10 Dinge, die du vor der Nutzung von TensorFlow wissen musst
Lesezeit: 7 Minuten
October 14, 2019
Autor:in:

Zwar habe ich an der Uni zwei Wahlfächer zum Thema künstliche Intelligenz (KI) belegt und auch schon zahlreiche Machine Learning-Bibliotheken (ML) verwendet, aber das macht mich keinesfalls zu einer ML-Entwicklerin. Wie viele andere Entwickler auch interessiere ich mich jedoch enorm für ML und TensorFlow, eine beliebte Bibliothek, die beim Thema ML oft zur Sprache kommt. Doch was genau ist das eigentlich?
Was ist TensorFlow?
TensorFlow ist eine Open Source-Bibliothek, die 2015 von Google Brain (jetzt Google AI) veröffentlicht wurde. Sie soll es Entwicklern erleichtern, Deep Learning-Modelle und -Daten zu entwickeln, zu trainieren und allgemein einzusetzen, um verschiedene Arten von Prognosen zu treffen. Man kann damit Aufgaben wie Bildklassifizierung, linguistische Datenverarbeitung (Natural Language Processing, NLP), Musikgenerierung wie in diesem Twilio-Blog-Beitrag und vieles mehr meistern.

Ich habe vor ein paar Wochen begonnen, mit TensorFlow herumzuspielen, und obwohl es Spaß gemacht hat und ich viel gelernt habe, gibt es zehn Dinge, die ich rückblickend gerne vorher gewusst hätte.
10 Dinge, die du vor der Nutzung von TensorFlow wissen musst
1. TensorFlow kann auf viele verschiedene Arten genutzt werden. Beispielsweise unterstützt es eine Vielzahl von Programmiersprachen. Die am weitesten verbreitete ist dabei wohl Python, gefolgt von JavaScript. Darüber hinaus werden Swift, C, Go, Java, Haskell, C#, Go und weitere unterstützt. Dieser Blog-Beitrag umfasst einige kurze Code-Snippets in Python, das du hier mit pip installieren kannst. Achte darauf, Versionsnummer 2.0 zu installieren: ein großer Teil des TensorFlow-Codes im Internet basiert noch auf älteren Versionen.
Darüber hinaus gibt es weitere TensorFlow-Tools, die Machine Learning-basiertes Entwickeln erleichtern. TensorFlow Serving ist ein flexibles Bereitstellungssystem, mit dem Entwickler ihre Machine Learning-Modelle (TensorFlow und andere) nahtlos bereitstellen oder anwenden können, nachdem sie sie trainiert haben. Du könntest beispielsweise eine neue Modellversion implementieren, während TensorFlow Serving die aktuellen Anfragen weiter ordnungsgemäß beendet und dann alle neuen Anfragen mit dem neuen Modell handhabt.

Außerdem gibt es das TensorFlow Lite Deep Learning-Framework für Bereitstellungsmodelle auf Mobilgeräten, eingebetteten Geräten oder IoT-Geräten. Die ML-Modelle werden zunächst auf TensorFlow trainiert und dann in Lite-Modelle konvertiert, die auf diesen Geräten funktionieren. Wenn ich mehr Zeit hätte, würde ich liebend gern herausfinden, welche Möglichkeiten es für den kombinierten Einsatz von TensorFlow Lite und Twilio Programmable Wireless gäbe!

