4 Ferramentas para fazer extração de dados em Node.js
Time to read:
April 29, 2020
Escrito por
Revisado por

Algumas vezes, os dados que você precisa estão disponíveis online, mas não através de uma API REST. Felizmente, para desenvolvedores JavaScript, existem uma variedade de ferramentas disponíveis em Node.js para extrair e analisar dados diretamente dos websites e usar em seus projetos e aplicativos.
Vamos abordar 4 dessas bibliotecas para ver como elas funcionam e as diferenças entre elas.
Make sure you have up to date versions of Node.js (at least 12.0.0) and npm installed on your machine. Run the terminal command in the directory where you want your code to live:
Certifique-se de que você possui versões atualizadas do Node.js (pelo menos 12.0.0) e npm instaladas na sua máquina. No diretório que seu código será instalado execute no terminal o comando a seguir:
Para algumas dessas aplicações, vamos usar a biblioteca Got para fazer chamadas HTTP, então instale isso com o comando a seguir no mesmo diretório:
Como exemplo de problema que queremos resolver com essas bibliotecas, vamos tentar encontrar todos os links únicos para arquivos MIDI no site do Video Game Music Archive, que possui uma coleção de músicas da Nintendo.
Dicas e truques para fazer web scraping
Antes de começarmos pelas ferramentas, temos algums tópicos em comum que vamos abordar. Eles serão úteis independente do método que você decida utilizar.
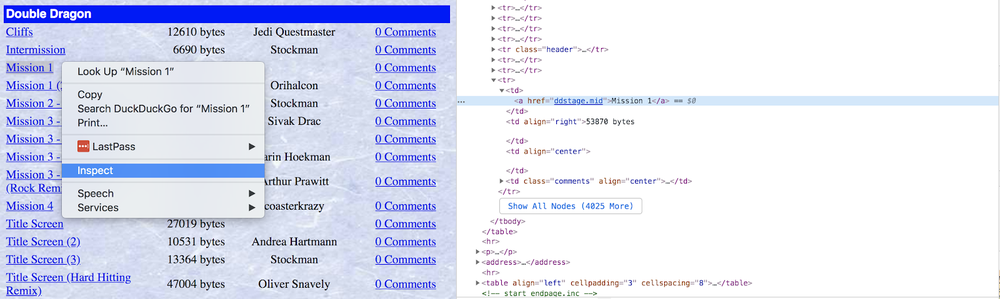
Antes de escrever código para tratar o conteúdo que deseja, você normalmente vai precisar conferir o HTML que foi renderizado pelo navegador. Cada página web é diferente e, as vezes, pegar o dado correto dela pode ser necessário um pouco de criatividade, reconhecimento de padrões e experimentação.
Existem ferramentas muito úteis para desenvolvedores e que já estão disponíveis nos navegadores mais modernos. Se você clicar com o botão direito no elemento que está interessado, você pode inspecionar o HTML por trás daquele elemento e obter mais informações.
Você também pode frequentemente precisar filtrar um conteúdo específico. Isso é feito em alguns casos com seletores CSS, que você verá nos exemplos deste tutorial, para juntar elementos HTML que se encaixam em um critério específico. Expressões regulares também são muito úteis em situações de raspagem de dados (web scraping). Além disso, se você precisa de um pouco mais de granularidade, você pode criar funções para filtrar o conteúdo dos elementos, como este caso para determinar se o hyperlink faz referência a um arquivo MIDI:
Também é muito bom ter em mente que muitos websites proibem raspagem de dados em seus Termos de Serviço, então lembre-se sempre de conferir isso com antecedência. Com isso, vamos nos aprofundar nos detalhes!
jsdom
jsdom é uma implementação totalmente em JavaScript de muitos padrões web para Node.js. É uma ótima ferramenta para testar e extrair dados de aplicações web. Instale ela usando o seguinte comando no seu terminal:
O código a seguir é tudo que precisa para reunir todos os links de arquivos MIDI da página do Video Game Music Arquive, que mencionei anteriormente:
Este exemplo usa um query selector muito simples, a, para selecionar todos os hyperlinks da página, junto com algumas funções para filtrar conteúdos e ter certeza de que estamos pegando apenas os arquivos MIDI que queremos. O filtro noParens() usa uma expressão regular para remover todos os arquivos MIDI que possuem parênteses, que significa que são versões alternativas da mesma música.
Salve todo o código em um arquivo com o nome index.js e execute com o comando node index.js no seu terminal.
Se você quer um passo a passo mais aprofundado desta biblioteca, confira este outro tutorial que escrevi usando jsdom (artigo em Inglês).
Cheerio
Cheerio é uma biblioteca similar ao jsdom, mas que foi desenvolvida para ser mais leve, tornando-a muito mais rápida. Ela implementa um subcojunto do núcleo do jQuery, fornecendo uma API que muitos desenvolvedores JavaScript já estão acostumados.
