How to Scrape Websites With PHP Using Goutte
Time to read:
November 11, 2021
Written by
Reviewed by

For many PHP based applications involving data collection or data analysis, PHP scripts will need to scrape data from external web pages. This is especially true if the web source that you are looking to interact with doesn’t provide an API; or maybe they do provide an API, but you don’t want to pay for their API services.
Web scraping is usually performed with Node.js or Python, however, when trying to scrape data and pass it to the frontend, web scraping with Node.js or Python complicates the process of scraping data from the web and displaying it on a web page.
This is where Goutte makes life easier. Instead of relying on Node.js or Python scripts to scrape data from the web and display it on the frontend by passing it to a PHP script, with Goutte, you can scrape data from the web directly inside of your PHP script.
Goutte is a lightweight web scraping library, so passing scraped data to the frontend doesn't significantly increase loading time, nor does it take up too much RAM in the backend.
Functionality
Since Goutte is a lightweight library not intended to handle heavy processes, it has limited functionality compared to more heavyweight web scraping libraries. Goutte's functionality includes:
- Finding HTML elements through their CSS selector or HTML tag
- Extracting text from HTML elements
- Clicking links and filling out forms
In this article, you will learn how to use Goutte's functionality for different purposes through practical code examples.
Prerequisites
To follow this tutorial you'll need the following:
- Composer installed globally.
Setup
Before installing Goutte, you'll need to create the project directory and navigate into it, by running the commands below.
Installation
To add Goutte as a project dependency, run the following command in your project's terminal:
Working with Goutte
Let’s start with the most practical use case of Goutte: text extraction. First things first, using your preferred editor or IDE, create a new PHP script inside of your project directory called scrape.php. To require and initialize the Goutte library inside scrape.php, add the following 3 lines of code to the beginning of the script:
Now that Goutte is initialized, add the two lines below to the end of the file to fetch a URL using the client->request() function.
I've chosen the URL destination to be the BBC stock market news website because it has valuable text information that you can extract using Goutte.
Finding elements
Let's try and scrape today's top stock market news headline as displayed on this web page. First, you will need a way to find the DOM (Document Object Model) element containing the first headline. You can do this by right-clicking on the first headline and clicking on the Inspect option, which you can see an example of in the screenshot below.
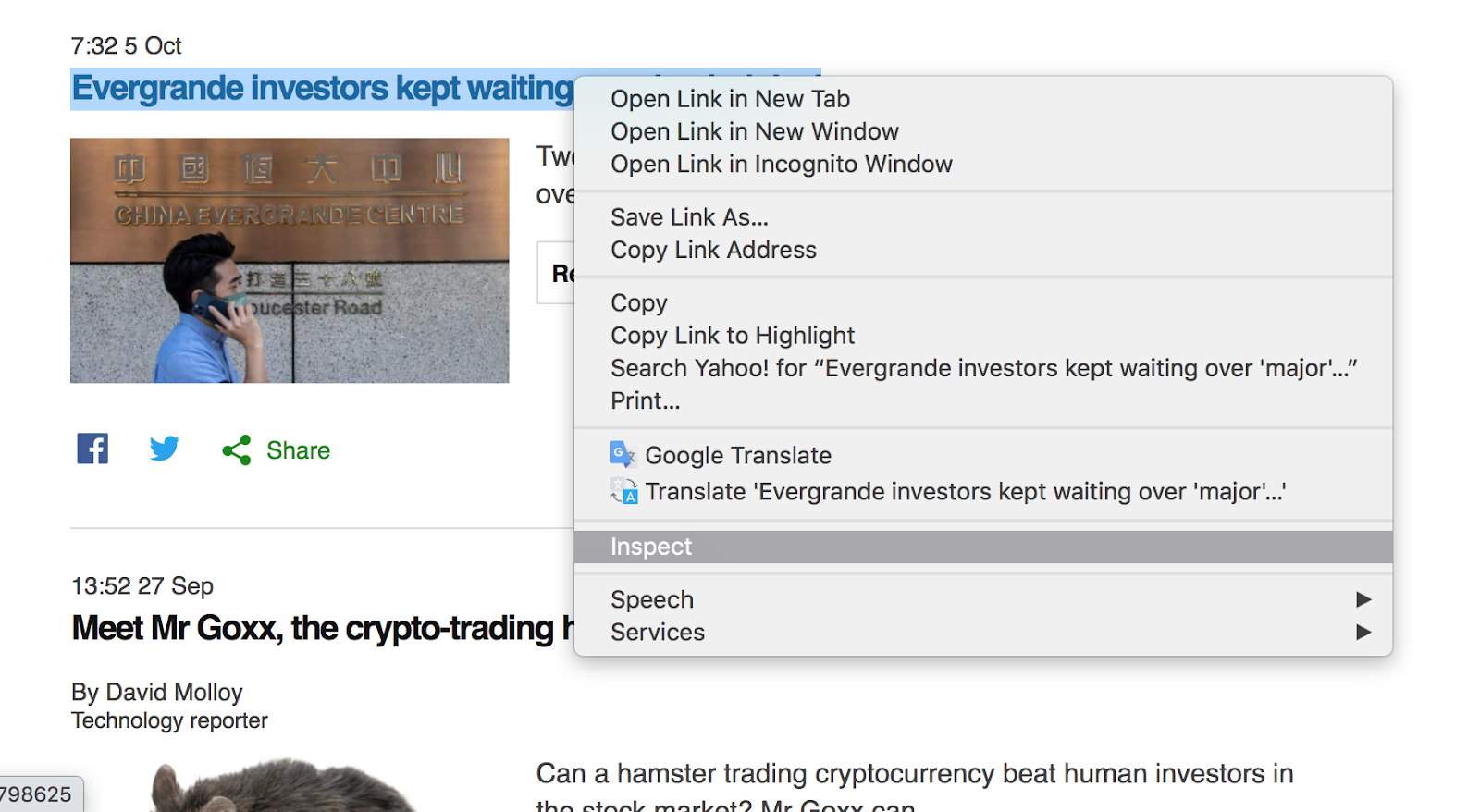
A pop-up will then appear on the right of your screen, with the selected headline's DOM element highlighted in blue.