2. Es gibt Unterschiede zwischen den verschiedenen Versionen von TensorFlow. Ein großer Teil des Codes, den man online findet, ist noch TensorFlow 1.x, und 1.x unterscheidet sich stark von der aktuellen Version TensorFlow 2.x. TensorFlow 1.x nutzte Platzhalter, die im Prinzip Variablen entsprechen, aber zunächst nicht mit einem Wert versehen sind. Diesen kann man später hinzufügen. In TensorFlow 2.0 gibt es diese Platzhalter übrigens nicht mehr! In TensorFlow 2.0 ist jedoch der Eager Execution-Modus hinzugekommen, d. h. jeder Knoten wird sofort nach seiner Definition ausgeführt und kann mit tf.eager_execution() aufgerufen werden. Aufgrund dieses Eager Execution-Modus ist TensorFlow nun eine imperative Programmierumgebung („define-by-run“), in der Vorgänge mit Session.run() direkt ausgeführt werden, ohne erst einen Graphen konstruieren zu müssen. Die ausgeführten Rechengraphen werden jetzt nicht mehr zurückgegeben: Die Vorgänge geben tatsächliche Werte zurück, was für dich bedeutet, dass du weniger Codezeilen schreiben musst. Auch das Debugging ist leichter, weil es eine bessere Benutzeroberfläche (UI) und dank der Python-Anweisungen einen natürlicheren Kontrollfluss gibt (statt Kontrollfluss-Graphen).
3. Im Gegensatz zu den meisten APIs nimmt TensorFlow einem nicht so viele der schwierigen Programmierungsaspekte ab. Ich selbst finde, dass APIs wie Twilio und Dad Jokes mir das Leben deutlich erleichtern, weil sie die schwierigsten Aufgaben abdecken und es noch dazu leicht verständliche Dokumentation gibt. TensorFlow übernimmt zwar viele der komplexeren Aspekte beim Trainieren der Machine Learning-Modelle (was nicht einfach ist), aber es ist es dennoch relativ Low-Level und erfordert ein ziemlich gutes Verständnis von Machine Learning. Das bringt uns zu Punkt 4:
4. Man muss sich (ziemlich) gut mit ML auskennen. Stell dir vor, du möchtest die Genauigkeit eines Modells trainieren und bewerten. Der Code sieht dann in etwa so aus (und kann nicht kopiert und eingefügt werden):
Auf deinem Terminal würde das ungefähr so aussehen:
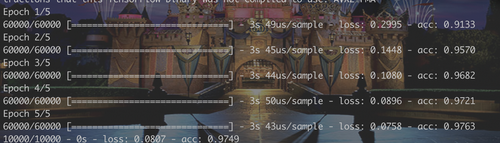
Eine Epoche ist eine vollständige Iteration der Trainingsdaten durch den Machine Learning-Algorithmus. In diesem Zusammenhang benötigt man ein gutes Verständnis folgender Aspekte: die verschiedenen Modelle (sequenziell vs. funktional), Verlustfunktionen (Bewertung, wie gut ein Algorithmus Daten modelliert), Kreuzentropieverlust (eine Verlustfunktion, die einen Ausgabewert zwischen null und eins zurückgibt), Aktivierungsfunktionen für Deep Neural Networks, Padding (die Anzahl der Pixel, die einem Bild hinzugefügt werden, das vom Kernel eines Convolutional Neural Network verarbeitet wird; der Wert kann same oder valid lauten) u. v. m. Kurz gesagt musst du dich bei TensorFlow auf einen Lernprozess einstellen.
5. Wie ist der Name TensorFlow entstanden?
Alle Rechenoperationen in TensorFlow erfolgen mit Tensoren. Dabei handelt es sich um mehrdimensionale Daten-Arrays, in denen bei neuronalen Netzwerken Berechnungen stattfinden. Tensoren umfassen Skalare, Vektoren oder n-dimensionale Matrizen, die alle Arten von Daten darstellen.
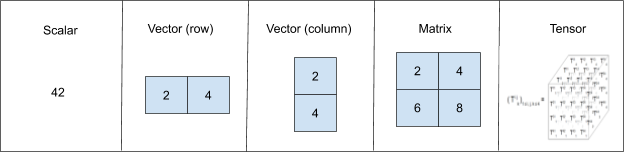
Ein Skalar ist eine einzelne Zahl, die nur durch ihre Größe beschrieben wird. Ein Vektor (sowohl Zeilen- als auch Spaltenvektor) ist ein 1D-Array aus Zahlen, das durch seine Größe und seine Richtung definiert ist. Jedes Element in einem Vektor hat einen bestimmten Index (eine bestimmte Position). Eine Matrix ist ein 2D-Array aus Zahlen, wobei die Zahlen durch zwei Indizes referenziert werden. Ein Tensor ist ein Array mit mehr als zwei Achsen, wird aber auch genutzt, um Skalare, Vektoren und Matrizen zu verallgemeinern oder zu umschließen. Jeder Wert in einem Tensor umfasst identische Datentypen mit einer bekannten oder halb bekannten Abmessung, die der Dimensionalität der Matrix oder des Arrays entspricht. Jeder Tensor ist ein Objekt mit drei Eigenschaften: ein eindeutiger name, eine eindeutige shape und ein eindeutiger dtype. dtype ist in Bibliotheken für wissenschaftliche Berechnungen, z. B. NumPy und Scikit, weit verbreitet. In Punkt 6 lernen wir weitere Tensoren kennen:
6. Konstanten und Variablen in TensorFlow sind anders und zum Teil unnötig kompliziert. In TensorFlow kann man eine Tensorkonstante bzw. einen Knoten mit unveränderlichen Werten erstellen. In Python könnte eine eindimensionale Tensorkonstante wie folgt aussehen:
x ist eine Konstante des Typs 32-Bit-Gleitkommazahl mit einfacher Genauigkeit und y ist eine Array-Konstante. Wenn man diese Konstanten druckt, sieht man, dass die Ausgabe aus einem Objekt des Typs Tensor besteht:

