Building a Real-time SMS Voting App Part 3: Scaling Node.js and CouchDB
Time to read:
January 16, 2013
Written by
This post is part of Twilio’s archive and may contain outdated information. We’re always building something new, so be sure to check out our latest posts for the most up-to-date insights.


This tutorial uses the Twilio Node.JS Module and the Twilio Rest Message API
This is the third in a multi-part series of blog posts on building a real-time SMS and voice voting application using Node.js. In part one, we created the Node.js application and captured incoming votes over SMS. In part two, we created a real-time visualization of the voting using Socket.io. In this blog post, we will discuss tweaking our app to scale to thousands of votes per second and millions of total votes.
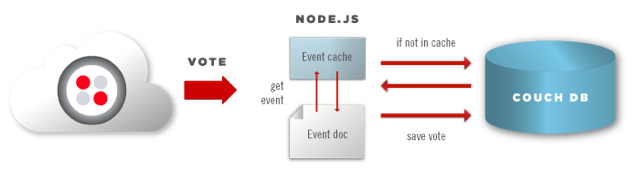
At the end of part two of this blog post series, I mentioned that while we had a working SMS voting app with a cool real-time visualization, it was not a solution that was going to scale. The reason for this was because of how I chose to structure and retrieve my data. My database consisted entirely of event documents that looked like this:
You’ll notice that information about the event (it’s name, etc) and all of the votes for that event are contained within the same document. This means that every time we want to record a new vote, we need to update this document. The workflow looks like this:

If many votes arrived rapidly, our app as currently written will quickly fail. There are several reason for this, but one is that Node.js does not block during I/O. We will end up saturating our DB with concurrent reads and writes, conflicts will arise and votes will be lost. In addition, an array of phone numbers is nested inside of each voteoption object. When there are millions of votes, that is quite a lot of data to send across the wire and process in our app. So, what can we do?
Well, one solution is to decouple event data from vote data. That way when votes come in, we’re simply writing them to the DB as individual documents. We can then use the power of CouchDB map and reduce view functions to query the data that our application needs. In addition to this we will look into:
- Using CouchDB’s range queries to fetch the de-coupled information on an event and its votes
- Using CouchDB’s _id mechanism to ensure against people voting more than once
- Using a reduce function to rapidly calculate the count of a vote
- Implementing simple caches and a flush mechanism using CouchDB’s bulk operations
Modeling one-to-many relationships
In a SQL database, modelling one-to-many relationships is trivial. You define a foreign key in the child record that points to the parent record. One of the pitfalls for people coming from RDBMS is to apply this strategy to NoSQL. In CouchDB, there are many ways to model this relationship and it depends on how you application works. In our case we are going to place use separate documents for the children. See below for a denormalized version of the document I showed you at the top of this blog post:
I’ll go ahead and note a few things that have changed in how we’re storing data:
- We have added a type attribute. Documents are either of type event or vote.
- We are using the type and shortname to create an _id value for events. This makes queries easier and helps with debugging.
- We are using the type, event_id and phonenumber to create an _id value for votes. This will guarantee that a given phone number can only have one vote per event.
- Each vote document has a reference to its parent event document in event_id
- I’ve removed the votes counter from the voteoptions object. We can use CouchDB to generate that information for us on-demand.
Now that we’ve denormalized our data, we need to think about how we’re going to insert vote documents as the votes come in.
More about map functions and queries
In part one, I briefly glossed over some map functions that we defined to help us look-up events. Let’s look at the old map function for the event/all view:
What’s going on here? Well, CouchDB runs every single document in our database through this function. In this case, if the document has a “name” attribute, call emit. Think of emit like a return statement that sends back a key/value pair. Once the map function has run on every document, we now have a list of key/value pairs. In this case, the key is the name and the value is the document itself [1].
The key is important. You can call the view without any parameters and get back the full list:
I’ll take a timeout here to slow clap CouchDB’s RESTful API design. It’s awesome that I can access my data and test my views from the command line. CouchDB also has some powerful query capabilities. You can pass a key parameter to CouchDB in order to limit the response to that key:
You can also query across a range of keys by specifying start and end keys:
This will get all view rows starting with foo and ending with bar [2] . Your view rows are pre-sorted on the key for you, so range queries into that sorted list are really powerful. Now that we’ve chosen to de-normalize our data, we need to tweak our map functions to deal with both event and vote documents. Here’s what the new map function looks like in the event/all view:
The trick is that they key [“A”] sorts before the key [“A”, “1”], which is incredibly important. Next, we use the event_id in vote so our view map will look like:

Then, in a single range query, you get the information for an event and all associated vote data:
Two things to note from this. The -g option tells curl not to glob, so you don’t have to dereference the brackets, etc, in your URL. Handy. Second, the empty set {} sorts last in the view collation rules, so that’s a really common trick. This will allow you to access all votes associated with an event:

