Umwandeln von Sprache in Text im Browser mit der Web Speech API
Time to read:
February 10, 2020
Autor:in:

Die Web Speech API bietet zwei Funktionen: die Sprachsynthese, auch als Text-to-Speech bezeichnet, und die Spracherkennung, also das Umwandeln von Sprache in Text. In einem früheren Blog bin ich auf die Sprachsynthese eingegangen, hier untersuche ich, wie Browser mithilfe der SpeechRecognition API Sprache erkennen und transkribieren.
Wenn wir in der Lage sind, Sprachbefehle von Benutzern zu verarbeiten, können wir immersivere Benutzeroberflächen entwerfen. Dies ist wichtig, weil Benutzer gerne ihre Stimme verwenden. Google meldete 2018, dass 27 % der weltweiten Online-Bevölkerung die Sprachsuche auf Mobilgeräten nutzen. Mit Spracherkennung im Browser sorgen wir also dafür, dass Benutzer mit unserer Website „sprechen“ können. Möglich wird dies über die Sprachsuche oder die Entwicklung eines interaktiven Bots in der Anwendung.
Wir werfen nun einen genaueren Blick auf die API, um zu sehen, welche Möglichkeiten sie uns bietet.
Das brauchen wir
Um die API in Aktion zu erleben, entwerfen wir eine Beispiel-App. Wer mitentwickeln möchte, braucht Folgendes:
- Google Chrome
- einen Texteditor
Das war's schon, denn wir können die Aufgabe mit plain HTML, CSS und JavaScript erledigen. Wenn alles bereit liegt, erstellen wir ein neues Arbeitsverzeichnis und speichern diese Starter HTML-Datei und CSS im betreffenden Verzeichnis. Achtet darauf, dass sich die Dateien im selben Verzeichnis befinden, und öffnet dann die HTML-Datei im Browser. Das Ganze sollte so aussehen:
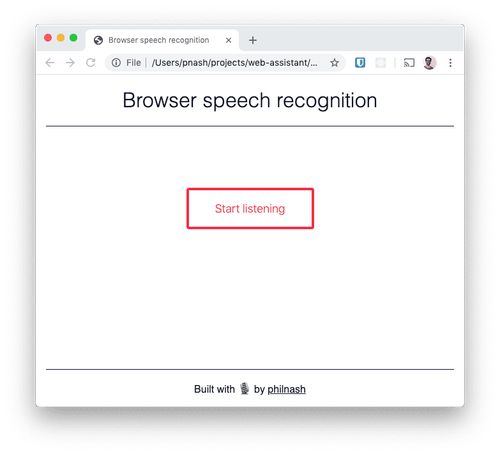
Als Nächstes müssen wir den Browser dazu bringen, uns zuzuhören und uns zu verstehen.
Die SpeechRecognition API
Bevor wir die Spracherkennung in unsere Beispiel-Anwendung integrieren, werfen wir in den Browser-Entwicklertools einen genaueren Blick darauf. Wir öffnen in Chrome die Entwicklertools. Dann geben wir Folgendes in die Konsole ein:
Wenn wir diesen Code ausführen, bittet Chrome um Erlaubnis, das Mikrofon zu verwenden, und erinnert sich dann, wenn die Seite auf einem Web-Server dargestellt wird, an eure Stimme. Wir führen den Code aus und sprechen ins Mikrofon, nachdem wir unsere Zustimmung gegeben haben. Sobald wir aufhören zu sprechen, sollten wir in der Konsole ein SpeechRecognitionEvent sehen.
Diese 3 Zeilen Code bewirken so einiges. Wir haben eine Instanz der SpeechRecognition API erstellt (in diesem Fall mit dem Hersteller-Präfix „webkit“), die API angewiesen, alle vom Spracherkennungsdienst erhaltenen Ergebnisse zu speichern, und die Zuhörfunktion aktiviert.