Es gibt zwei Konstanten: die erste ist die Abmessung [] (ein Skalar mit einem Rang-0-Tensor) und die zweite ist die Abmessung[4] (ein Vektor mit einem Rang-1-Tensor.)
|
Rang |
Objekt |
|
0 |
Skalar |
|
1 |
Vektor |
|
2 |
Matrix |
|
≥ 3 |
Tensor |
Man kann auch Berechnungen für Konstanten durchführen, z. B.:
Das Ergebnis:
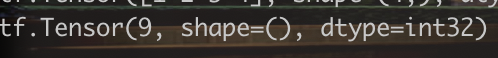
Es ist so unglaublich komplex! Wie handelt TensorFlow andere Typen, z. B. Variablen? Variablen sind Knoten, deren Werte sich ändern können. tf.Variable kann beispielsweise genutzt werden, um den Zustand der Daten für trainierbare Variablen wie Gewichtungen und Verzerrungen zu speichern:
Du kannst auch optionale Parameter wie name (also „a“) und dtype (also „tf.float32“) hinzufügen:
Um den Wert zu drucken, müssten wir alle Variablen initialisieren, bevor die anderen Modellvorgänge ausgeführt werden. Da wir zuerst ein Modell erstellen, müssen wir als Erstes den Initialisierer in der Sitzung ausführen. Mit dem folgenden Code wird die a-Variable sauber initialisiert.
Ich habe ein paar Minuten gebraucht, um zu verstehen, warum der Initialisierer zuerst ausgeführt werden muss, und es ist seltsam, weil er auf verschiedene Arten geschrieben werden kann! (Aber ja, ich weiß, so ist Code nun mal.)
7. Tensoren sind mit 23 Datentypen kompatibel. Diese Datentypen weckten Erinnerungen an einen Uni-Kurs zum Thema diskrete Mathematik: neben Integern mit Vorzeichen (8, 16, 32 und 64 Bit) und ohne Vorzeichen (8 und 16 Bit), Byte-Arrays, Gleitkommazahlen und Boole'schen Werten können Tensoren auch quantisierte Integer (mit und ohne Vorzeichen), Gleitkommazahlen mit halber, einfacher und doppelter Genauigkeit, abgeschnittene Gleitkommazahlen sowie komplexe Zahlen mit einfacher Genauigkeit (64 Bit) und doppelter Genauigkeit (128 Bit) handhaben – um nur einige zu nennen. Ich weiß natürlich die vielfältigen Optionen zu schätzen und verstehe, dass sie bei komplexen Machine Learning-Modellen sehr nützlich sind. Für meine eigenen ML-Projekte und -Anwendungsfälle sind sie allerdings größtenteils überflüssig.
8. Das Sammeln und Vorbereiten der Trainingsdaten kann lästig sein. Stell dir vor, du nimmst eine Bildklassifizierung vor und brauchst eine große Zahl von Bildern, um dein TensorFlow-Modell zu trainieren. In Python könntest du diese zahlreichen Bilder wie folgt sammeln:
Wenn du kein Fotoarchiv zur Hand hast, kannst du über Google Images Download Bilder herunterladen: Das Skript durchsucht Google Bilder und lädt dann basierend auf von dir festgelegten Kriterien wie Stichwort, Bildformat u. Ä. Bilder herunter. Wenn du jeweils mehr als 100 Bilder gleichzeitig herunterladen möchtest (was empfohlen wird, damit ausreichend Trainingsdaten für die Bilderkennung zur Verfügung stehen), musst du wahrscheinlich auch ChromeDriver herunterladen, um einen Befehl wie den folgenden auszuführen (je nachdem, wo du ChromeDriver speicherst):
googleimagesdownload --keywords 'panda' --limit 200 --size medium \
--chromedriver ./chromedriver --format png
Als ob das nicht schon genug Aufwand wäre, hat jedes Bild einen anderen Namen! Du solltest als Nächstes jedes Bild mit einer Nummer versehen, bevor du die Bilder manuell beschriftest. labelImg ist eines der Tools, mit dem du große Bilddatensätze mit Beschriftungen versehen kannst.

