Programmable Voice Failover Best Practices
Learn how to configure your communication systems and web applications to handle component failures, carrier outages, and connection disruptions cleanly. Implementing decentralized failover and disaster recovery (DR) strategies reduces downtime and safeguards your application logic during external routing incidents. You can use this guide to create self-service automation, build inbound contact centers, and build outbound contact centers.
See Related reference documentation to learn more about the fallback URLs and status callback parameters used in this guide.
Your communication infrastructure is not monolithic and managed in a single place, but rather a pipeline of decentralized components spanning multiple spheres of ownership and responsibility. There are the PSTNs run by telecom companies. There may be PBXs, SBCs, and VOIP systems that you control. And then there are the solutions from Twilio that bridge those worlds whose technology is run and managed by Twilio. All of those combine together to form the totality of your telecommunications.
You want resiliency end-to-end, which means dealing with failures whether they occur within the parts of the architecture you control or those you don't. At Twilio, we have invested heavily in making sure our infrastructure is robust, with failover strategies in place across the world to ensure consistent service, even in the face of carrier outages.
Inevitably, however, things will occasionally go wrong at any part of the architecture. This document describes steps you can take within your own systems and applications to add resiliency to handle failure scenarios, minimizing loss of functionality.
The following sections are broken up into different functional areas for Twilio Voice. Each one has a list of suggestions you can make to deal with failover. The best practices are all independent of each other, so look at the sections that apply to your Twilio usage, and adopt the suggestions that are relevant to your use cases.
- Elastic SIP Trunking Termination
- Elastic SIP Trunking Origination
- SIP Interface
- Interconnect
- Application
- Webhooks
- REST API and server-side SDKs
- Web and Mobile Client SDKs
This section contains best practices for SIP trunking termination, outgoing traffic from your communications infrastructure to the PSTN via Twilio.
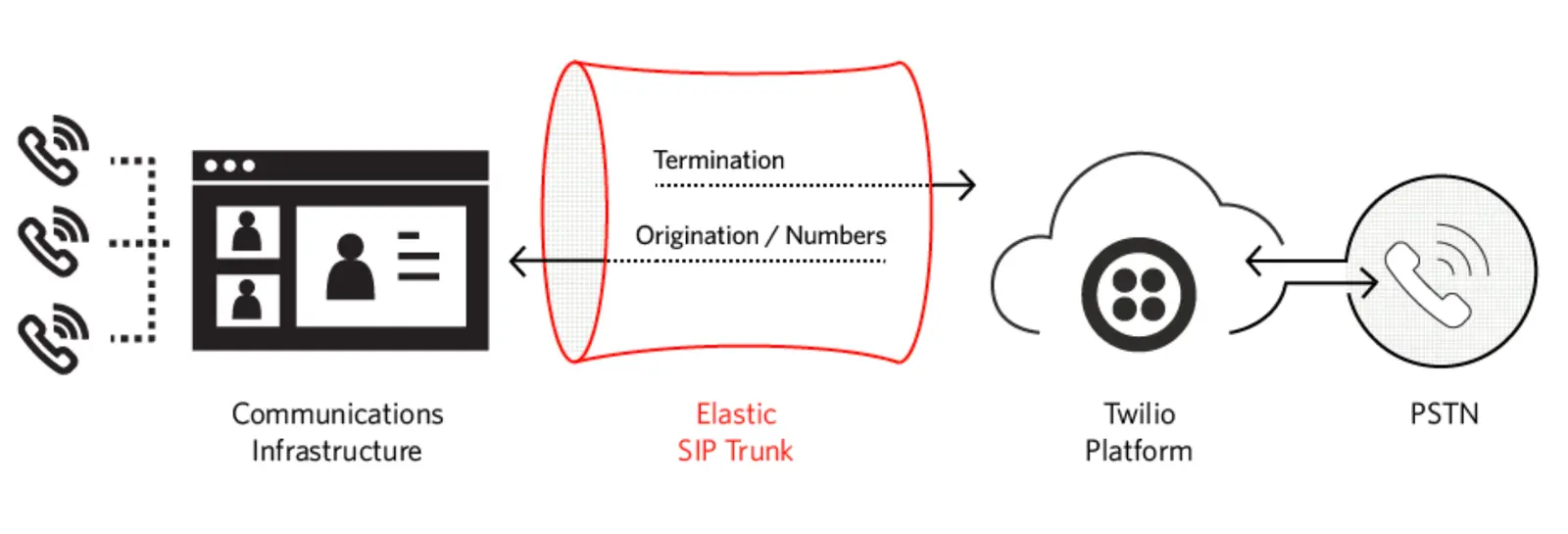
In your trunk configuration, you specify a Twilio address as your termination SIP URI. You either use the generic entry point {yourdomain}.pstn.twilio.com, or a specific geographic edge location nearest to your communications infrastructure, such as {yourdomain}.pstn.sydney.twilio.com. (See the full list of edge locations.)
