How We Replaced Our Data Pipeline With Zero Downtime
Time to read:
June 25, 2014
Written by
This post is part of Twilio’s archive and may contain outdated information. We’re always building something new, so be sure to check out our latest posts for the most up-to-date insights.
We’ve been growing faster than ever here at Twilio. Much like any service that grows rapidly, some of the older parts of our infrastructure have started to show their limits. One critical piece that we’ve spent a great deal of effort reworking and scaling is the data pipeline through which calls and messages are transitioned and stored. We’d like to share the approach we took and some of the lessons we learned.
The In-Flight/Post-Flight Problem
Throughout the lifecycle of a phone call or message, it must transition through various in-flight states (such as ringing, in progress, or queued) until it is completed. Due to the asynchronous nature of our service, the in-flight states must be managed and persisted somewhere in the system. Upon reaching a post-flight state, the call or message record must be persisted to long term storage for later retrieval and analytical processing. Historically, all our data was placed in the same datastore regardless of where the call or message was in its lifecycle. There are many problems with this, especially at scale.
Optimizing for Everything is Optimizing for Nothing
Records that are in-flight will have high mutation rates for which the data store must be optimized for high write throughput. Records that are post-flight will not be mutated, but will likely be read frequently, requiring the backing data store to be optimized for high read throughput. By co-locating both in-flight and post-flight data, we are forced to optimize and run hardware that supports both cases simultaneously. This complicates the selection of what storage technology we use and how it’s tuned while increasing our operating expense.
Shared Ownership, Shared Problems
We strive to operate a fully service oriented architecture at Twilio, where all required functionality in our system is provided as a service to other applications. The combined in-flight and post-flight database had been shared and accessed directly by an increasing number of our clients over time. This is a classic problem for any growing codebase and while having clients talk directly to the database is convenient early on, it comes with some adverse long term effects, such as:
- A single point of failure that can degrade many services.
- Difficulty in identifying the cause of such failures and figuring out whose responsibility it is to fix them.
- Coupling of many consumers to an underlying storage technology, making software upgrades and maintenance difficult and risky.
Limitations of Scaling Vertically
In addition to the in-flight and post-flight problem, we also started to encounter the scaling limitations of a single MySQL cluster. For one, our data set was growing close to the limit of what a single node in our cluster could store. Also, while our master nodes could keep up with the increasing levels of throughput, slaves, which are single threaded for replication, started lagging behind and causing issues when lag grew beyond the acceptable consistency window.
Solutions
The solutions for the in-flight/post-flight problem and the coupling of upstream clients to the database are fairly straightforward. The in-flight/post-flight problem is solved by splitting the data into separate data stores, where the in-flight states are stored and mutated independently of the post-flight states. The coupling of upstream clients to the database is solved by inserting services in front of the databases and providing an interface that is better modeled according to the access patterns of the client.
Choosing What to Fix
In addition to the systems we would be changing, it was very tempting to fix other tangentially related components that have given us pain over the years (the "while you’re in there…" syndrome). One we considered replacing was the database technology. While the persistence layer of Twilio is composed of numerous database technologies, we’re heavily rooted in MySQL. The benefits and pains of MySQL are well documented, but for us, the lack of built in sharding and high availability have been the biggest issues. However, for better or for worse, the transactional and consistency guarantees that MySQL provides informed much of the design of our API. Switching to a new technology would need to be done with extreme care, to maintain the semantics that our customers’ software is depending on. As a platform provider, changing core pieces of technology is incredibly scary. Rather than add more risk to an already risky set of changes in our architecture, we opted to not replace MySQL, which means we would have to solve the scaling issues in the application layer.
Sharding MySQL
Without built in sharding, we needed to solve the throughput and data size issues ourselves. This involved first coming up with a sharding strategy that scaled horizontally and supported all patterns of data access. Secondly, we needed to update clients to be shard aware. By putting a service between clients and the datastore, only the one service needs to be aware of how data is sharded and stored.
Sharding Strategy
The first step in figuring out the sharding strategy was selecting a shard key. We needed a key that would keep our data access logic as simple as possible, while providing us with control over how throughput and storage is distributed across the keyspace. Luckily, the vast majority of queries we support access data within a single account so AccountSid was a natural fit.
Once the key was selected, we needed a way to map a given value for the key onto a physical shard. There are many approaches to this that we considered, including consistent hashing, range based and lookup based. One problem with selecting AccountSid as our shard key is the potential for uneven distribution when dealing with large accounts. This drove us to use a combination of range and lookup based mapping.
