How to use Health Checks to improve AWS Load Balancer Resiliency
Time to read: 5 minutes
January 19, 2022
Written by
Reviewed by

While AWS components are generally resilient, when you run at the scale of Twilio, it becomes necessary to fine-tune things to achieve the highest level of quality and availability.
In this post, we’ll examine how to improve the Elastic Load Balancers (ELBs) to increase their fault tolerance. Using custom health checks and multivalued DNS records, we will be able to obtain fine-grained metrics on the availability of each of the ELB constituent nodes. With these metrics, we can adjust the self-healing behavior of the ELB with any criteria we consider for our purposes.
Requirements
In order to implement the fault-tolerant ELB solution, you need an AWS account with permissions for creating:
- Route53 hosted zones and records
- DNS Health Checks
- Elastic Load Balancers
- CloudWatch Alerts
About the Elastic Load Balancer (ELB) internals
In order to understand the solution, it’s necessary to know a little bit about the internal structure of an AWS Elastic Load Balancer (ELB). As we see in the following figure, when we create an ELB, we might select multiple Availability Zones (AZs) in which this ELB will operate. For each of these AZs, one node with an associated IP Address will be created.
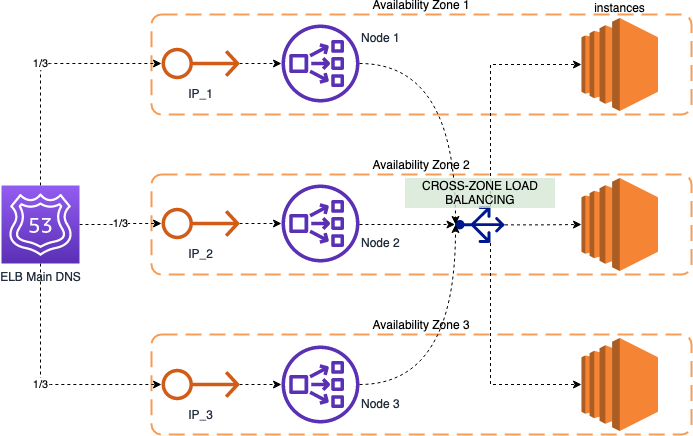
The “ELB Main DNS” record will return all of these IPs, so the traffic will be evenly distributed among the different nodes on each AZ. The DNS record includes an embedded Health Check, that constantly tests the different nodes for availability: if an AZ starts having connection problems, it will automatically be removed from the pool and won’t receive traffic until it becomes available again.
Disadvantages of the default ELB setup
The problem with the default setup of the Elastic Load Balancers (ELBs), is that the threshold for the “ELB Main DNS” to mark an Availability Zone (AZ) as unavailable is that more than 80% of the checks must fail in order for it to be removed, and this is too high.
With this setup, if an AZ is having problems and dropping 50% of the traffic, the DNS will still be sending a third of the total received traffic to that IP, meaning that ⅓ * 50% of the traffic (16.7%) will be lost. For many cases, this amount of traffic lost or compromised is unacceptable.
Custom DNS Health Checks
The solution that we implemented consists in improving this health check mechanism by using more aggressive criteria for considering an Availability Zone as unhealthy. The following picture shows the elements included in our solution:
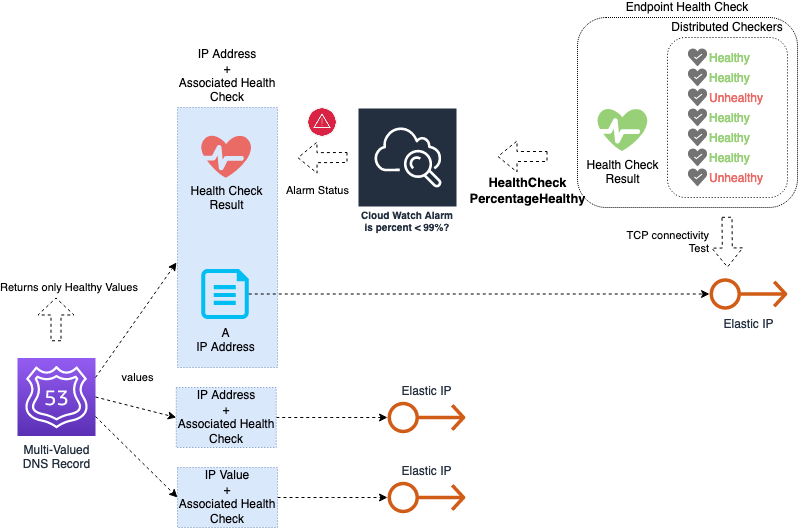
The elements are:
- An “Endpoint Health Check” for each individual IP of the load balancer (top-right corner). This health check opens TCP connections to the IP address from multiple checker nodes distributed in different locations. As a result, it generates a metric for CloudWatch called “HealthCheckPercentageHealthy”, which is the percentage of checkers that obtained a successful connection from the endpoint.
