Answering Machine Detection
Learn to identify if a human or machine answers your calls by using Twilio Answering Machine Detection (AMD) to specify the MachineDetection parameter in a POST request. You can use this guide to send voice notifications, create outbound contact centers, build AI agents, and develop sales dialers.
See Related reference documentation to learn more about the API parameters and webhooks used in this guide.
Warning
While Async AMD (AsyncAmd=true) is analyzing a call, it consumes one forked audio stream from the per-call limit of four forked streams. Synchronous AMD (the default) does not use forked streams.
The fork limit is shared with the following features: Media Streams, SIPREC, and Real-Time Transcription. If you plan to use any of these features on the same call, start them only after Async AMD finishes, as indicated by the AsyncAmdStatusCallback. This approach prevents you from exceeding the limit.
For a full breakdown, see Forked Audio Streams.
As a developer integrating AMD into your application, you can use AMD with calls you placed through the Calls API, Participants API, <Dial><Number>, or through <Dial><Sip>.
The following AMD parameters as well as Optional tuning parameters can be specified on the requests.
| Parameter Name | Allowed Values | Default Value |
|---|---|---|
| MachineDetection | Enable or DetectMessageEnd | none |
| AsyncAmd | true or false | false |
| AsyncAmdStatusCallbackMethod | POST | POST |
| AsyncAmdStatusCallback | Absolute or relative URL | none |
Use Enable if you would like Twilio to return an AnsweredBy value as soon as it identifies the called party. This is useful if you would like to take a specific action — for example, connect to an agent, or leave a message in voicemail with <Say> and Text-To-Speech capabilities — for a human but hang up on a machine.
If you would like to leave a voicemail on an answering machine, specify DetectMessageEnd. In this case, Twilio will return an AnsweredBy immediately when a human is detected but for an answering machine, AnsweredBy is returned only once the end of the greeting is reached, usually indicated by a beep.
Select whether to detect an answering machine in the background.
- When you set
AsyncAmdtotrue, the call continues. The AMD service determines if an answering machine exists in the background. - When you set
AsyncAmdtofalse(the default), Twilio blocks the call. The call resumes when the AMD service completes answering machine detection.
The HTTP method that we should use to send the results of the AMD.
The absolute or relative URL that we should call using the AsyncAmdStatusCallbackMethod to notify whether the call was answered by a human, machine, or fax. When AMD makes a decision, Twilio will make a request to this URL with the following parameters:
| Parameter | Description |
|---|---|
| CallSid | A unique identifier for this call, generated by Twilio |
| AccountSid | Your Twilio account ID. It is 34 characters long, and always starts with the letters AC |
| AnsweredBy | The result of answering machine detection. If Enable was specified, results can be: machine_start, human, fax, unknown. If DetectMessageEnd was specified, results can be: machine_end_beep, machine_end_silence, machine_end_other, human, fax, unknown |
| MachineDetectionDuration | Time in milliseconds that AMD took to reach a verdict |
AMD uses an algorithm that isolates human speech audio and measures periods between speech and silence in the greeting, and then uses this data to determine the answering party. Since not all humans and not all voicemail greetings follow similar patterns in answering calls, it's possible that AMD will not always return the right answer. The AMD engine may, for example, interpret a very short two-second voicemail greeting as a human picking up.