The service which talks directly to the database maintains a mapping of shard key ranges to physical shards. The lookup based part of the strategy gives us fine grained control over where the value for a given hash key is physically stored and allows us to change it if needed. The range based part of the strategy allows the configuration for the routing to remain sparse, as we did not want to maintain a 1-to-1 mapping for each key to the destination shards. It also allows us to isolate a large customer to a single shard (a range of size 1).
Planning the Rollout
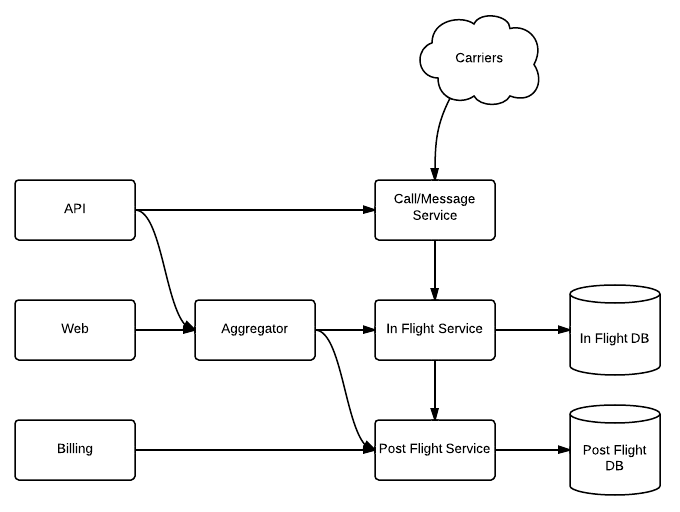
This is a simplified view of the topology prior to the rollout:
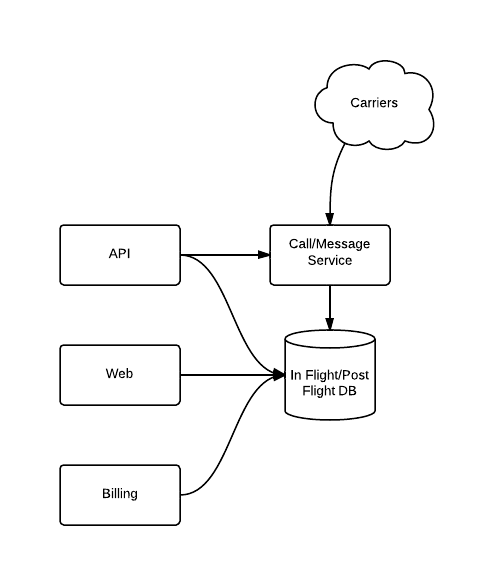
This is where we ended up with the new system fully in place:
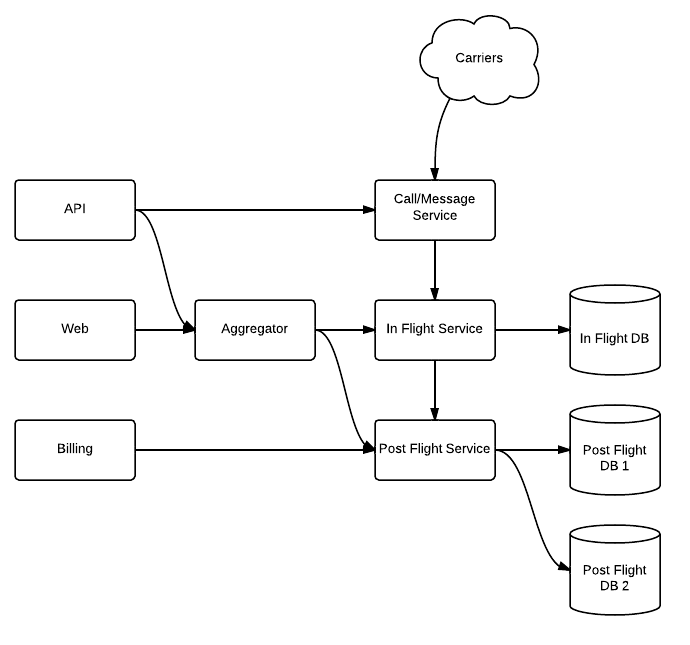
As a telecommunications company, any changes we make to our system need to happen online with 0 downtime. Otherwise, we will drop calls, fail to send messages and most importantly fail to meet the level of quality our customers expect. To make this change safely, the rollout needed to be broken down and carried out in multiple phases of deployment that spanned the course of a few months.