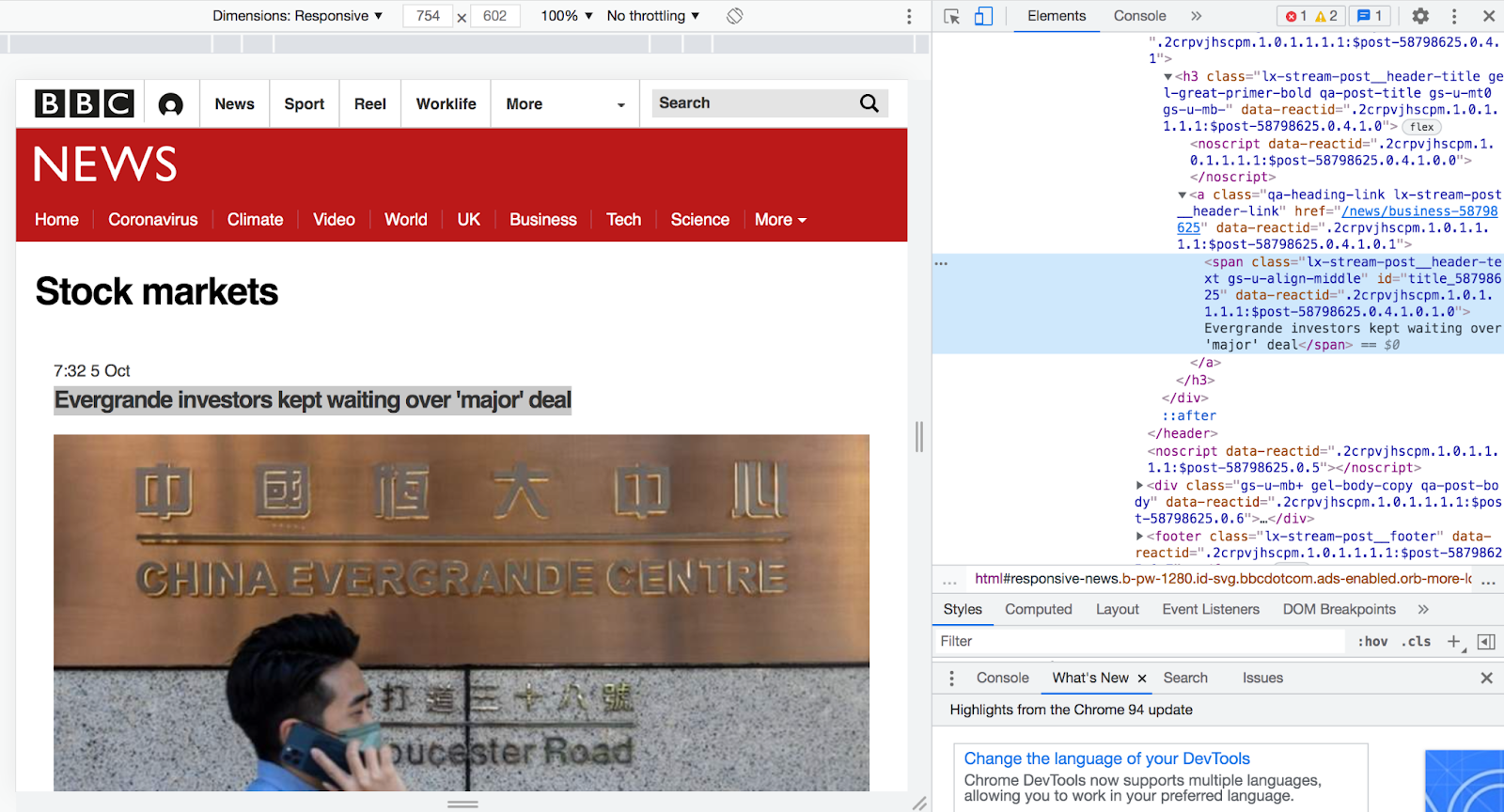
To access this element through Goutte, you can use the element's CSS selector. A selector is, in simple terms, the address of an element within a web page and is used for accessing a specific element inside the DOM. To get the selector of the highlighted element, in Chrome or Safari's Elements tab, or Firefox's Inspector tab, right-click on the element, hover over Copy, and click Copy selector in the dropdown.