- The exported metric from each Endpoint Health Check is used to create a CloudWatch Alarm (top-center), which is triggered when the value falls below a certain threshold for a certain period of time. For this threshold, we can be as aggressive as needed. A good value would be that the average falls below 99% over a period of 5 minutes.
- The CloudWatch Alarm is used as the basis for a custom health check (top-left corner), which is attached to a Multi-Valued DNS record for that specific IP (left).
The end result is a DNS record that substitutes the previous “ELB Main DNS” with a much more sensitive and proactive detection of errors in the individual IPs of the load balancer.
Take into consideration that these kinds of records use a fail open criteria, which means that if all the endpoints are marked as unhealthy, then all of them are returned. This way we never get the case of zero IPs being returned in case all AZ are failing at the same time. Using this approach, the clients will still be able to use the degraded service, whereas if all the IPs were removed from the pool, they wouldn’t be able to use it at all.
However, what might happen is that a single IP remains taking the whole production traffic. Even though the AWS load balancers can take huge amounts of traffic on only one of the nodes, this might be a scary scenario, as this component would become a single point of failure. To mitigate the impact of this scenario, we might go further ahead, and use two load balancers instead of one.
A step forward: using multiple load balancers
As a way to improve even more the resiliency of our load balancing system, we can extend the usage of the Multi-Valued DNS records to point to two Load Balancers at the same time. The result is depicted in the following diagram:
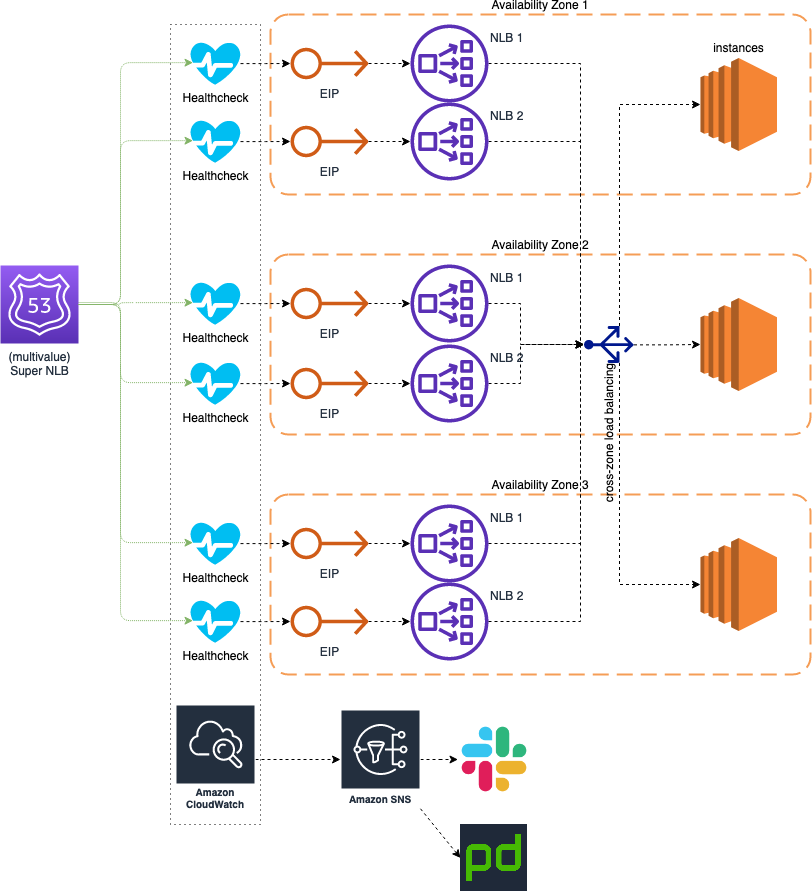
By creating two load balancers and pointing the Multi-Valued DNS record to their individual IPs, we obtain a sort of “Super Load Balancer”, that is able to take double of traffic on each availability zone. This way the “single AZ” scenario is much better covered.