Minimizing Risk
Much of the code we needed to replace was written without much documentation and within a context that had long been forgotten. While we could do our best to read through the code and port all necessary behavior, line by line, it’s inevitable that something will be lost in translation. Fortunately, we had already developed a great tool, Shadow, which serves as a proxy between two different versions of an HTTP service, a known stable version and an experimental version.
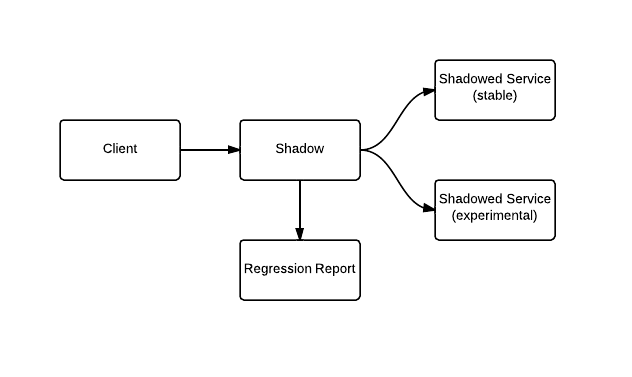
Clients send requests to shadow, which proxies the same requests to both versions of the service, reporting any differences and only serving the response from the known stable version to the client. This allowed us to do our best in porting everything we knew and catch regressions in production without impacting any traffic.
We also used "Account Flags", which are bits in a database that allow runtime determination of which code path a given request routes through. This allowed us to slowly turn the new system on for some customers without disrupting service for others if the new code path was defective.
Putting the Services in Place
The first phase involved putting the service abstractions in between clients and the databases, so that when we carried out the in-flight post-flight split and performed the sharding, only the service talking directly to the databases would need to change.
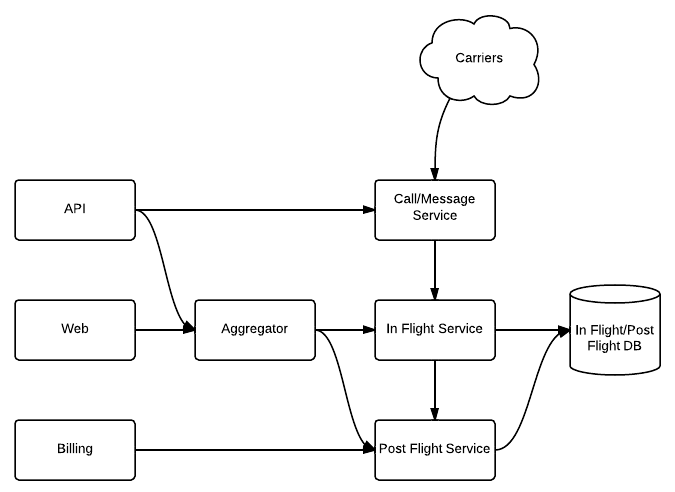
In the above case, we have three clients, API, Web and Billing. API and Web need to deal with both in-flight and post-flight data, whereas Billing needs to deal only with post-flight data. The Aggregator deals with combining in-flight and post-flight data when necessary. For example, in our public API, the calls list resource returns a single result set containing both in-flight and post-flight records.
We shadowed the new topology for about a month. During that time, we observed the diffs, fixed bugs and iterated until the services behaved in exactly the same way as the original design.
Splitting the In-Flight and Post-Flight Databases
Once we updated all clients to talk to the service abstractions, rather than the databases, splitting the in-flight data and post-flight data was a straightforward process of bringing up a new database dedicated to the storage of in-flight data and pointing the in-flight service at it.
Sharding the Post Flight Database
The last piece of the rollout was sharding, which needed to be broken out into multiple steps in order to execute in a way that did not disrupt our service. The first step involved putting the routing logic between the post-flight service and the database.
Shard Routing
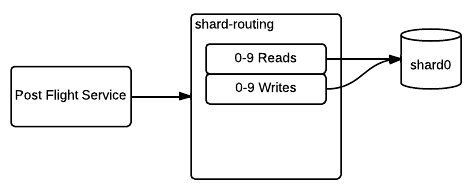
This example uses an imaginary keyspace of 0-9. Because our service is a large distributed system composed of many independently-acting machines and processes, we defined separate routing for reads and writes. Without splitting the reads and writes, during the migration there is potential to be in a state where data is written to the new shard by one thread, but read from the old shard by a thread that has not yet updated its routing. While we could have come up with a clever solution to synchronize the routing across all nodes and threads, it’s much simpler to move the reads over first, verify that all reads are going to the new shard, then move the writes over.