Whichever address you use, resolving the FQDN (Fully Qualified Domain Name) will result in 3-4 IP addresses returned from DNS, spread across multiple availability zones for resiliency.
Do not pin a single IP address, but instead utilize all of the IP addresses, failing over from one to the next when you don't receive a response from one of them, or the response takes too long. Twilio suggest 4 seconds as good starting point for a timeout interval.
For more information, including timeout recommendations, see Redundancy with Termination URIs.
You can configure your SIP infrastructure to connect to a specific Twilio geographic location. Usually you would pick the closest one to your egress point to minimize latency. (See the full list of edge locations.) If your SIP system allows it, configure one or more fallback SIP URIs to other Twilio edge locations. In the event of an outage in your primary edge location, a fallback will be used so that service continues for your users.
For example, you may specify {yourdomain}.pstn.dublin.twilio.com (Europe Ireland) as your primary termination SIP URI, and {yourdomain}.pstn.frankfurt.twilio.com (Europe Germany) as a fallback. If there is a failure in the Dublin region, your connections will go through Frankfurt.
This section contains best practices for SIP trunking origination, incoming traffic to your communications infrastructure from the PSTN via Twilio.
Your networking and SIP infrastructure must be configured to allow inbound requests from Twilio. Requests egress from Twilio at various edge locations around the world. You can optionally select which edge location outbound requests from Twilio should use with the edge parameter in order to use the nearest one for reduced latency. But if that edge location is down, or you didn't specify a particular edge location, then traffic may originate from a different edge location.
Therefore it is important to whitelist all Twilio IP addresses, not just the IP addresses of the edge location nearest to you, so you don't inadvertently block communication in the event of a failure. This applies to both SIP signalling and RTP media traffic, and their associated ports.
See Twilio's IP addresses for SIP services for the full list of IP addresses and ports used by Twilio edge locations for outbound traffic. You should update your firewall rules to allow traffic from all of the IP addresses and port numbers from all of the edge locations.
The Twilio Elastic SIP Trunking configuration lets you specify multiple origination SIP URIs so you can make your SIP infrastructure highly available. Further tuning is available by specifying priority and weight of those origination SIP URIs which allow for various scenarios, such as load balancing across multiple PBXs/SBCs.
In the following example, load is distributed between the three SBCs, since they have the same priority. And since each one has the same weight, the load will be distributed evenly, so they each get balanced to a third of the time. If one of them goes down, the other two will share the load equally.
| Origination SIP URI | Priority | Weight |
|---|---|---|
sip:mysbc1.com | 10 | 10 |
sip:mysbc2.com | 10 | 10 |
sip:mysbc3.com | 10 | 10 |
In this next example, the load is again distributed between all three URIs, but not evenly. The weights add up to 100, so sip:mysbc1.com will be used 60% of the time since it has more capacity. The two SIP URIssip:mysbc2.com and sip:mysbc3.com will be used for 20% of requests each. If sip:mysbc1.com is unavailable, the two remaining machines will share the load equally, since they will each be selected 50% of the time.
