4 Tools for Web Scraping in Node.js
Time to read:
April 29, 2020
Written by
Reviewed by
.png")
Sometimes the data you need is available online, but not through a dedicated REST API. Luckily for JavaScript developers, there are a variety of tools available in Node.js for scraping and parsing data directly from websites to use in your projects and applications.
Let's walk through 4 of these libraries to see how they work and how they compare to each other.
Make sure you have up to date versions of Node.js (at least 12.0.0) and npm installed on your machine. Run the terminal command in the directory where you want your code to live:
For some of these applications, we'll be using the Got library for making HTTP requests, so install that with this command in the same directory:
Let's try finding all of the links to unique MIDI files on this web page from the Video Game Music Archive with a bunch of Nintendo music as the example problem we want to solve for each of these libraries.
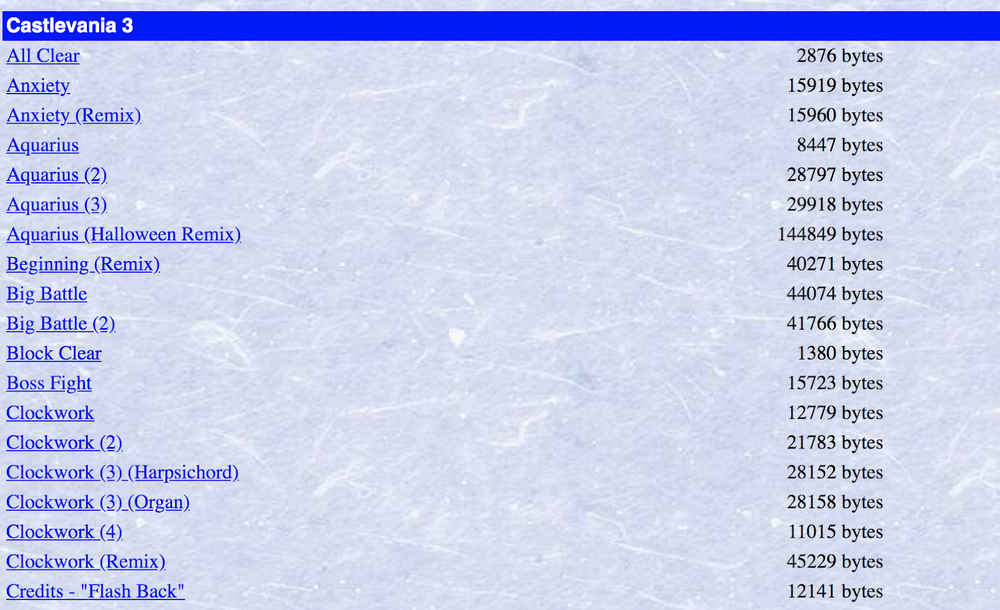
Tips and tricks for web scraping
Before moving onto specific tools, there are some common themes that are going to be useful no matter which method you decide to use.
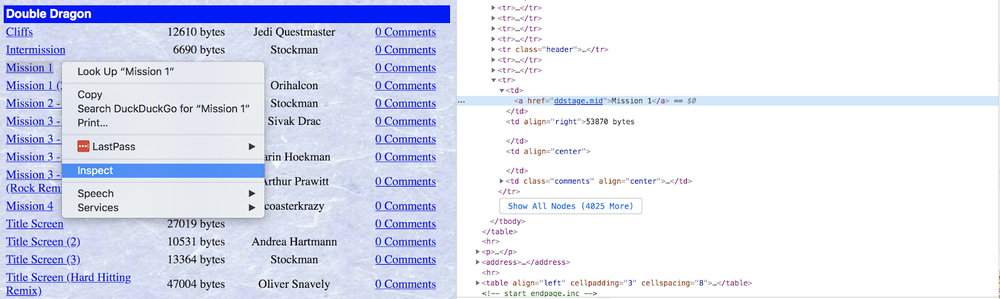
Before writing code to parse the content you want, you typically will need to take a look at the HTML that’s rendered by the browser. Every web page is different, and sometimes getting the right data out of them requires a bit of creativity, pattern recognition, and experimentation.
There are helpful developer tools available to you in most modern browsers. If you right-click on the element you're interested in, you can inspect the HTML behind that element to get more insight.