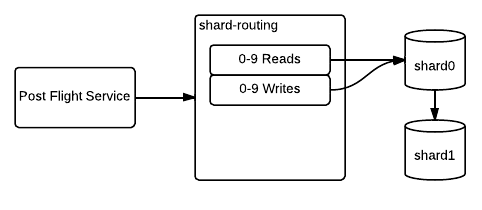
Bringing up the New Shard
The new shard is brought up slaving off the existing cluster. This is to ensure all data is immediately available on the new shard once we cut over. Otherwise, we would need to migrate data written to shard0 that should belong on shard1 once the shards are fully split. Clients would, for the course of the sharding, experience a sort of "data amnesia".
Routing to the New Shard
Next, reads are moved over for the subset of the keyspace shard1 will be responsible for (4-9 in this example).
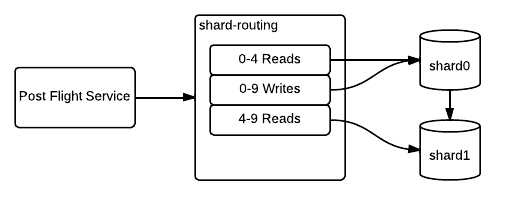
The next step is to move writes over; however there is a problem. In some of our tables, we use AUTO_INCREMENT to generate unique identifiers per row. By default, the sequence used for these identifiers increases by 1 with each new row. The sequence is local to a single master, so if we start writing to shard1 while it’s slaving off of the shard0 cluster, we’ll get collisions.
Avoiding Collisions
Luckily, MySQL allows us to configure the starting offset of the sequence and the amount by which the sequence is incremented for each new value. On the shard0 master, we set auto_increment_offset=1 and auto_increment_increment=2. On the shard1 master, we set auto_increment_offset=2 and auto_increment_increment=2. The effect of this is that shard0 will begin generating only odd ids and shard1 will begin generating only even ids, avoiding the collisions. Once these settings have taken effect, we can enable writes for the new shard.
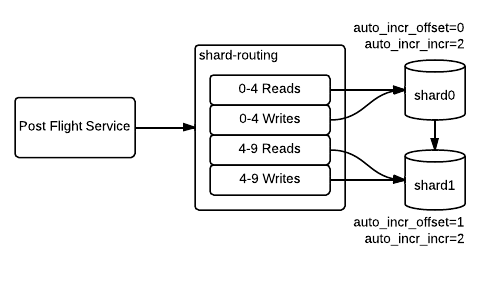
Once writes have fully moved over, we can cut the slave link and remove the odd/even split.
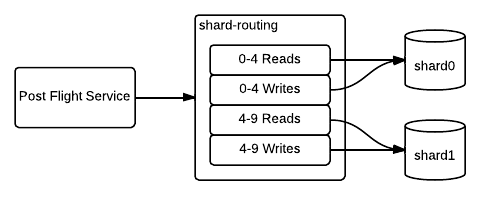
Data Deletion and De-fragmentation
At this point, both shards are storing data spanning the full keyspace, so we need to delete data that each shard is no longer responsible for.
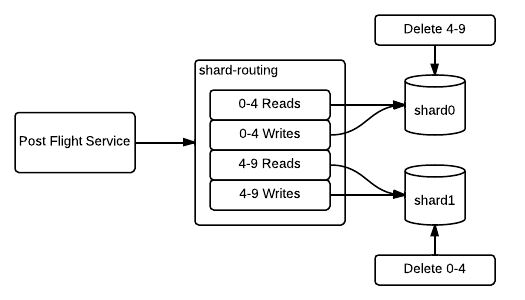
When deleting data in a MySQL table, the data is deleted from the underlying data file, leaving holes, but space is not given back to the operating system, leaving the file bloated and fragmented. Our databases use InnoDB’s file-per-table mode, which allows de-fragmentation by rebuilding the target table, which we do as a final step.
Lessons Learned
Out of everything our team learned going through all of this, these lessons stand out the most and will inform how we design future systems and carry out future operations.
- The Butterfly Effect. Early design decisions and technology choices have massive long term consequences. Think At Scale when designing new services - consider all options and weigh the long-term tradeoffs carefully. Is that database query or architecture going to be a big pain point at 10x your current scale? 100x? 1,000x? An ounce of prevention can avoid a world of problems if you design for the future.
- Service oriented architecture serves as a great way to decompose a system into discrete units of functionality with clear ownership and responsibility. When there is ambiguity around who owns a particular service or piece of the stack, it’s a sign it can be decomposed further.
- Making changes to the architecture of a stateful distributed system while it is running is incredibly complex to orchestrate. Tools like shadow, automation around risky operational tasks, and a slow and steady hand were critical to execute this rollout with confidence.



Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.