Darüber hinaus greifen hier auch verschiedene Standardeinstellungen. Sobald das Objekt ein Ergebnis empfängt, wird das Zuhören beendet. Um die Transkription fortzusetzen, müssen wir daher wieder start aufrufen. Wir erhalten übrigens nur das endgültige Ergebnis vom Spracherkennungsdienst. Später befassen wir uns mit den Einstellungen, die ein kontinuierliches Transkribieren und Zwischenergebnisse während der Spracheingabe ermöglichen.
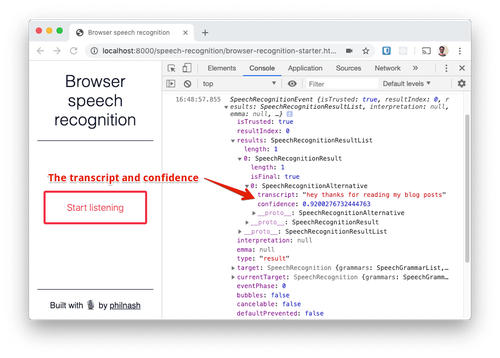
Sehen wir uns das SpeechRecognitionEvent-Objekt einmal genauer an. Die wichtigste Eigenschaft ist results, eine Liste der SpeechRecognitionResult-Objekte. Es gibt hier nur ein Ergebnisobjekt, weil wir nur einmal gesprochen haben, bevor das Zuhören beendet wurde. Eine genauere Prüfung des Ergebnisses zeigt eine Liste mit SpeechRecognitionAlternative-Objekten, von denen das erste das Transkript des Gesprochenen sowie einen Zuverlässigkeitswert zwischen 0 und 1 enthält. Standardmäßig wird nur eine Alternative zurückgegeben. Wir können jedoch festlegen, dass wir mehrere Alternativen vom Spracherkennungsdienst erhalten möchten. Dies ist beispielsweise nützlich, wenn wir Benutzern die Möglichkeit geben möchten, die Variante auszuwählen, die ihrer Spracheingabe am nächsten kommt.
So funktioniert's
Eigentlich ist es nicht ganz zutreffend, diese Funktion im Browser als Spracherkennung zu bezeichnen. Derzeit erfasst Chrome die Audioaufnahme und sendet sie an die Google-Server, die dann die Transkription übernehmen. Das ist auch der Grund, warum die Spracherkennung zurzeit nur in Chrome und einigen Chromium-basierten Browsern unterstützt wird.
Mozilla hat die Unterstützung für die Spracherkennung in Firefox integriert. Sie befindet sich hinter einem Flag in Firefox Nightly. Gleichzeitig verhandelt Mozilla über den Einsatz der Google Cloud Speech API. Mozilla arbeitet zwar an einer eigenen DeepSpeech-Engine, wollte aber so schnell wie möglich Unterstützung für die Spracherkennung in Browsern bieten und entschied sich daher für die Nutzung des Google-Dienstes.
Da die SpeechRecognition eine serverseitige API nutzt, können Benutzer sie nur verwenden, wenn sie online sind. In der Zukunft wird es hoffentlich auch lokale, Offline-Spracherkennungsfunktionen geben, aber derzeit besteht diese Einschränkung.
Wir kombinieren jetzt den zuvor heruntergeladenen Starter-Code und den Code aus den Entwicklertools, um eine kleine Anwendung zu erstellen, die live eine Spracheingabe eines Benutzers transkribiert.
Spracherkennung in einer Web-Anwendung
Zunächst öffnen wir die HTML-Datei, die wir anfangs heruntergeladen haben. Wir beginnen damit, zwischen den <script>-Tags unten auf das DOMContentLoaded-Ereignis zu warten und dann Verweise auf einige der von uns verwendeten Elemente zu erfassen.
Wir testen, ob der Browser das Objekt SpeechRecognition oder webkitSpeechRecognition unterstützt. Ist dies nicht der Fall, erscheint eine entsprechende Meldung und wir können nicht fortfahren.
