you create tailored to your business' unique needs.
Both pre-built and custom operators may be useful to you in analyzing Conversation Relay interactions.
You can apply Language Operators to the Conversation Relay transcripts in the same way you would for any other transcript in Conversation Intelligence (classic).
- Navigate to Conversation Intelligence (classic) > Services and select your Service.
- Identify the pre-built Operator you want to use.
- To apply a pre-built Language Operator, click Add to service. A confirmation message appears upon successful addition.

Examples of potentially valuable pre-built Operators for Conversation Relay include:
- Sentiment Analysis: Classifies conversation sentiment as
positive,negative,neutral, ormixed - Summarization: Creates a summary of the conversation
- Agent Introduction: Detects if a participant introduced themselves during the conversation
- Call Transfer: Classifies if the conversation was transferred to another agent
Refer to Pre-built Language Operators for a complete list of available pre-built Operators, supported languages, and more details on their behaviors.
When creating a Custom Operator, choose between Generative and Phrase Matching Operator Types. Use the following table to determine which option best fits your needs:
| Option | Use case | Checks | Sample scenario |
|---|---|---|---|
| Generative (recommended) | Use an LLM to generate text or JSON for sophisticated and flexible natural language understanding tasks | The entire transcript for comprehensive analysis | Score a call based on multiple custom-defined categories of agent performance. |
| Phrase Matching | Detect specific keywords or phrases within a transcript. | Specific segments of the conversation where the phrase might appear. | Identify when a customer mentions a product name or asks a specific question. |
AI agent observability is a unique use case for Language Operators. To help you get started, Twilio's Machine Learning (ML) team created a set of specialized Custom Operator examples designed to help you analyze AI agent conversations and gain insights into their behaviors.
Twilio's ML team vetted each of the following Operators using various ML evaluation techniques to ensure performance and accuracy, so you can be confident that they work well for your needs. Twilio continues to improve these Operators and plans to release them as pre-built Operators.
Info
The Generative Custom Operators below are designed to be used with the Generative Custom Operator Type. You must select Generative when creating the Custom Operator in Console and use the provided configuration Operator configuration instructions below.
For more guidance on how to set up Generative Custom Operators, please refer to the Generative Custom Operators guide.
| Operator Name | Description | Use Case |
|---|---|---|
| Virtual Agent Task Completion | Determines if the virtual agent satisfied the customer's primary request. | Helps measure the efficacy of the virtual agent in serving the needs of customers. Informs future enhancements to virtual agents for cases where customer goals were not met. |
| Human Escalation Request | Detects when a customer asks to be transferred from a virtual agent to a human agent. | Helps measure the efficacy of the virtual agent in achieving self-service containment rates. Useful in conjunction with Task Completion detection above. |
| Hallucination Detection | Detects when an LLM response includes information that is factually incorrect or contradictory. | Ensure the accuracy of information provided to customers. Inform fine-tuning of virtual agent to prevent future instances of hallucination. |
| Toxicity Detection | Flags whether an LLM response contains toxic language, defined as language deemed to inappropriate or harmful. | Determine whether follow-up with customer is necessary, and/or inform adding virtual agent guardrails to prevent future instances of toxicity. Useful in conjunction with Hallucination Detection above. |
| Virtual Agent Predictive CSAT | Derives a customer satisfaction score from 0-5 based on virtual agent interaction. | Measures overall customer satisfaction when engaging with virtual agents. Can serve as a heuristic for a variety of important customer indicators such as brand loyalty, likelihood of repurchase, retention, and churn. |
| Customer Emotion Tagging | Categorize customer sentiment into a variety of identified emotions. | Offers more fine-grained and subtle insight into how customers feel when engaging with virtual agents. |
For each of the preceding Operators, you can find sample prompts, JSON schema, training examples, and example outputs in the following sections. These examples can help you understand how to use the Operators effectively and get the most out of your AI agent observability efforts.
To create a Generative Custom Operator in the Console, follow these steps:
- Navigate to Conversation Intelligence (classic) > Services and select your Service.
- Click Create Custom Operator to be redirected to the Select operator type page.
- Enter an Operator name and select the desired Custom Operator Type: Generative.
- Follow the instructions in the Console to configure your new Custom Operator, pasting in the settings from your chosen Operator below.