Results in a real scenario
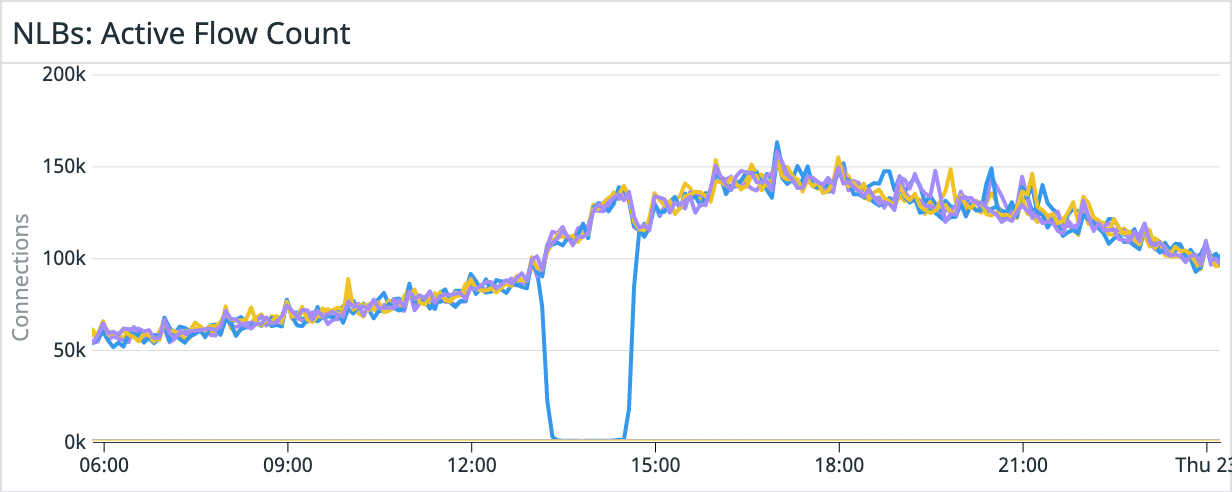
The following scenario is an actual in-house application of the previously described mechanism: after a loss of power within a single AWS data center in December 2021, several connectivity alerts were triggered. The “HealthCheckPercentageHealthy” metric reported a drop to 60% in a single node for the set of load balancers. Given that this drop is not enough to trigger the default AWS healing mechanism, this would have supposed a reduction in connection success rate down to (60% + 100% * 5) / 6 = 93.3% to the Network Load Balancers (assuming the use of 2 NLBs with 3 nodes each). This would have been added to the connectivity issues of the EC2 instances, which according to Datadog implied a drop to about 98.3% in the connection success rate. For the overall system, the connection success rate would have dropped to 98.3% * 93.3% = 91.7%.
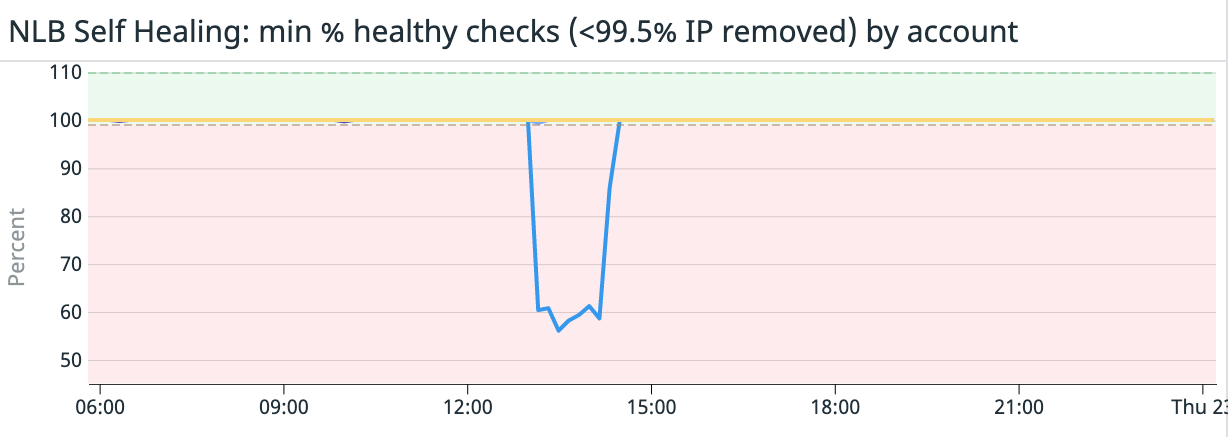
However, thanks to the strict health check mechanism being used, the faulty node was immediately removed from the pool, and stopped being returned to clients by the DNS record. This is shown in the following graph: the affected IP address stopped getting new connections, and the rest of the IPs just took over, hence preventing customers from experiencing connectivity problems. Once the affected Availability Zone resumed normal operation, the removed IP was added back to the pool and started taking connections again. The end result is that the Load Balancer operated almost at a 100% of availability during the incident, increasing the success rate from the potential 91.7% up to 98.3%.
Ending thoughts
How much traffic do your services receive? What are your SLOs and SLAs? If your traffic and customer base is growing enough to become very sensitive to infrastructure failures, this solution will definitely help you. Even though AWS services are highly reliable overall, the “default” resiliency mechanisms might not be enough to maintain the level of quality your service needs.
We hope this solution helps your company grow in a fast and stable way. If you’re building services on AWS, here’s a couple other articles that may be of interest:

Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.