| Origination SIP URI | Priority | Weight |
|---|---|---|
sip:mysbc1.com | 10 | 60 |
sip:mysbc2.com | 10 | 20 |
sip:mysbc3.com | 10 | 20 |
You can configure the origination SIP URIs in the Twilio Console under Elastic SIP Trunking > Trunks > {trunk-name} > Origination:
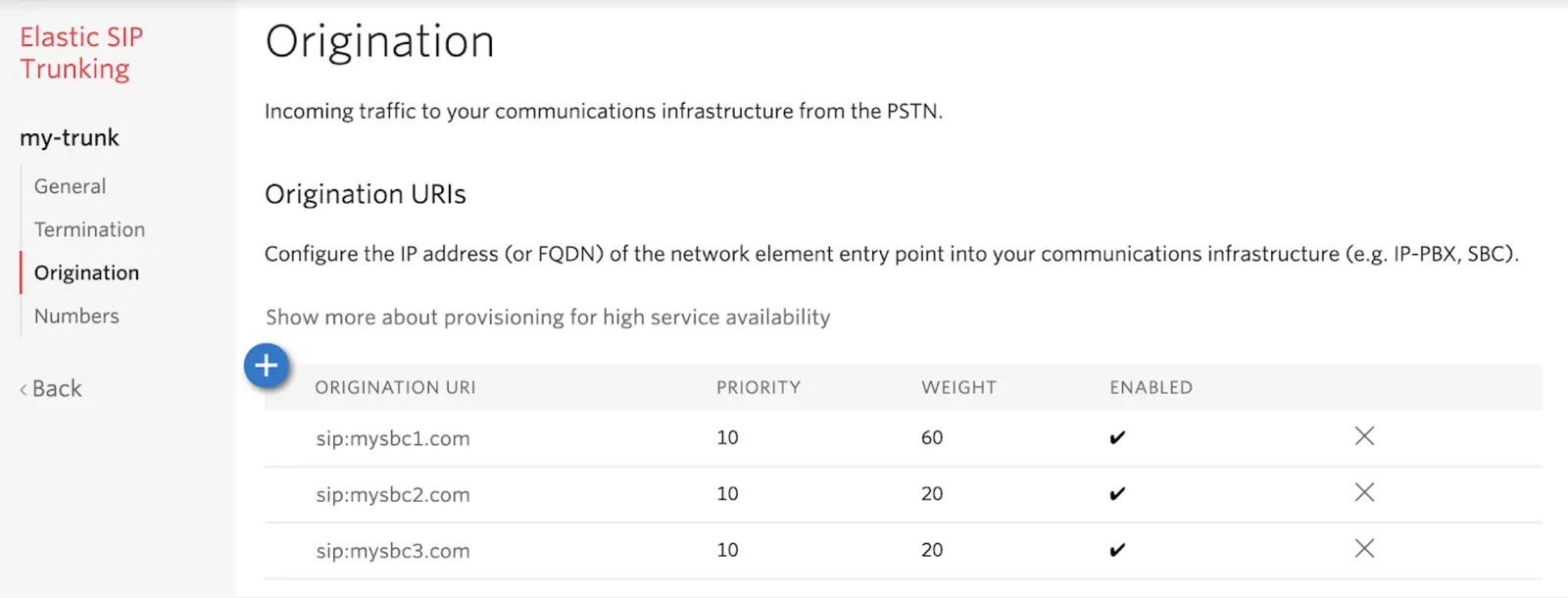
You can also configure the origination SIP URIs using the Twilio API: see OriginationUrl properties for the both the API reference and sample code in various languages.
For more information, including understanding priority and weight, see Using Multiple Origination SIP URIs.
Hosting PBXs/SBCs in different regions allows communication to still succeed if one of your regions has an outage. To configure that you can use the same capability as the previous section, Load balance between multiple PBXs/SBCs, to specify multiple PVXs/SBCs with different priorities.
In the following example, all traffic will be directed to sip:mysbc-primary.com since it's priority value is the lowest. If it fails, then traffic will be directed to the standby SBC at sip:mysbc-secondary.com.
| Origination SIP URI | Priority | Weight |
|---|---|---|
sip:mysbc-primary.com | 10 | 10 |
sip:mysbc-secondary.com | 20 | 10 |
As with the previous section, you can specify your origination SIP URIs in the Twilio Console or using the Twilio API.
For more information, including understanding priority and weight, see Using Multiple Origination SIP URIs. That link also shows a non-trivial example that combines load balancing across multiple SBCs along with a fallback URI should those SBCs all fail or become unreachable.
If calls cannot be delivered to any of your origination SIP URIs at all due to disaster, then Twilio can trigger a webhook to an application at a URL specified by the disaster recovery URL. This setting is found in the Twilio Elastic SIP trunking configuration.
The disaster recovery URL is expected to return TwiML, and can perform any operation normally done by a Twilio application. It could say a message to try again later, take a voicemail, or redirect to another number. Or the application can be more sophisticated, including replicating the functionality of your PBX.
For each new origination SIP request, Twilio will first try your configured SIP URIs, and if none of them succeed, then Twilio will invoke the disaster recovery URL. No additional steps are required when the parts of the architecture affected by the disaster have been restored.