Ist der Zugriff auf das Objekt SpeechRecognition möglich, können wir die Verwendung vorbereiten. Wir definieren eine Variable, um anzugeben, ob wir derzeit aktiv auf Spracheingaben warten, erzeugen eine Instanz des Spracherkennungsobjekts und drei Funktionen, um zu starten, zu stoppen und auf neue Ergebnisse der Erkennung zu reagieren:
Bei der Startfunktion ist das Ziel, die Spracherkennung zu starten und den Schaltflächentext zu ändern. Wir fügen außerdem dem Hauptelement eine Klasse hinzu, damit eine Animation gestartet wird, die zeigt, dass die Seite zuhört. Bei der Stoppfunktion gehen wir genau andersherum vor.
Wenn wir ein Ergebnis erhalten, nutzen wir es, um alle Ergebnisse auf der Seite zu rendern. In diesem Beispiel erledigen wir das mit einfacher DOM-Manipulation. Wir fügen die SpeechRecognitionResult-Objekte von vorhin als Absätze in den Ergebnis-<div> ein. Um den Unterschied zwischen den endgültigen und den Zwischenergebnissen zu zeigen, fügen wir allen als „final“ markierten Ergebnissen eine Klasse hinzu.
Bevor wir die Spracherkennung ausführen, müssen wir die Einstellungen festlegen, die für die App verwendet werden sollen. Wir werden bei dieser Version die Ergebnisse kontinuierlich aufzeichnen, statt die Aufnahme bei Abschluss der Spracheingabe zu beenden. Auf diese Weise wird weiter auf die Seite transkribiert, bis wir die Stopp-Schaltfläche drücken. Außerdem werden wir Zwischenergebnisse anfordern, um zu sehen, was die Spracherkennung während der Spracheingabe aufzeichnet (vergleichbar mit der Umwandlung von Sprache in Text bei einem Twilio-Anruf über die Befehle <Gather> und partialResultCallback). Darüber hinaus fügen wir den Ergebnis-Listener hinzu:
Abschließend fügen wir der Schaltfläche zum Starten und Stoppen der Spracherkennung einen Listener hinzu.
Wir laden jetzt den Browser neu und probieren es aus.