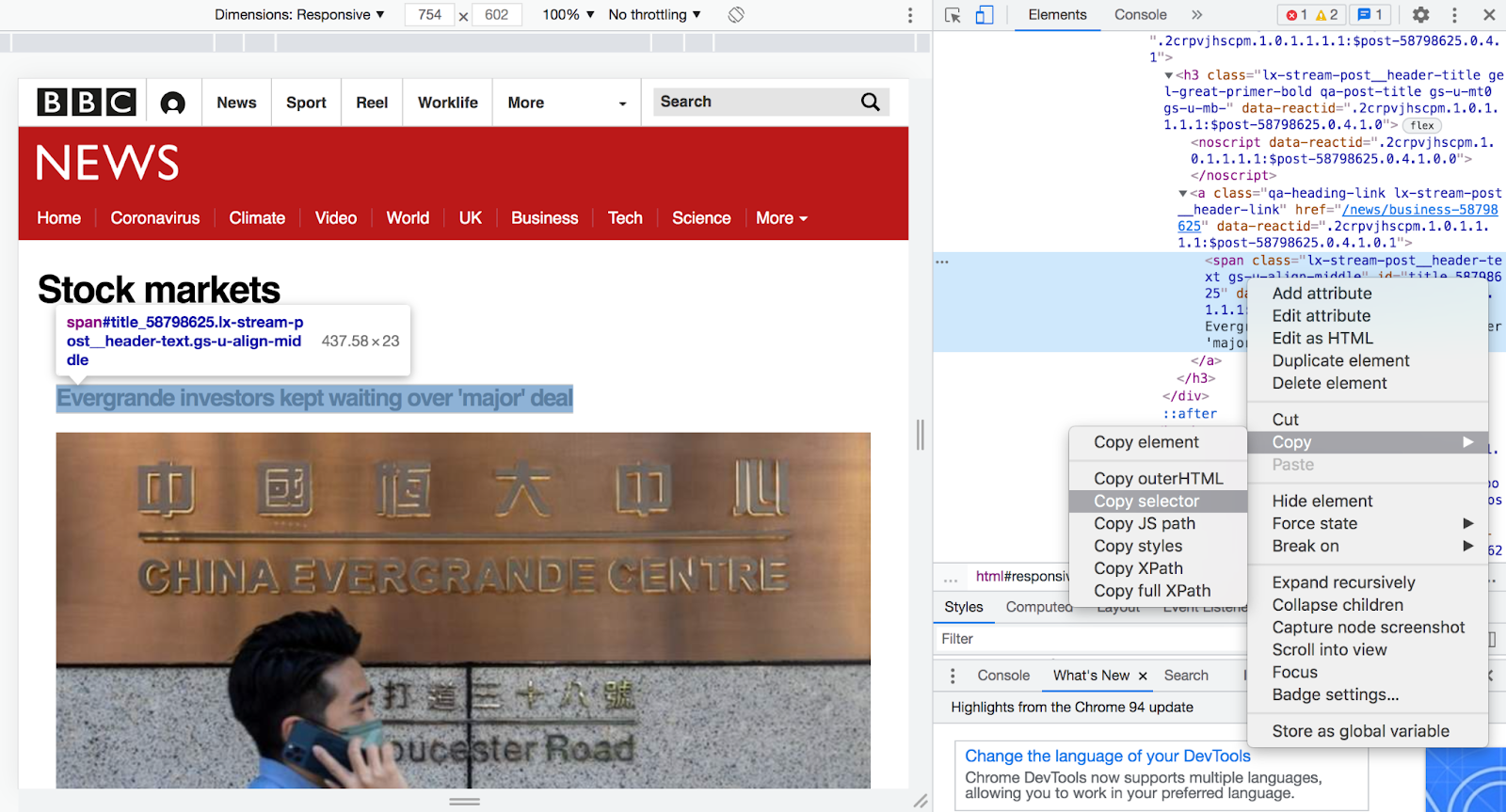
If you take a look at the copied selector by pasting it, it may seem random at first glance, but it can actually be identified using its path or id property. This particular element's selector is #title_58798625. This is because this element's id is title_58798625, which you can see in the screenshot below.