You can configure the disaster recovery URL in the Twilio Console under Elastic SIP Trunking > Trunks > {trunk-name} > Origination:

You can also configure the disaster recovery URL using the Twilio API: see disasterRecoveryUrl and disasterRecoveryMethod in Trunk properties.
For more information, see Disaster Recovery URL.
This section describes best practices when using the SIP interface as part of Twilio Programmable Voice.
You register SIP endpoints with Twilio so we know where to direct calls targeting that SIP device. You can register with a specific Twilio edge location that is closest to your device so connections coming from Twilio have the lowest latency, resulting in best performance and quality.
If your SIP device supports failover then you can register to a primary domain closest to your SIP device, and a secondary domain that is next closest, and so on. If there is an outage in the primary edge location, then calls will come from the secondary edge location, with the next best latency, rather than from a non-deterministic edge location.
For instance, you could register your SIP device in the Singapore edge location using {yourdomain}.sip.singapore.twilio.com, and specify a fallback edge location in Sydney with {yourdomain}.sip.sydney.twilio.com.
The ability to failover to a specific location depends on the capability of your SIP device. If it does not support failover, and the edge location you registered is down, communication to that device will egress Twilio from one of our other edge locations.
For more information, see Register your SIP Endpoint.
This section lists best practices for customers using Twilio Interconnect.
You should connect to at least two different Twilio Exchange locations in different regions for high availability so an outage in one location will not interrupt your service.
Per the Twilio Exchange Locations documentation, for high availability, we strongly recommend connecting to at least two of our geographically redundant Twilio Exchange locations. For example, you can select a 100-Mbps connection in Ashburn, Virginia and a 100-Mbps connection in San Jose, California to create redundant connections to Twilio on both coasts of the United States. Similarly, for Europe and Asia Pacific, our exchanges in London, Frankfurt, Singapore,Tokyo and Sydney can be used to accomplish redundancy in those regions.
This section discusses best practices for your application, which responds to webhook requests and callbacks from Twilio Programmable Voice.
If you configure Twilio to invoke webhooks to your application, then it is your responsibility to ensure that the application is always available. For example, the webhook URL could point to a load balancer which dispatches requests to one of several redundant applications to process them. If one of the applications experiences an outage, the others will continue service to requests.
If you don't want to host and manage the application yourself, you can use serverless Functions, TwiML Bins, or Studio flows. With each of those options, the hosting is done for you.
Any dependencies used by your application should have redundancy. For example, if your application uses MongoDB to store state between requests, then it needs to be highly available, otherwise a MongoDB outage will prevent your application from working.
This section contains best practices around webhooks, when Twilio interacts with your application.
Even if your application is highly available, it won't save you in every situation. For example, your entire data center could experience a disaster. Or a network issue might prevent connections getting through to your application.
Wherever you can specify a webhook URL, you can also specify a fallback webhook URL that will be used if the primary URL fails. The following screenshot shows an example from the Twilio Console with primary and fallback webhooks to be used when a Twilio number receives a call:

Your fallback application can have identical functionality to the primary application. Or it can be something simpler, such as redirecting to a support line or saying a message to the caller to try again later.
The fallback webhook URL should point to a different availability zone, region, or even cloud provider (such as Microsoft Azure or Google Cloud) so it is not affected by the outage impacting the primary webhook URL. Alternatively, you can also use serverless Functions, TwiML Bins, or Studio flows as a fallback.
Twilio will continue to invoke the primary URL prior to the fallback URL for each new event, so when the outage is over, normal operation will resume without any intervention on your part.
If Twilio does not receive a valid response from your webhooks - either your fallback URL if you have one specified, or your primary URL if you haven't - an error is logged and a pre-recorded message is played back to the caller explaining that an error has occurred.
When Twilio invokes a fallback URL due to the primary URL failing to respond, two additional parameters are included in the request to indicate the error code of the failure and the URL for which the failure occurred: ErrorCode and ErrorUrl. The ErrorCode parameters provides information about the error, and the ErrorUrl parameter tells you the original URL that failed.
This means:
- The fact that the fallback URL was invoked at all reveals there was an error, allowing you to raise an alert or do error logging.
- You can gain some insight into what went wrong using the
ErrorCodeandErrorUrlparameters.
Twilio provides URL extensions that can be added to any webhook requests. Several extensions are available, however one that is relevant for failover is edge location (e) parameter which specifies the egress Twilio edge location for the request.