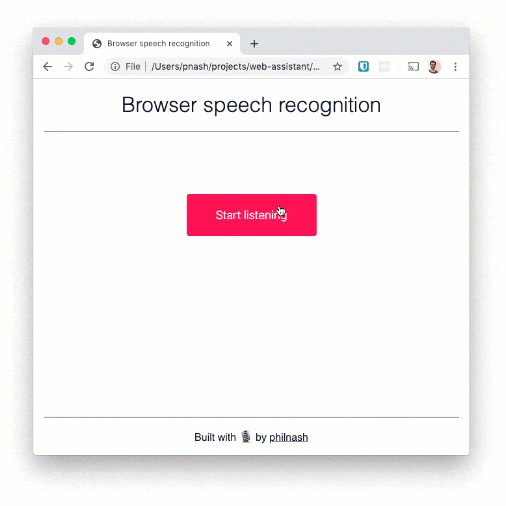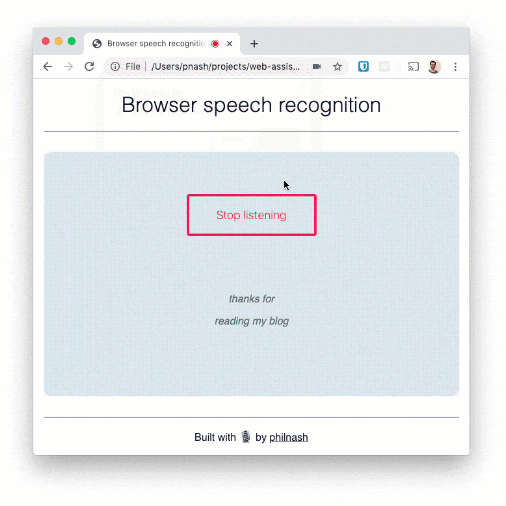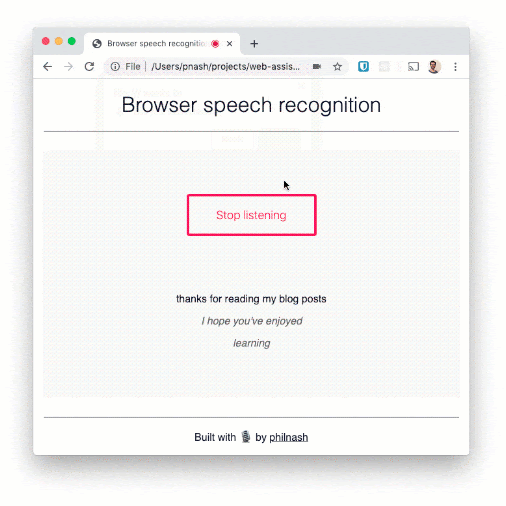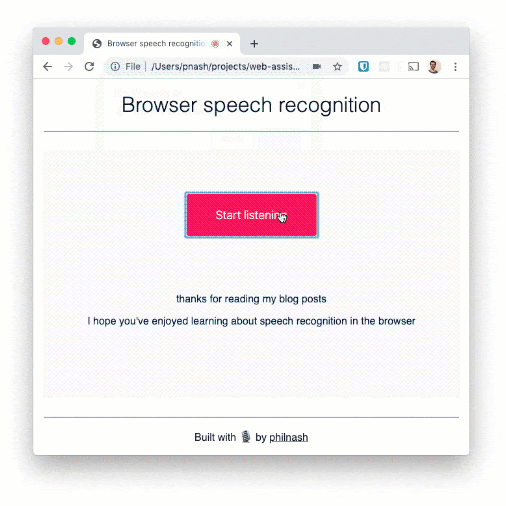
Wir können mehrere Sätze sagen und verfolgen, wie sie auf die Seite geschrieben werden. Die Spracherkennung kann relativ gut mit Worten umgehen, aber bei der Zeichensetzung hakt es. Wenn wir das Ganze zu einer Diktierfunktion ausweiten wollten, müssten wir daher noch weiter programmieren.
Jetzt können wir mit dem Browser sprechen
In diesem Blog habe ich beschrieben, wie wir mit dem Browser sprechen und dafür sorgen, dass er uns versteht. Und in einem früheren Blog bin ich darauf eingegangen, wie der Browser mit uns sprechen kann. Sehr interessant wäre ein Projekt, bei dem diese beiden Funktionen mit einem auf Twilio Autopilot gestützten Assistenten kombiniert werden.
Wer noch ein wenig mit dem Beispiel aus diesem Blog herumspielen möchte, findet es hier auf Glitch. Und der Quellcode steht hier in meinem Repository „web-assistant“ auf GitHub zur Verfügung.
Es gibt unglaublich viele verschiedene Möglichkeiten für interessante Benutzeroberflächen mit Sprachfunktionen. Erst kürzlich habe ich ein geniales Beispiel für ein sprachbasiertes Browser-Spiel gesehen. Lasst mich über das Kommentarfeld unten oder auf Twitter über @philnash wissen, ob ihr gerade an einem interessanten Projekt mit Spracherkennung im Browser arbeitet.


Ähnliche Ressourcen
Twilio Docs
Von APIs über SDKs bis hin zu Beispiel-Apps
API-Referenzdokumentation, SDKs, Hilfsbibliotheken, Schnellstarts und Tutorials für Ihre Sprache und Plattform.
Ressourcen-Center
Die neuesten E-Books, Branchenberichte und Webinare
Lernen Sie von Customer-Engagement-Experten, um Ihre eigene Kommunikation zu verbessern.
Ahoy
Twilios Entwickler-Community-Hub
Best Practices, Codebeispiele und Inspiration zum Aufbau von Kommunikations- und digitalen Interaktionserlebnissen.