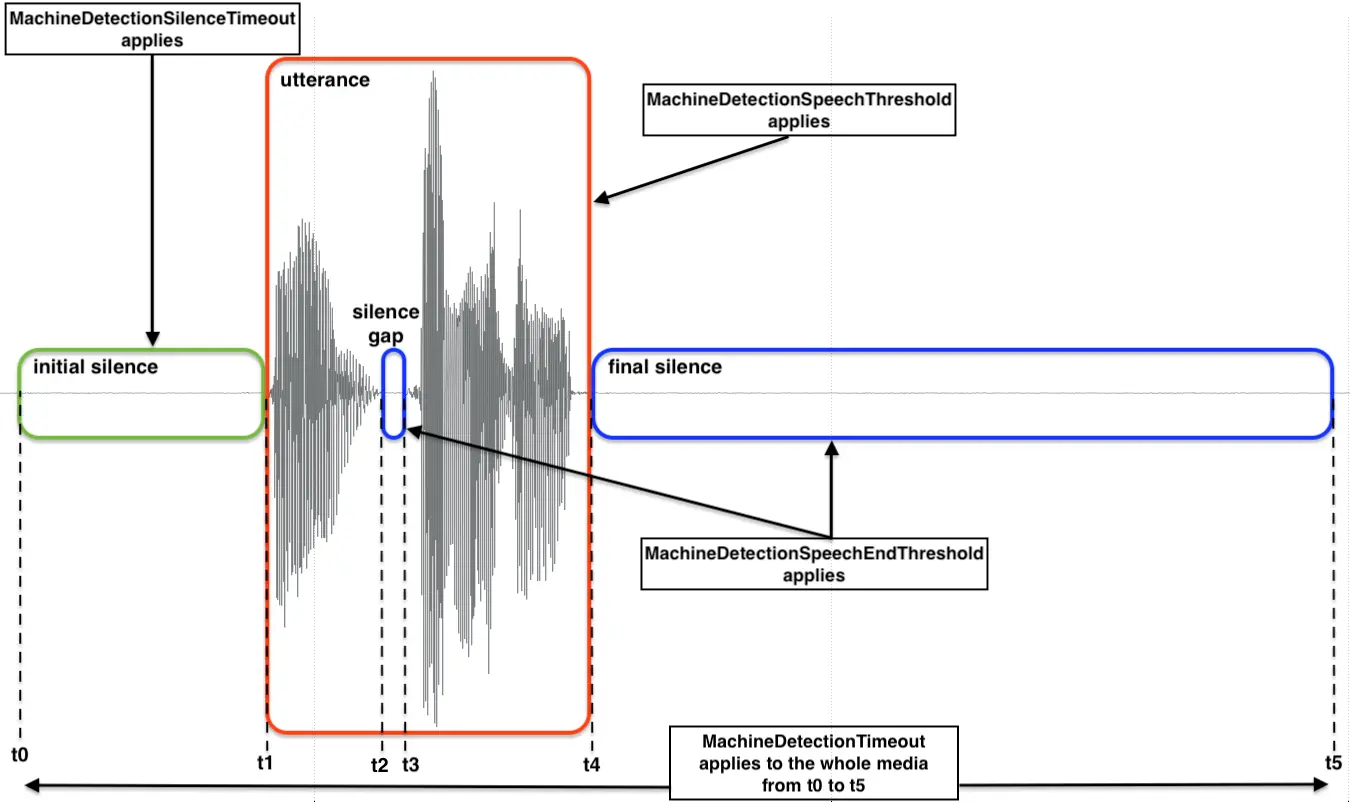
There are four optional parameters that allow customers to tune the performance of the AMD engine, the diagram below illustrates how each property relates to media utterances:
| Parameter Name | Allowed Values | Default Value |
|---|---|---|
| MachineDetectionTimeout | Between 3 and 59 | 30 |
| MachineDetectionSpeechThreshold | Between 1000 and 6000 | 2400 |
| MachineDetectionSpeechEndThreshold | Between 500 and 5000 | 1200 |
| MachineDetectionSilenceTimeout | Between 2000 and 10000 | 5000 |
The number of seconds that Twilio should attempt to perform answering machine detection before timing out. If MachineDetectionTimeout is reached, AnsweredBy will return unknown.
Increasing this value will provide the engine more time to make a determination. For example, you may increase the default value when MachineDetection=DetectMessageEnd and there is an expectation of long answering machine greetings that can exceed 30 seconds.
Decreasing this value will reduce the amount of time the engine has to make a determination. For example, you may decrease the default value when MachineDetection=Enabled if you have time constraints for taking an action based on answering machine detection determination, hence you prioritize a (best effort) quick response of human/machine or Unknown result. However, not giving enough time will result in more unknown results.
Note that when MachineDetection=DetectMessageEnd, setting low values for MachineDetectionTimeout may return unknown result even if a machine answered the call and the engine would be able to determine so, because the timeout was triggered without waiting until the end of machine greeting, which instead would have returned machine_end_beep, machine_end_silence, or machine_end_other.
The number of milliseconds that is used as the measuring stick for the length of the speech activity. Durations lower than this value may be interpreted as a human, longer as a machine.
Increasing this value will reduce the chance of a False Machine (detected machine, actually human) for a long human greeting (e.g., a business greeting) but increase the time it takes to detect a machine.
Decreasing this value may reduce the chances of a False Human (detected human, actually machine) for short voicemail greetings. For example, the value of this parameter may need to be reduced by more than 1000 ms to detect very short voicemail greetings. However, a reduction of that significance can result in increased False Machine detections and adjusting the MachineDetectionSpeechEndThreshold is likely the better approach for short voicemails.
The number of milliseconds of silence after speech activity at which point the speech activity is considered complete.
Increasing this value is typically used to better address the short voicemail greeting scenarios. For short voicemails, there is typically 1000-2000 ms of audio followed by 1200-2400 ms of silence and then additional audio before the beep. Increasing the MachineDetectionSpeechEndThreshold to ~2500 ms will treat the 1200-2400 ms of silence as a gap in the greeting but not the end of the greeting and will result in a machine detection. The downsides of such a change include:
- Increasing the delay for human detection by the amount you increase this parameter, e.g., a change of 1200 ms to 2500 ms increases human detection delay by 1300ms.