- Once created, add the Custom Operator to your Service by clicking Add to service on the Operator page.
The Virtual Agent Task Completion language operator enumerates all tasks requested by the customer and identifies if they were completed. The language operator considers a task to be completed if there is no follow up action required by the customer. This operator can be used to understand what requests are being made to the virtual agent as well as identifying tasks that the virtual agent is not able to handle.
Sample Prompt:
You are an expert call center manager. You have been tasked with analyzing call transcriptions. The transcriptions are of calls between customers and your company's call center support agents. For each transcript, you must identify any task that the customer requests the support agent to perform. For each task report a brief summary describing the task as well as a boolean indicating if the support agent was able to complete it. A task will be considered completed if and only if no additional action is required by the customer. This includes call backs, transfers or any other follow up action. Examples of statements requesting actions are: - I'd like to check my balance - I want to cancel my service - I want to upgrade - I need help with.
Output Format: JSON
JSON Schema:
1{2"type": "object",3"properties": {4"actions": {5"type": "array",6"items": {7"type": "object",8"properties": {9"task_summary": {"type": "string"},10"successful_completion": {"type": "boolean"}11}12}13}14}15}
Sample Result:
1{2"actions": [3{4"task_summary": "Book a double room for August 15th",5"successful_completion": true6},7{8"task_summary": "Book dinner for two at 7 on August 15th",9"successful_completion": true10},11{12"task_summary": "Make a reservation for the Spa on the morning of the 16th",13"successful_completion": false14}15]16}17
The Human Escalation Request language operator detects when a customer indicates they wish to speak to a human. This operator is useful in identifying the proportion of customer calls that the Virtual Agent can handle.
You can combine the results of this operator with the results of the Virtual Agent Task Completion operator. In combination, these operators could identify what proportion of transfers were due to an inability of the Virtual Agent to complete the task, and what proportion are due to a customer's preference to speak with a human.
Sample Prompt:
You are an expert data annotator. You have been tasked with annotating transcripts of voice calls to a customer support center. Specifically, for each transcript you must decide if the customer requested a call escalation. An escalation refers to a customer being transferred or wanting to be transferred from a virtual agent to a human agent member of the customer support center's staff.
Training Examples:
| Example conversation | Example output results |
|---|---|
| I would like to speak to a human | {"escalation": true} |
| I want to speak to someone real | {"escalation": true} |
| Is there a person I can speak to | {"escalation": true} |
| Can you please transfer me to a human call center operative | {"escalation": true} |
| A person I work with recommended the service | {"escalation": false} |
| You are as real as a human | {"escalation": false} |
Output Format: JSON
JSON Schema:
1{2"type": "object",3"properties": {4"escalation": {5"type": "boolean"6}7}8}
Sample Result:
1{2"escalation": true3}
The Hallucination Detection operator detects if any of the Virtual Agent's responses include hallucinations. This operator is useful in detecting if customers are being misled by a Virtual Agent. The operator detects open-domain hallucinations; that is, things that are widely known to be false. However, the operator can be extended with specific knowledge that is relevant to a company. At the end of the sample prompt there is a placeholder where you can provide this additional knowledge. This knowledge could be public or non-public company information. Including important, relevant information in the Hallucination detection prompt will help the generative AI to identify misleading responses from the Virtual Agent. As a concrete example, a product company may want to include its returns policy in the prompt.
Sample Prompt:
You are an expert fact checker. Your job is to analyze text to determine if there are factual inaccuracies or contradictions. When determining if text contains factual inaccuracies or contradictions, provide responses to the following. 1. Does any part of the text contradict itself? 2. Does the text contradict anything contained in the provided knowledge? For each of the above questions, your response should be limited to either 'yes' or 'no'. The provided knowledge for this task includes: <add any public or non-public company information relevant to tasks the Virtual Agent is trying to complete to enhance hallucination detection.>
Output Format: JSON
JSON Schema:
1{2"type": "object",3"properties": {4"correct": {5"type": "string"6},7"provided_knowledge_conflict": {8"type": "string"9}10}11}12
Sample Result:
1{2"correct": "no",3"provided_knowledge_conflict": "yes"4}
The Toxicity Detection language operator detects if any toxic language is used in a transcript. This operator is useful in identifying when the Virtual Agent or customer is using toxic language. You can use the results of this operator to inform updates or modifications to the Virtual Agent.