You will also frequently need to filter for specific content. This is often done using CSS selectors, which you will see throughout the code examples in this tutorial, to gather HTML elements that fit a specific criteria. Regular expressions are also very useful in many web scraping situations. On top of that, if you need a little more granularity, you can write functions to filter through the content of elements, such as this one for determining whether a hyperlink tag refers to a MIDI file:
It is also good to keep in mind that many websites prevent web scraping in their Terms of Service, so always remember to double check this beforehand. With that, let's dive into the specifics!
jsdom
jsdom is a pure-JavaScript implementation of many web standards for Node.js, and is a great tool for testing and scraping web applications. Install it in your terminal using the following command:
The following code is all you need to gather all of the links to MIDI files on the Video Game Music Archive page referenced earlier:
This uses a very simple query selector, a, to access all hyperlinks on the page, along with a few functions to filter through this content to make sure we're only getting the MIDI files we want. The noParens() filter function uses a regular expression to leave out all of the MIDI files that contain parentheses, which means they are just alternate versions of the same song.
Save that code to a file named index.js, and run it with the command node index.js in your terminal.
If you want a more in-depth walkthrough on this library, check out this other tutorial I wrote on using jsdom.
Cheerio
Cheerio is a library that is similar to jsdom but was designed to be more lightweight, making it much faster. It implements a subset of core jQuery, providing an API that many JavaScript developers are familiar with.
Install it with the following command:
The code we need to accomplish this same task is very similar:
Here you can see that using functions to filter through content is built into Cheerio’s API, so we don't need any extra code for converting the collection of elements to an array. Replace the code in index.js with this new code, and run it again. The execution should be noticeably quicker because Cheerio is a less bulky library.
If you want a more in-depth walkthrough, check out this other tutorial I wrote on using Cheerio.
Puppeteer
Puppeteer is much different than the previous two in that it is primarily a library for headless browser scripting. Puppeteer provides a high-level API to control Chrome or Chromium over the DevTools protocol. It’s much more versatile because you can write code to interact with and manipulate web applications rather than just reading static data.
Install it with the following command:
Web scraping with Puppeteer is much different than the previous two tools because rather than writing code to grab raw HTML from a URL and then feeding it to an object, you're writing code that is going to run in the context of a browser processing the HTML of a given URL and building a real document object model out of it.
The following code snippet instructs Puppeteer's browser to go to the URL we want and access all of the same hyperlink elements that we parsed for previously:
Notice that we are still writing some logic to filter through the links on the page, but instead of declaring more filter functions, we're just doing it inline. There is some boilerplate code involved for telling the browser what to do, but we don't have to use another Node module for making a request to the website we're trying to scrape. Overall it's a lot slower if you're doing simple things like this, but Puppeteer is very useful if you are dealing with pages that aren't static.
For a more thorough guide on how to use more of Puppeteer's features to interact with dynamic web applications, I wrote another tutorial that goes deeper into working with Puppeteer.
Playwright
Playwright is another library for headless browser scripting, written by the same team that built Puppeteer. It's API and functionality are nearly identical to Puppeteer's, but it was designed to be cross-browser and works with FireFox and Webkit as well as Chrome/Chromium.
Install it with the following command:
The code for doing this task using Playwright is largely the same, with the exception that we need to explicitly declare which browser we're using:
This code should do the same thing as the code in the Puppeteer section and should behave similarly. The advantage to using Playwright is that it is more versatile as it works with more than just one type of browser. Try running this code using the other browsers and seeing how it affects the behavior of your script.
Like the other libraries, I also wrote another tutorial that goes deeper into working with Playwright if you want a longer walkthrough.
The vast expanse of the World Wide Web
Now that you can programmatically grab things from web pages, you have access to a huge source of data for whatever your projects need. One thing to keep in mind is that changes to a web page’s HTML might break your code, so make sure to keep everything up to date if you're building applications that rely on scraping.
I’m looking forward to seeing what you build. Feel free to reach out and share your experiences or ask any questions.
- Email: sagnew@twilio.com
- Twitter: @Sagnewshreds
- Github: Sagnew
- Twitch (streaming live code): Sagnewshreds


Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.