Die Beschriftungsdateien (.xml) werden damit im Pascal VOC-Format gespeichert. Dieses XML-Dateiformat wird von ImageNet, einer beliebten Bilddatenbank, dazu genutzt, das Bilderkennungssystem in ML zu trainieren.
9. Es gibt ein paar Alternativen zu TensorFlow. Eine relativ weit verbreitete Alternative ist PyTorch, ein von Facebook entwickeltes Deep Learning-Framework. PyTorch basiert auf der Torch-Bibliothek für wissenschaftliche Berechnungen und ist für C++ mit Python und C++ Front-Ends konzipiert. PyTorch ist „Python-artiger“ als TensorFlow und erleichtert Entwicklern das Erstellen von Deep Neural Networks. TensorFlow bietet statische Graphen und die Möglichkeit dynamischer Modelle mit Eager Execution, während es bei PyTorch dynamische Rechengraphen gibt, die während der Laufzeit angepasst werden können. Eine weitere Alternative ist Keras, eine in Python geschriebene komplexere neuronale Netzwerk-API, die jetzt Teil von TensorFlow ist. Sie basiert auf Python und ist somit benutzerfreundlicher (der Kern von TensorFlow ist in stark optimiertem C++ geschrieben). Da Keras jedoch keine eigenständige Bibliothek ist, wäre ein Vergleich mit TensorFlow unfair.

10. Es gibt so viele verschiedene Anwendungsfälle für TensorFlow. Man kann es für Stimmerkennung, Sentimentanalyse, Spracherkennung, Textzusammenfassung, Bilderkennung, Videoerkennung, Zeitreihenanalyse und vieles mehr nutzen. Grenzenlose Möglichkeiten!
Trotz einiger Komplexität bietet TensorFlow überzeugende Unterstützung für GPU und verschiedene Hardware/Betriebssysteme. Dank des flexiblen und modularen Designs kann man mühelos mit großen Datenmengen oder verschiedenen Sprachen arbeiten (oder Modelle mit TensorFlow.js im Browser trainieren und ausführen!) oder Modelle mit wenigen Code-Anpassungen auf CPU-, GPU- oder TPU-Prozessoren verschieben. Zudem kann man nicht nur Machine Learning- und Deep Learning-Algorithmen, sondern auch statistische und allgemeine Rechenmodelle ausführen. Abschließend sollte noch erwähnt werden, dass es tolle Unterstützung aus der Community gibt. Und da Google hinter TensorFlow steht, wird es fortlaufend verbessert (die häufigen Veränderungen haben Vor- und Nachteile).
Fazit
Nachdem ich an der Uni zwei Wahlfächer zum Thema künstliche Intelligenz (KI) belegt hatte, sah ich mich als ML-Fan. Nachdem ich TensorFlow nun verwendet habe, fühle ich mich eher wie eine ML-Entwicklerin. Wie sieht es bei dir aus? Weitere Twilio-Blog-Beiträge zum Thema TensorFlow sind geplant. Bis dahin kannst du mir gerne in den Kommentaren oder online berichten, was du mit TensorFlow entwickelt hast.
GitHub: elizabethsiegle
Twitter: @lizziepika
E-Mail: lsiegle@twilio.com


Ähnliche Ressourcen
Twilio Docs
Von APIs über SDKs bis hin zu Beispiel-Apps
API-Referenzdokumentation, SDKs, Hilfsbibliotheken, Schnellstarts und Tutorials für Ihre Sprache und Plattform.
Ressourcen-Center
Die neuesten E-Books, Branchenberichte und Webinare
Lernen Sie von Customer-Engagement-Experten, um Ihre eigene Kommunikation zu verbessern.
Ahoy
Twilios Entwickler-Community-Hub
Best Practices, Codebeispiele und Inspiration zum Aufbau von Kommunikations- und digitalen Interaktionserlebnissen.