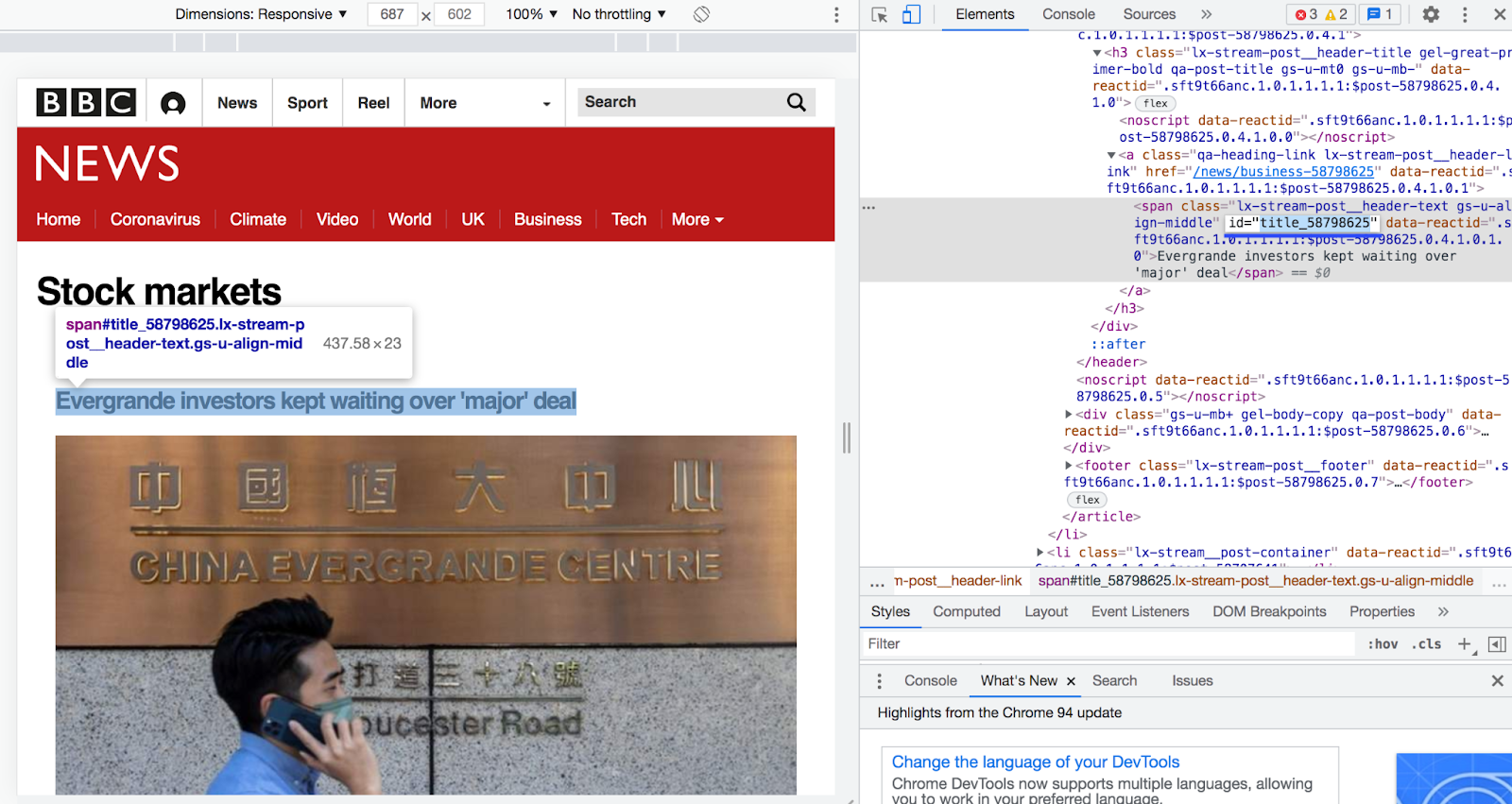
If present, an element's id will determine its selector. Note that the selector will have a "#" before the id as seen with this example element. If we take an element that doesn't have an id on the other hand, its selector will look something like the following:
As you can see, the selector of an element with no id will simply reflect its path from the body tag. The above element's selector indicates that it is located inside an a tag, located inside a parent div tag, located inside another parent div tag.
Extracting an element's text contents
Now that you've copied the first headline's selector, add the two lines below to the end of scrape.php, replacing <headline's selector> with the selector that you've just copied in your browser.
The code will be able to find the element within the web page by using the filter() function and will then be able to extract its text contents using the text() function, before finally displaying the extracted text contents. If you run the above code by running php scrape.php, you should see that it displays the top news headline from the BBC stock market news web page, as in the example below.
You can follow the same process to fetch multiple news headlines and display their extracted text contents. Use the following code, replacing the placeholders with their respective selectors, to display the text contents of multiple headline elements.
If you run the code again, you should see output similar to the example below.
