Web Scraping and Parsing HTML in Swift with Kanna and Alamofire
Time to read:
August 18, 2016
Written by
This post is part of Twilio’s archive and may contain outdated information. We’re always building something new, so be sure to check out our latest posts for the most up-to-date insights.

When building iOS applications, we often need to work with data from various APIs. But sometimes the data you want access to isn’t nicely packaged and available via a REST API. In these cases we can scrape data directly from a web page using the Kanna Swift library.
Let’s build an iOS app that will display all of the upcoming metal shows in New York City by scraping the NYC Metal Scene website.
Getting started and setting up our project
Start off by cloning this repository which contains a starter project for us to build on. This project already has a storyboard set up with a UITableView that we will use to display the data we scrape. I am using XCode version 7.3 and Swift version 2.2, so make sure this code is compatible with your version of XCode and Swift.
Open your terminal and navigate to where you want this project to live. Enter the following command to clone it, you can also download a zip file of the project:
We are going to use CocoaPods to install the dependencies we’ll need for this project. Install CocoaPods if you don’t have it:
CocoaPods takes care of linking all of the frameworks for you by creating a new Xcode Workspace. From now on when opening the project in Xcode, you’ll have to use UpcomingMetalShows.xcworkspace instead of your normal Xcode project:
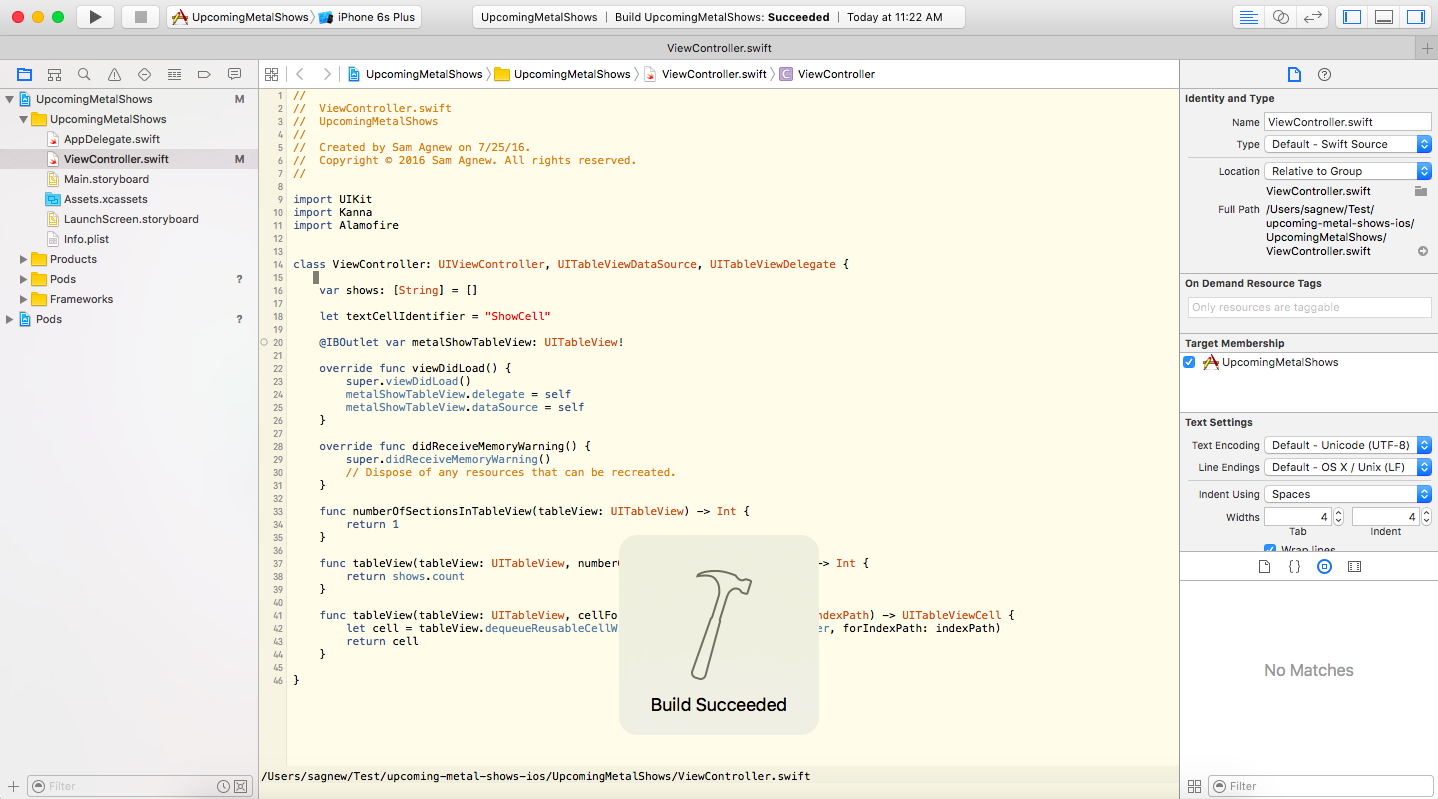
You can check that Kanna and Alamofire were installed correctly by adding these two lines to ViewController.swift:
Press “Command-B.” to verify the project builds with those dependencies referenced.