- Cases where a human has two utterances separated by a period of silence (e.g. a "Hello", then 2000 ms of silence, and another "Hello") may be interpreted as a machine.
Decreasing this value will result in faster human detection. The consequence is that it can lead to increased False Human (detected human, actually machine) detections because a silence gap in a voicemail greeting (not necessarily just in short voicemail scenarios) can be incorrectly interpreted as the end of speech.
The number of milliseconds of initial silence after which an unknown AnsweredBy result will be returned.
Increasing this value will result in waiting for a longer period of initial silence before returning an unknown AMD result.
Decreasing this value will result in waiting for a shorter period of initial silence before returning an unknown AMD result.
To initiate an outbound call with AMD turned on and receive the detection result before your TwiML executes, make a POST request with MachineDetection set to Enable:
1// Download the helper library from https://www.twilio.com/docs/node/install2const twilio = require("twilio"); // Or, for ESM: import twilio from "twilio";34// Find your Account SID and Auth Token at twilio.com/console5// and set the environment variables. See http://twil.io/secure6const accountSid = process.env.TWILIO_ACCOUNT_SID;7const authToken = process.env.TWILIO_AUTH_TOKEN;8const client = twilio(accountSid, authToken);910async function createCall() {11const call = await client.calls.create({12from: "+18180000000",13machineDetection: "Enable",14to: "+1562300000",15url: "https://handler.twilio.com/twiml/EH8ccdbd7f0b8fe34357da8ce87ebe5a16",16});1718console.log(call.sid);19}2021createCall();
Response
1{2"account_sid": "ACXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",3"answered_by": null,4"api_version": "2010-04-01",5"caller_name": null,6"date_created": "Tue, 31 Aug 2010 20:36:28 +0000",7"date_updated": "Tue, 31 Aug 2010 20:36:44 +0000",8"direction": "inbound",9"duration": "15",10"end_time": "Tue, 31 Aug 2010 20:36:44 +0000",11"forwarded_from": "+141586753093",12"from": "+18180000000",13"from_formatted": "(415) 867-5308",14"group_sid": null,15"parent_call_sid": null,16"phone_number_sid": "PNaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa",17"price": "-0.03000",18"price_unit": "USD",19"sid": "CAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa",20"start_time": "Tue, 31 Aug 2010 20:36:29 +0000",21"status": "completed",22"subresource_uris": {23"notifications": "/2010-04-01/Accounts/ACaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Calls/CAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Notifications.json",24"recordings": "/2010-04-01/Accounts/ACaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Calls/CAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Recordings.json",25"payments": "/2010-04-01/Accounts/ACaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Calls/CAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Payments.json",26"events": "/2010-04-01/Accounts/ACaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Calls/CAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Events.json",27"siprec": "/2010-04-01/Accounts/ACaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Calls/CAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Siprec.json",28"streams": "/2010-04-01/Accounts/ACaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Calls/CAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Streams.json",29"transcriptions": "/2010-04-01/Accounts/ACaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Calls/CAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Transcriptions.json",30"user_defined_message_subscriptions": "/2010-04-01/Accounts/ACaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Calls/CAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/UserDefinedMessageSubscriptions.json",31"user_defined_messages": "/2010-04-01/Accounts/ACaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Calls/CAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/UserDefinedMessages.json"32},33"to": "+1562300000",34"to_formatted": "(415) 867-5309",35"trunk_sid": null,36"uri": "/2010-04-01/Accounts/ACaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/Calls/CAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa.json",37"queue_time": "1000"38}
AMD results are returned in the AnsweredBy parameter of the webhook issued to the URL you provide in the outbound call request.
| Parameter | Description |
|---|---|
| AnsweredBy | The result of answering machine detection.If Enable was specified, results can be:machine_start, human, fax, unknown.If DetectMessageEnd was specified, results can be: machine_end_beep, machine_end_silence, machine_end_other, human, fax, unknown. |
Warning
When you don't use AsyncAmd, your API call can use one of two parameters to send instructions. You can include instructions in either the url or twiml parameters. Using either parameter, Twilio awaits a decision from the AMD service. The next action depends on the parameter your API call uses to pass instructions.
If your API call uses in the url parameter, Twilio sends a webhook to the URL with the decision.
If your API call uses in the twiml parameter, Twilio executes the instructions.