Scraping elements using HTML tags
Another faster, but messier, method of scraping elements is by using their HTML tag. For example, using the code below, you can return the text contents of the web page's first h1 tag.
Goutte could also return the text contents of all the h3 tags inside this web page using the each() function. To do that, update scrape.php to match the revised code below.
Running the code again should give you output similar to the example below.
The reason this method is messy is because it can output lots of unwanted data which could be contained within the same type of HTML tag. Luckily, in the case of this web page, every h3 tag inside it contains a news headline but no excess data. Using the same method, you can also find elements inside a certain array of parent HTML tags. For example, you can retrieve the text contents of all the p tags that appear inside two parent div tags inside this web page, by updating the code in scrape.php to match the code below:
Running the code again should give you output similar to the example below, which was shortened for brevity's sake.
Scraping and displaying innerHTML
It is also possible to parse a scraped element's innerHTML. Let's try parsing the innerHTML of the menu bar at the top of this web page by first copying its CSS selector.
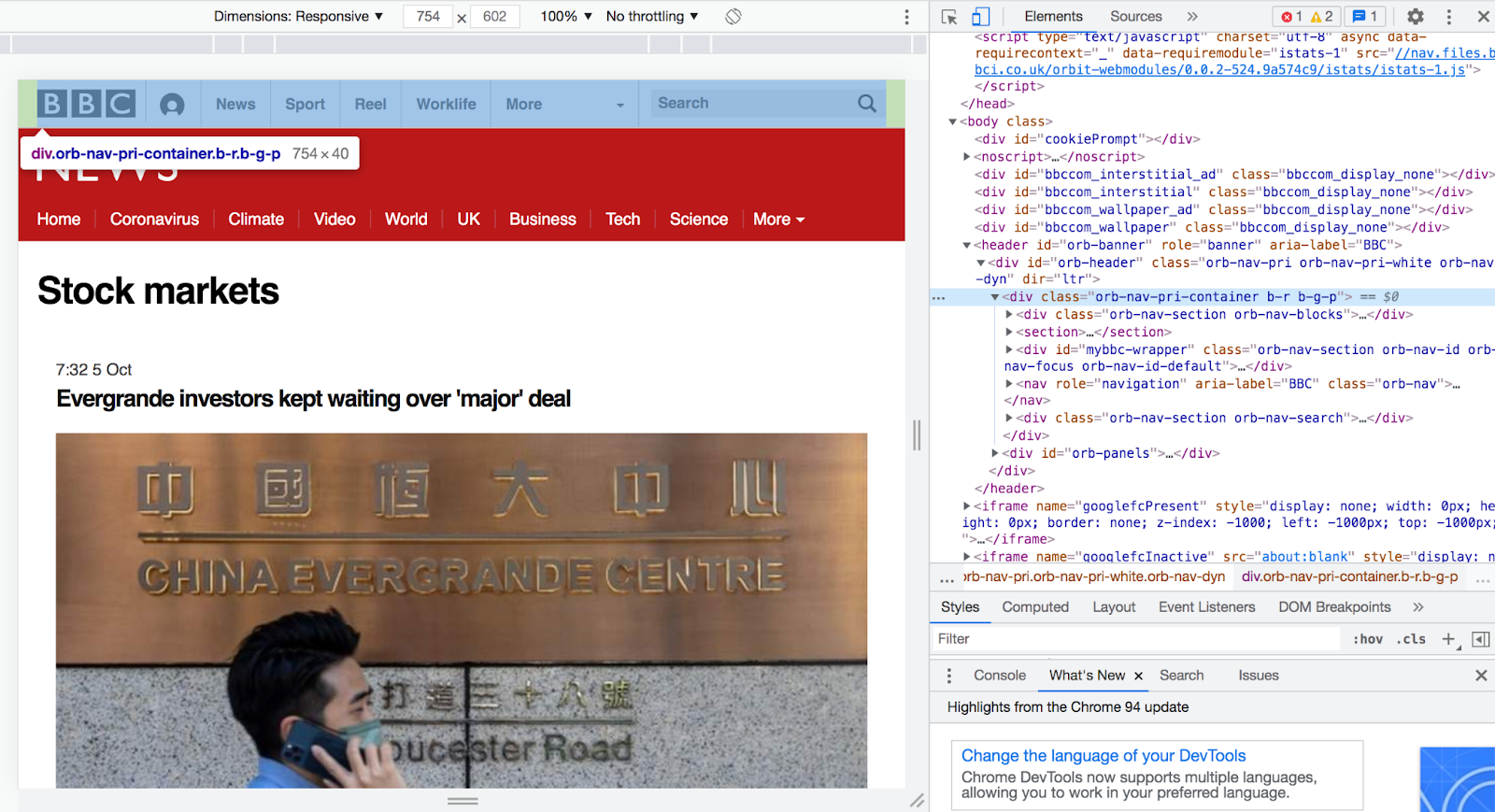
To parse this element's innerHTML, you must use the html() function instead of the text() function which you used earlier. Update scrape.php to match the code below, replacing <menu bar's selector> with the menu bar's CSS selector.