In the example above, we have almost a million votes for event A. If we’re just trying to build the event view page, all we really need is the information for the event and the count of votes per voteoption. Wouldn’t it be cool if CouchDB could do this for us?
Diving into reduce functions
Map Reduce might be one of the most famous algorithms in computer science. It is an algorithm for processing parallelizable problems across huge datasets in a distributed fashion across multiple computers, made most famous by Google’s application of this technique to index the web. We saw above how a map function creates a map of key/value pairs. A reduce function processes all of the results from map and returns the final output.
We can use reduce to collapse the table above and get the total number of votes for each option. First, we need to create a reduce function for our view all. In this case, we will use the built-in _count function:
Now we can call curl with a group_level parameter and get back the counts for each voteoption:
Putting it all together
Holy crap, when do we get back to writing code? Right now! Thanks to our separation of concerns in part one, we’re primarily going to be tweaking our events.js module. Nothing else about our app (routes, views, etc) needs to change much.
Switching from Cradle to Nano
When I first created this app, I used Cradle to access CouchDB. I decided to switch from Cradle to Nano for 3 reasons:
- Nano is very minimalistic. I like being closer to the raw HTTP request.
- Nano is actively maintained.
- Nuno put a dinosaur in his README
We can now replace the multitude of variables in config.js in our old app with something much more elegant:
Initializing nano in events.js is similarly minimal:
Getting the Vote Count per Voteoption
When someone hits the event page ( http://domain/events/foo) we need to fetch information about the event and the number of votes for each voting option. Thanks to our map/reduce above, this is a simple and fast query to CouchDB:
Two-phase Lookups with Phone Number
One of the bummers of denormalization is that CouchDB only has the ability to query views based on a key (or set of keys). Since we don’t include the event’s phone number in the vote doument, there’s no way to query votes for a given event based on the phone number. We must first query the event by phone number, get its _id and then run a query for the full event document:
You’ll notice that the old findBy(attr, value, callback, retries) has been modified slightly to be more flexible and accept arbitrary view names and a parameter list:
Lastly, you’ll notice the line where we reference an eventsCache object. Caching, when used responsibly, is our friend as we’ll see below.
Improving performance with caching and bulk operations
There are two kinds of documents that we’re storing in a DB, so we’ve got two opportunities for improving performance with caching.
Caching Events
Event documents are fetched and are only read, not written to. A view of the events display page will trigger a fetch, as will an incoming vote. It would be lovely to avoid doing an event lookup when inserting a vote, but we need the event_id, which is not something we can derive from the request we get from Twilio. So, when an event is pulled from the DB, we save it into a local cache with a key made up of the view and parameters passed into the findBy function.
Periodically, we want to invalidate this cache. For instance, we might have updated a property for this event in our database, and need this change reflected in our application. We can set-up a job to periodically run to do this:
Caching Votes
Vote documents are only ever written to the DB. In order to avoid hammering our CouchDB with thousands of document inserts per second, CouchDB provides the capability of doing bulk document inserts. All we need to do is collect the vote documents in an array as the votes come in:
Then we can set-up a job to periodically flush this cache:
You might wonder, how long should votes be cached for prior to being flushed to the database? Well, it just depends on your tolerance for losing votes. If you can tolerate losing 30 seconds worth of votes, flush every 30 seconds. If your tolerance is lower, flush more frequently. Of course there are industrial-strength remedies for never losing any votes, but those are outside of the scope of this blog post. Our function to flush votes looks like this:
Wrapping Things Up
That’s a lot to swallow I realize, but let’s review what’s we’ve done to pimp this ride:
- Denormalized event and votes data, allowing us to tweak how we handle persistence
- Used CouchDB’s range queries to fetch information on an event and its votes
- Used CouchDB’s _id mechanism to ensure against people voting more than once
- Used a reduce function to rapidly calculate the state of a vote
- Implemented simple caches and flush votes using CouchDB’s bulk operations
Up Next: From Prototype to SaaS
And that’s it! You can see a live, hosted version of this app here:
http://twilio-votr-part3.jit.su/events/demo
At this point we have an app that you can manually configure to process voting for one or more events that scales quite nicely. The last step is to turn this prototype into a product. In the part four of this series, we will use AngularJS to build an authenticated web interface that anyone can use to set-up their own voting experience.
[1] Returning the entire doc as the value for emit is generally a bad practice, you should instead return just the values that you need. You can pass the include_docs=true parameter to CouchDB to get back the entire document if you need it. In our case the documents were are working with are small, and we generally need all of their values anyway.
[2] You might be wondering about security and how to lock-down data. The short answer is that this is coming in Part 4. The long answer is that CouchDB has built-in security mechanisms that work at the database-level, so each user of our app will have their own database.

Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.