See also: Answering Machine Detection FAQ and best practices
The life cycle of a call using AMD is shown below. The user experience of a recipient of a call using AMD is impacted if there is a delay from the time they pick up the phone to the first packet of audio they hear. Twilio has optimized our AMD system to quickly classify calls, but it's also important that you optimize your application to respond quickly.
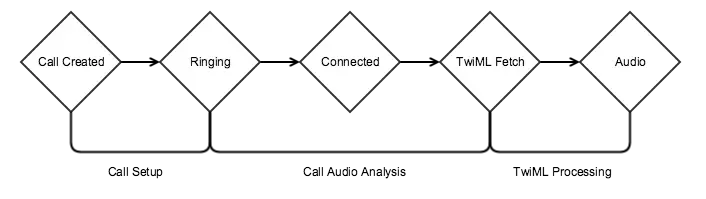
To minimize delay, ensure that you benchmark your application to ensure that webhooks from Twilio are processed and responded to in a timely manner. In test applications running in EC2, we can get this time under 150 ms. TwiML served from TwiMLBins typically comes in under 100 ms.
If you are using <Play> verbs, we recommend hosting your media in AWS S3 in us-east-1, eu-west-1, or ap-southeast-2 depending on which Twilio Region you are using. No matter where you host your media files, always ensure that you're setting appropriate Cache Control headers. Twilio uses a caching proxy in its webhook pipeline and will cache media files that have cache headers. Serving media out of Twilio's cache can take 10ms or less. Keep in mind that we run a fleet of caching proxies so it may take multiple requests before all of the proxies have a copy of your file in cache.
Alternatively, you can use <Say> to leave a message with Text-To-Speech capabilities which provides more flexibility with low latency, without the overhead of recording, storing, and maintaining the media files.
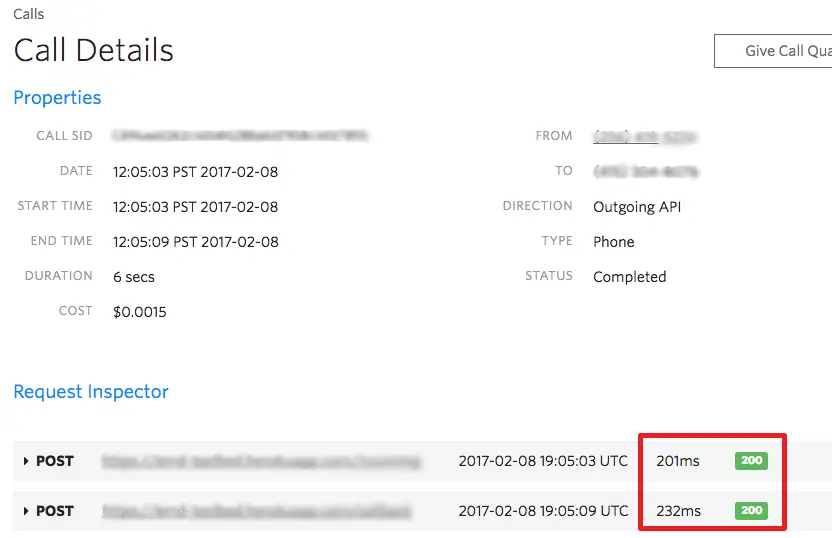
To help you benchmark your server's response time to Twilio, we expose the request duration in milliseconds for every request in the Request Inspector. You can view these clicking into the Call Details page in the Console:
This guide teaches the basics required for the following use cases:
You can use this guide to ensure your automated notifications are delivered appropriately, whether to a live person or a voicemail box. For example, you can detect a human to play a critical alert or detect a machine to leave a recorded message.
To learn more advanced features that you can use with voice notifications, see Voice notifications.
You can use this guide to optimize agent productivity by only connecting agents when a human is detected, filtering out answering machines and busy signals.
To learn more advanced features that you can use with outbound contact centers, see Voice outbound contact center.
You can use this guide to trigger specific AI-driven conversation flows once a human has been identified on the line.
To learn more advanced features that you can use with AI agents, see AI agents.
You can use this guide to power high-volume outbound dialing for sales teams, ensuring reps spend their time talking to prospects rather than listening to voicemail greetings.
To learn more advanced features that you can use with sales dialers, see Voice sales dialer.
After following this guide, you can programmatically detect whether a human, answering machine, or fax machine has picked up your outbound calls. You have also learned how to tune the detection engine for speed or accuracy and how to handle results via asynchronous webhooks.
Explore the following guides to build on what you've learned in this guide:
- Make outbound phone calls with Twilio Programmable Voice: Learn the fundamentals of placing calls before adding detection logic.
- Answering Machine Detection FAQ and best practices: Review common questions and advanced optimization strategies for AMD.
- Modify calls in progress: Change the course of a call dynamically after it has been answered.