Running scrape.php again will display the innerHTML of this element, which you can see in the example output below, which I've truncated since it is too long to include in the article.
Interactive web scraping
Even though Goutte's interactive web scraping capabilities are very limited compared to more heavyweight web scraping libraries such as Puppeteer or Selenium. However, it can still do two things very well when it comes to interacting with a web page:
- Clicking on links
- Filling out and submitting forms
The first news headline displayed on the BBC stock market news web page is inside an a tag, which means that this headline acts as a link. Let's try clicking on the first news headline and getting the clicked link's destination's headline element.
The below screenshot shows the link destination's headline element.
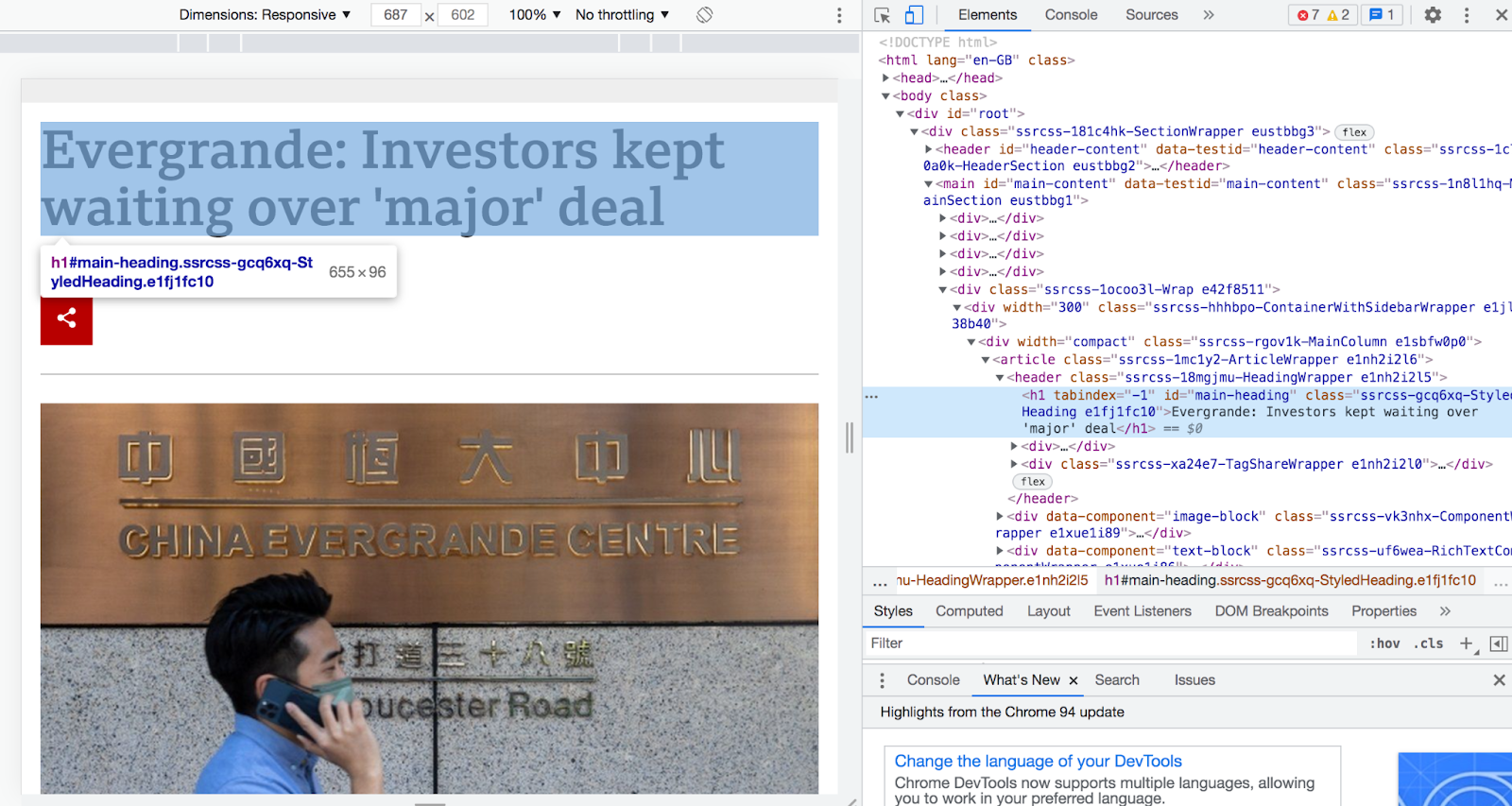
To find the headline element through Goutte, copy the element's CSS selector. This element has an id property of main-heading, so this element's selector will conveniently be defined as #main-heading. Then, update scrape.php to match the following code, replacing the placeholders with appropriate selectors, to click on the first headline and display the link destination's headline’s text contents.