Sample Prompt:
You are an expert content moderator. You have been tasked with moderating samples of text content. Specifically, you must identify if a sample of text contains toxic content. A sample of text is considered to be toxic if it is inappropriate, harmful, contains threats, insights hate, includes foul language or is derogatory. You should label each sample with a boolean. True indicates the sample included toxicity. False indicates the sample did not include toxicity.
Output Format: JSON
JSON Schema:
1{2"type": "object",3"properties": {"toxic": {"type": "boolean"}}4}5
Sample Result:
1{2"toxic": false3}
The Virtual Agent Predictive CSAT operator applies a customer satisfaction score to a call transcript. The operator scores transcripts based on three separate measures.
- Speed of resolution,
- Completeness of resolution,
- Overall sentiment of the customer.
For each measure the operator will provide a score on a scale from 1 to 5. In all cases, 1 represents the worst experience, and 5 indicates the best. These scores can be used individually or combined via an average or weighted average to give an overall CSAT score.
Sample Prompt:
You are an expert call center manager. You have been tasked with reviewing call transcripts and assigning customer satisfaction scores to them. Specifically, you will score each transcript for three different measures. 1. speed of resolution, 2. completeness of resolution, 3. overall sentiment of the customer. Each measure should be assigned a score between 1 and 5. When scoring speed of resolution you should assign a score of 1 if resolving a customer request requires more than 3 additional questions to the customer. You should assign a score of 5 if resolving a customer request does not require additional information or requires at most 1 follow up question for an agent. You may assign a 2, 3, or 4 for scenarios that fall between these two extremes. When scoring completeness of resolution you should assign a score of 1 if none of the customer requests were resolved. You should assign a score of 5 if all of the customer requests were resolved. You may assign a value of 2, 3 or 4 for scenarios that fall between these two extremes. When scoring overall sentiment you should assign a score of 5 if the customer has a very positive sentiment, a score of 4 if they have a positive sentiment, a score of 3 if their sentiment is neutral, a score of 2 if they have a negative sentiment and a score of 1 if they have a very negative sentiment. Also produce an average score by calculating the average of the speed of resolution, the completeness of resolution and the overall sentiment of the customer.
Output Format: JSON
JSON Schema:
1{2"type": "object",3"properties": {4"speed_of_resolution": {"type": "number"},5"completeness_of_resolution": {"type": "number"},6"overall_sentiment": {"type": "number"},7"average_score": {"type": "number"}8}9}
Sample Result:
1{2"speed_of_resolution": 3,3"completeness_of_resolution": 5,4"overall_sentiment": 4,5"average_score": 46}
The Customer Emotion Tagging operator identifies emotions in a customer call transcript. This operator is useful for understanding the emotions customers feel during a call with the Virtual Agent. This information can be combined with Sentiment Analysis to give a more fine-grained understanding of positive or negative sentiment.
The set of emotions used in the sample prompt correspond to the so-called "Ekman" emotions. The prompt can be tailored to use a different set of emotions. However, the best results will be achieved if the set of emotions has low cardinality and contains distinct emotions that are clearly defined.
When the emotion set's cardinality is too high, the generative AI that supports the operator is more likely to hallucinate. It also leads to higher levels of false positives and false negatives. Additionally, if emotions within the set are distinct and clearly defined, the generative AI is better able to identify the correct emotion. As a concrete example, an emotion set with both "happiness" and "joy" may lead the generative AI to confuse the two.
Sample Prompt:
You are an expert moderator of conversations. You are tasked with identifying any emotions present in a piece of text. For each sample of user provided text, return all the emotion labels that you believe apply. The list of emotion labels includes: Happiness, Sadness, Anger, Fear, Disgust, and Surprise. The list of emotions along with their corresponding definitions are: Happiness: A feeling of well-being and pleasure. Sadness: A feeling of sorrow or unhappiness. Anger: A strong feeling of displeasure and hostility. Fear: A feeling of apprehension or dread in response to danger. Disgust: A feeling of strong disapproval or aversion. Surprise: A feeling of astonishment or unexpectedness.
| Example conversation | Example output results |
|---|---|
| This isn't good enough | {"emotions": ["anger"]} |
| This has been a great experience | {"emotions": ["happiness"]} |
| I wasn't aware of this | {"emotions": ["surprise"]} |
Output Format: JSON
JSON Schema:
1{2"type": "object",3"properties": {4"emotions": {5"type": "array",6"items": {7"type": "string"8}9}10}11}12
Sample Result:
1{2"emotions": ["anger", "surprise"]3}
While this integration supports using these products together, usage of Conversation Relay and Conversation Intelligence (classic) are billed separately.