Instale ela com o seguinte comando:
O código que precisamos para para realizar a mesma tarefa é bem similar aos anteriores:
Aqui você pode ver que estamos usando funções para filtrar o conteúdo que já estão dentro da API do Cheerio, então nós não precisamos de nenhum código adicional para converter a coleção de elementos em um vetor. Substitua o código do index.js por este novo código e o execute novamente. Você vai perceber que a execução foi mais rápida porque o Cheerio é uma biblioteca muito mais leve.
Se você quer ver um passo a passo mais aprofundado, confira este outro tutorial que escrevi usando Cheerio (artigo em Inglês).
Puppeteer
Puppeteer é muito diferente das outras duas bibliotecas anteriores, porque ela é uma biblioteca para scripts de navegador sem interface com o usuário. Puppeteer fornece uma API de alto nível para controlar o Chrome ou Chromium com o protocolo DevTools. Ela é muito mais versátil porque você pode escrever código para interagir e manipular aplicações web no lugar de simplemente ler dados estáticos.
Instale ela com o seguinte comando:
Extrair dados da web com a Puppeteer é muito diferente se comparada com as duas ferramentas anteriores porque no lugar de escrever código para pegar o HTML puro de uma URL e converter ele em um objeto, você está escrevendo um código que roda no contexto de um navegador, processando o HTML de uma dada URL e construindo um modelo de objeto de documento (DOM).
O bloco de código a seguir instrui ao navegador da Puppeteer para ir na URL que queremos e acessar todos os mesmos elementos de hyperlink que analisamos anteriormente:
Observe que nós ainda estamos escrevendo alguma lógica para filtrar através dos links da página, mas no lugar de declarar mais funções de filtro, nós estamos fazendo isso de forma direta. Não existe nenhum código pronto envolvido para dizer ao navegador o que fazer, mas nós não precisamos usar outro módulo do Node para fazer a requisição do website e então extrair os dados. Sobretudo é um pouco mais lento se você precisa fazer coisas mais simples como essa, mas a Puppeteer é muito útil se você está lidando com páginas que não são estáticas.
Para um guia mais completo sobre como usar mais recursos da Puppeteer para interagir com aplicações web dinâmicas, eu escrevi um outro tutorial mais aprofundado da Puppeteer (artigo em Inglês).
Playwright
Playwright é outra biblioteca para scripts em browsers sem interface, escrita pelo mesmo time que construiu a Puppeteer. É uma API e suas funcionalidades são praticamente idênticas a Puppeteer, mas foi desenvolvida para ser cross-browser e funciona com FireFox e Webkit, assim como Chrome/Chromium.
Instale ela com o seguinte comando:
O código para realizar esta tarefa usando a Playwright é praticamente o mesmo, exceto que precisamos declarar explicitamente qual navegador queremos usar:
Esse código faz a mesma coisa que o exemplo da Puppeteer e deve se comportar da mesma maneira. A vantagem de usar Playwright é que ela é mais versátil e funciona com mais de um tipo de navegador. Tente rodar este código usando outros navegadores e veja como ele afeta o comportamento do seu script.
Like the other libraries, I also wrote another tutorial that goes deeper into working with Playwright if you want a longer walkthrough.
Assim como nas outras bibliotecas, eu também escrevi outro tutorial mais aprofundado sobre como trabalhar com a Playwright (artigo em Inglês), se você quiser um passo a passo mais longo.
A grande expansão da World Wide Web
Agora que você pode pegar coisas de páginas web de forma programática, você tem acesso a uma enorme fonte de dados para qualquer necessidade dos seus projetos. Uma coisa que deve ter em mente é que alguma mudança nas páginas web pode quebrar seu código, então certifique-se de manter tudo atualizado se você está construído uma aplicação que depende da extração de dados.
Estou ansioso para ver o que você vai construir. Fique a vontade para falar comigo e compartilhar suas experiências ou fazer alguma pergunta.
- Email: sagnew@twilio.com
- Twitter: @Sagnewshreds
- Github: Sagnew
- Twitch (streaming live code): Sagnewshreds
Publicações relacionadas


Recursos relacionados
Twilio Docs
De APIs a SDKs e aplicativos de amostra
Documentação de referência de API, SDKs, bibliotecas auxiliares, guias de início rápido e tutoriais para sua linguagem e plataforma.
Centro de Recursos
Os mais recentes e-books, relatórios do setor e webinars
Aprenda com especialistas em engajamento do cliente para melhorar sua própria comunicação.
Ahoy
Centro da comunidade de desenvolvedores da Twilio
Melhores práticas, exemplos de código e inspiração para criar comunicações e experiências de engajamento digital.