Unfortunately, finding a link through its text contents is the only way Goutte is able to recognise links and can't use selectors like when fetching elements. The $crawler variable is effectively changed to the URL address of the clicked link. By doing this, this code fetches the headline from this link's destination through its selector and displays it's text contents.
If you run scrape.php again, you should get output similar to the example output below.
Submitting forms
You can also submit forms through Goutte. As a working example, we're going to make scrape.php fill-in and submit GitHub's sign in form by clicking the Sign in button at the top right of GitHub's home page, and then fill-in and submit the email and password fields once redirected to the sign in form.
Just like links, Goutte can only find buttons through their text contents. Using the following code, Goutte will first find and click the Sign in button through its text contents before submitting the sign-in form.
To identify the input elements that you’d like your PHP script to find and fill-in once redirected to the sign in form, you must use their name attributes. I've highlighted them blue in the screenshots below.
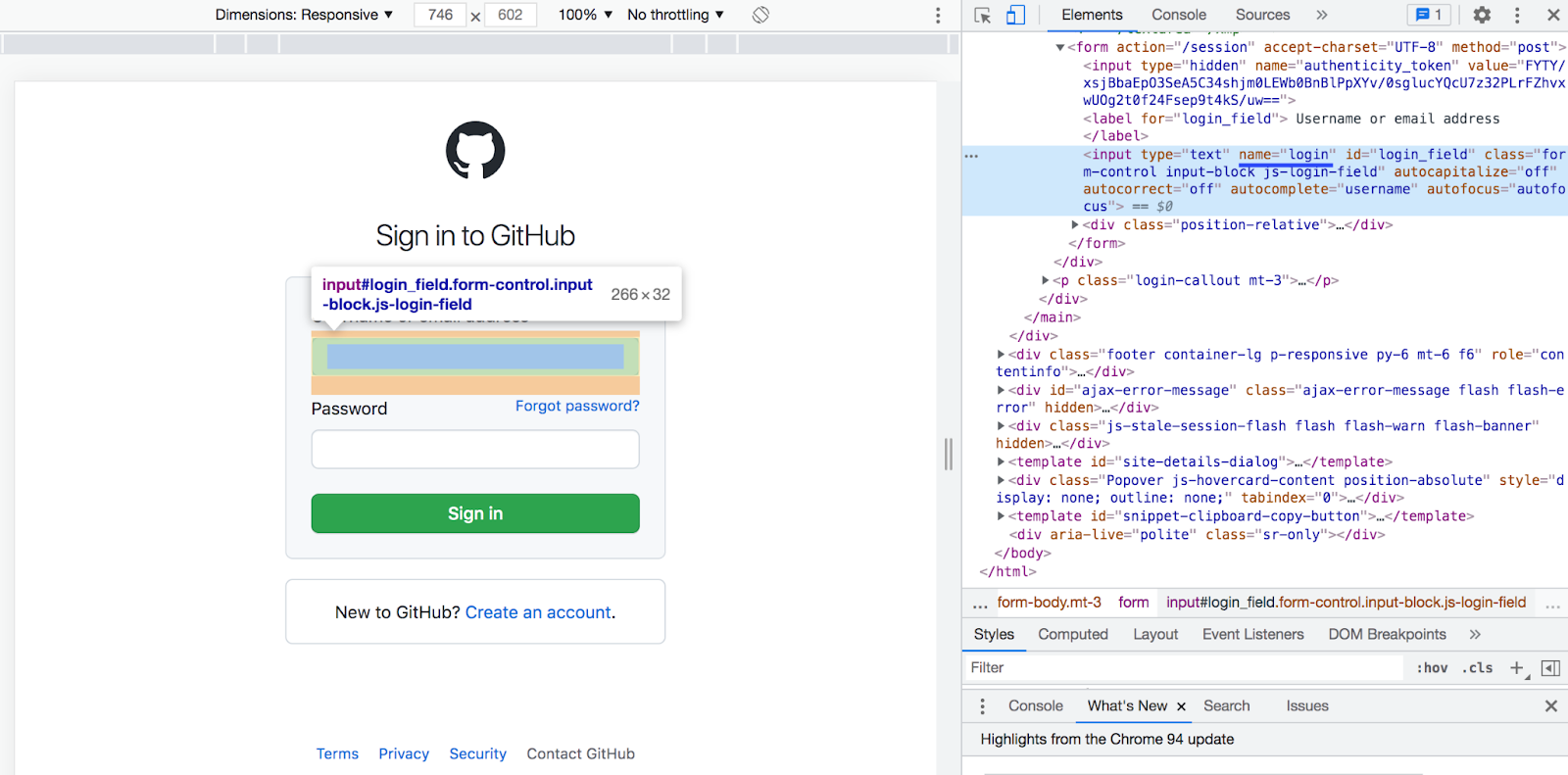
In the screenshot above the name attribute has the value "login".