- Conversation Relay is billed per-minute of active AI agent session time.
- Real-Time Transcription is already included in the per-minute cost of Conversation Relay.
- Customers using this integration will only be incrementally billed for use of Language Operators in Conversation Intelligence (classic). In other words, storing Conversation Relay transcripts in Conversation Intelligence (classic) is provided at no additional cost.
- Language Operators in Conversation Intelligence (classic) are billed per minute or per 1k characters based on the type of Operator used.
As a specific example, let's say you have a Conversation Relay session that lasts 5 minutes and you run the prebuilt summarization Language Operator. Using the standard pricing shown below, your cost for this conversation would be:
- Conversation Relay minutes: $.07 per minute * 5 minutes = $0.35
- Conversation Intelligence (classic) Language Operators: $0.0035 / min * 5 minutes = $0.0175
- Total cost: $0.3675
For up-to-date information on pricing, please refer to the Twilio pricing page.
When using Conversation Relay, you may want to transfer a customer from a virtual agent to a human agent. For the accuracy of conversational analysis, Conversation Intelligence (classic) will isolate the portion of the conversation that occurred between the virtual agent and the customer. This allows you to analyze the interaction without including the human agent's portion of the conversation.
To do this, the first step is to ensure that you have added an action URL to your <Connect> TwiML noun. When an action URL is specified in the <Connect> verb, ConversationRelay will make a request to that URL when the <Connect> verb ends. The request includes call information and session details.
1<?xml version="1.0" encoding="UTF-8"?>2<Response>3<Connect action="https://myhttpserver.com/session_end_action">4<ConversationRelay url="wss://mywebsocketserver.com/websocket" intelligenceService="GAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" />5</Connect>6</Response>
Then, when ready to make the transfer, send the Conversation Relay session end message to the Conversation Relay Websocket:
1{2"type": "end",3"handoffData": "{\"reasonCode\":\"live-agent-handoff\", \"reason\": \"The caller wants to talk to a real person\"}"4}
Note that the contents of handoffData is an example for the purposes of this guide. You can choose to set the contents of this to whatever works best for your use case.
At this time, the virtual agent transcript will be finalized and sent to Conversation Intelligence (classic). Language Operators will be executed on this portion of the call transcript – isolated to the virtual agent interaction – and made available in the Transcripts Viewer and API.
To initiate the transfer, you can check the reasonCode in the HandoffData object in the action handler request. If the reasonCode is live-agent-handoff, you can proceed with the transfer to a human agent.
If you'd like to also record the human agent leg of the call, you can do so by initiating a real-time transcription session connected to an Intelligence Service alongside the human agent leg of the call. This will allow you to analyze the human agent's portion of the conversation in addition to the virtual agent's portion. Example pseudocode for a Node.js Express server:
1const express = require('express');2const { VoiceResponse } = require('twilio').twiml;34const app = express();5// Middleware to parse JSON body6app.use(express.json());78app.post('/session_end_action', (request, response) => {9const handoffData = JSON.parse(request.body.HandoffData);1011if (handoffData.reasonCode === "live-agent-handoff") {12const twiml = new VoiceResponse();13// Start real-time transcription14const start = twiml.start();15start.transcription({16intelligenceService: 'GAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa'17});18// Then dial the human agent19twiml.dial().client('bob_the_agent');2021// Set correct HTTP headers and send TwiML22response.type('text/xml');23response.send(twiml.toString());24} else {25// Handle other cases if needed26response.status(400).send('Invalid handoff reason');27}28});29// Start server (example: localhost:3000)30app.listen(3000);
The net result is that you will have two separate transcripts and Operator results in Conversation Intelligence (classic): one for the virtual agent and one for the human agent. You can then analyze both transcripts separately or together, depending on your needs. If you'd like to run separate Language Operators on the human agent leg of the call, you can do so by passing a different intelligenceService in the <ConversationRelay> TwiML noun.