If you provide a list, Twilio will retry on failure over each edge location in the list. In the following example the first attempt goes out over Ashburn (US East Coast), and the second attempt goes out over Umatilla (US West Coast): https://example.com/foo?query=123#e=ashburn,umatilla
In this way, you have control where webhooks egress from the Twilio network in the event of an outage. See the documentation for more information: Webhooks (HTTP callbacks): Connection Overrides.
This section covers using the REST API and the associated server-side SDKs (JavaScript/node.js, C#, Java, Python, etc).
The base entrypoint hostname for the API is api.twilio.com. You can use that domain explicitly with REST, or implicitly with the server-side SDKs. Here is an example using REST:
1curl -XPOST https://api.twilio.com/2010-04-01/Accounts/ACXXXXXXXXXX/Messages.json \2--data-urlencode "To=+13105555555" \3--data-urlencode "From=+12125551234" \4--data-urlencode "MediaUrl=https://demo.twilio.com/owl.png" \5--data-urlencode "Body=Hello from my Twilio line!" \6-u ACXXXXXXXXXX:your_auth_token'
However you can also explicitly specify the edge location you'd like to use with the pattern api.{edge}.us1.twilio.com where {edge} is one of the Twilio edge locations listed in Edge Locations. For example, api.sydney.us1.twilio.com. If you use the generic endpoint api.twilio.com it will default to ashburn.
When using a server-side SDK, you don't provide the domain explicitly, but instead provide the region and edge you'd like to use. Here is a JavaScript example:
1const client = require("twilio")(accountSid, authToken, { edge: "sydney" });23client.messages4.create({5body: "Hello from my Twilio line!",6from: "+12125551234",7to: "+13105555555",8})9.then((message) => console.log(message));
At the time of writing, there are three regions available: us1, ie1 (voice) and au1 (voice). More regions will be coming online in the future. If region is unspecified, then the default us1 is used.
If you don't receive a response from the edge you tried, then you should fallback to your next preferred edge. For instance, if your request to api.ashburn.us1.twilio.com (US East Coast) failed, then your client can try api.umatilla.us1.twilio.com (US West Coast).
This section contains best practices for web and mobile client SDKs.
When making a call, the device can specify the preferred edge to connect to. For reduced latency and increased performance, you will typically use the edge location nearest the SIP device. Examples:
| JavaScript: | Twilio.Device.setup(token, { edge: ['dublin'] }); |
| iOS: | TwilioVoice.edge = "dublin"; |
| Android: | Voice.setEdge("dublin"); |
If the edge location you selected is experiencing an outage and the call cannot be established, you can then try your next preferred edge location. You can read more about this at Edge Locations.
The JavaScript SDK has additional capability that will enable automatic edge fallback functionality if you specify an array of edge locations: Twilio.Device.setup(token, { edge: ['dublin', 'frankfurt', 'ashburn'] });
That lets you specify the preferred edge to use, along with one or more fallback locations in case the first location fails. In the previous example, the SDK will attempt to connect to dublin. If dublin is unreachable, the attempt will fail, and the SDK will then attempt to connect to frankfurt, and so on. For more information, see the Voice SDK Edge docs.
If the token provider used by your clients is not available, then they will not be able to make and receive calls. Ensure that your token provider has redundancy and failover capabilities.
This guide covers a feature that can support the following use cases:
You can use the feature in this guide to secure your automated telephone keypads and IVR nodes against localized drop-offs. If your application server goes offline, redundant webhook handlers step in to process customer selections and database queries reliably.
To learn more advanced features that you can use with self-service automation, see Voice self-service automation.
You can use the feature in this guide to keep incoming call routing paths functional when main infrastructure channels encounter unexpected disruptions. Fallback options redirect prospective buyers to backup lines or standard disaster recovery numbers instead of giving busy signals.
To learn more advanced features that you can use with inbound contact centers, see Voice inbound contact center.
You can use the feature in this guide to maintain persistent dialer workflows for your sales or support representatives. High-availability configurations protect active calling sessions from dropping completely if an individual network edge experiences high packet loss.
To learn more advanced features that you can use with outbound contact centers, see Voice outbound contact center.
Explore the following guides to build on what you've learned in this guide:
- Respond to incoming phone calls: Learn how to build basic webhook systems to capture initial voice prompts.
- Modify live calls: Programmatically redirect, terminate, or adjust ongoing telephony sessions on demand.