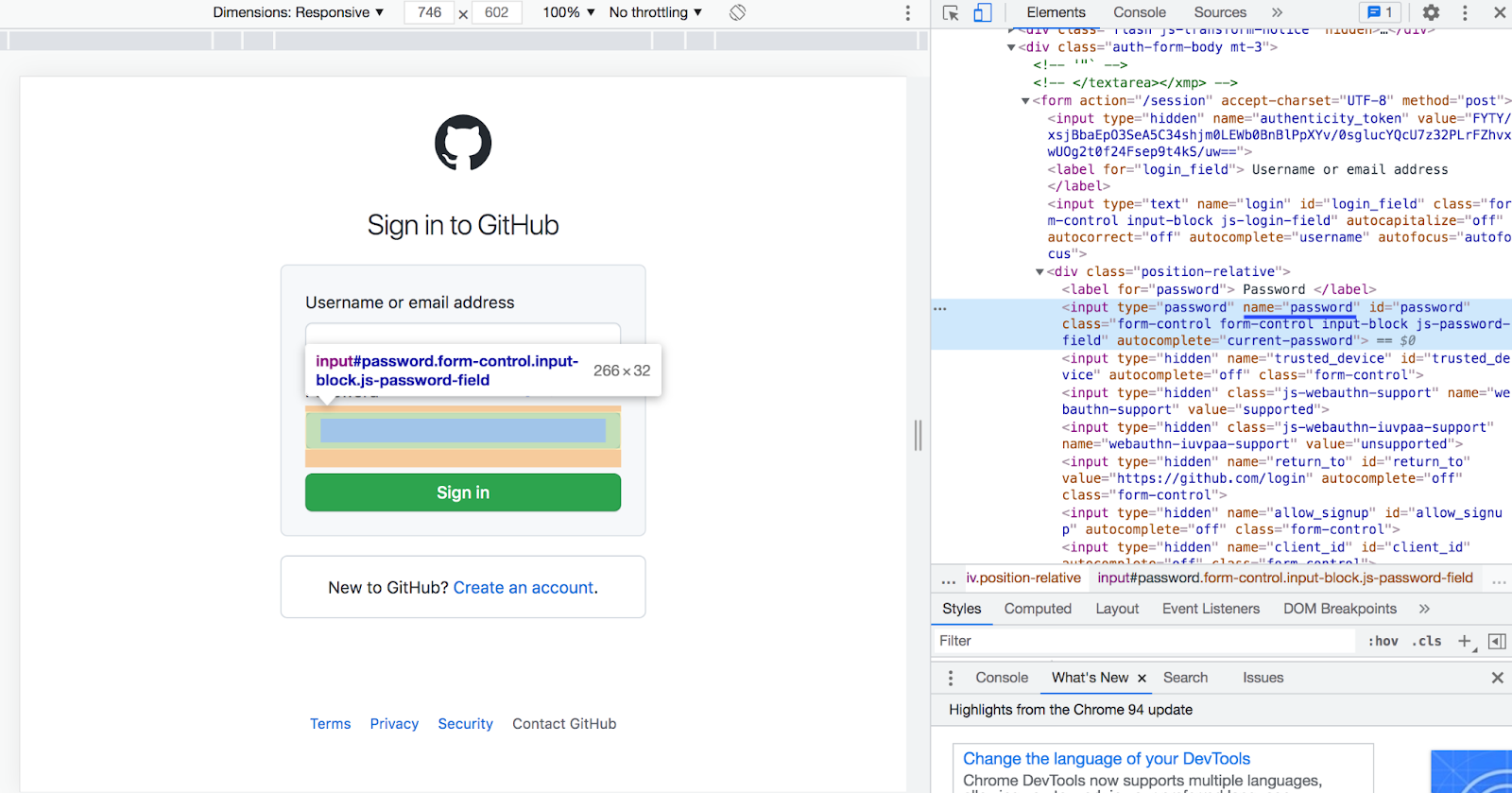
In the screenshot above the name attribute has the value ”password”.
Using the code below, scrape.php will be able to:
- Open https://github.com.
- Select the button whose text contents is "Sign in".
- Once redirected to the sign in form, fill-in each of the needed fields by recognising their name property, and finally submit the form.
- If successfully signed in, once redirected to your GitHub account's home page, scrape and display the first
h1tag inside this web page, to confirm that Goutte has signed in.
Update scrape.php to match the code above, and then run it again. The output should match the example below.
Now, let's make one, final, change, where you specify what you'd like code to fill-in inside the specified input elements. In example below, I've simply put the "your email" and "your password" values for these input fields.
Wrapping up
I hope that this article was successful in demonstrating how you can scrape external web pages' data in PHP using the Goutte library. Happy scraping!
Matt Nikonorov is a developer from Kazakhstan with a passion for data science, data mining and machine learning. He loves developing web and desktop applications to make the world more interesting. When he’s not developing, you can reach him via Twitter.


Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.