Scraping data from a web page using Alamofire
With the starter project in place we can move on to the next step in building the app, making the HTTP request to acquire the concert data. In our case we want to make a request to http://nycmetalscene.com/ and scrape the HTML content that is returned.
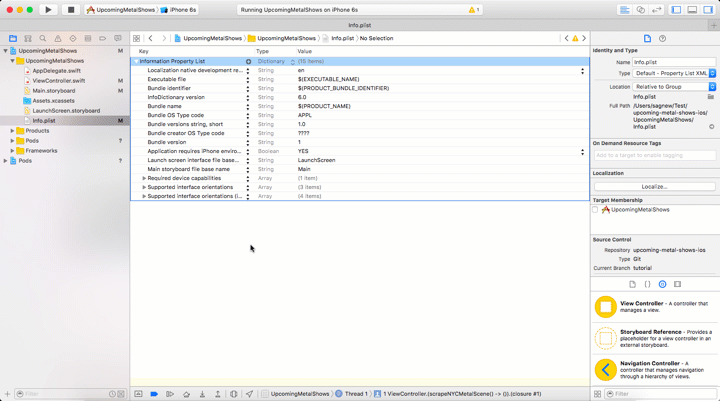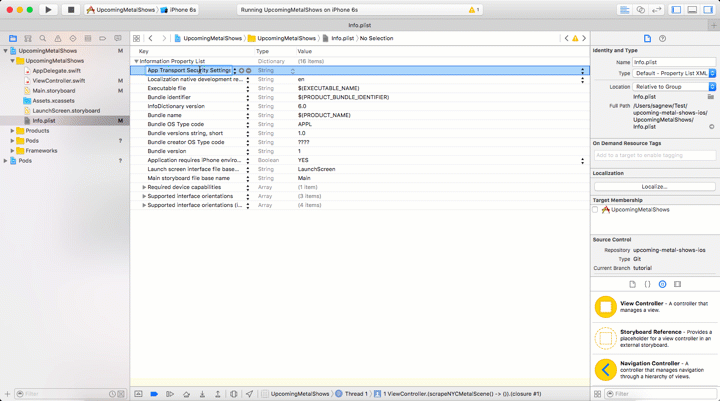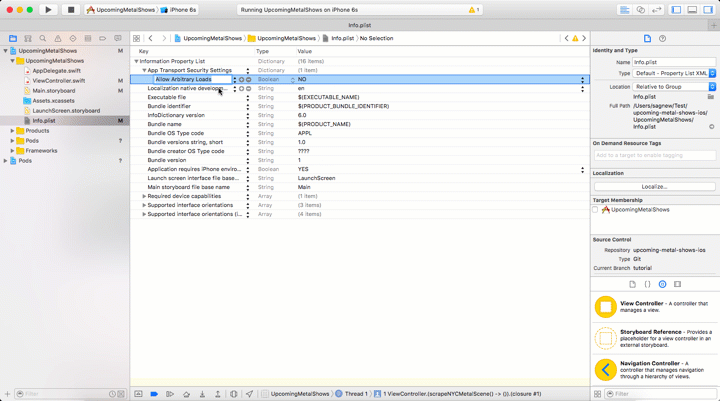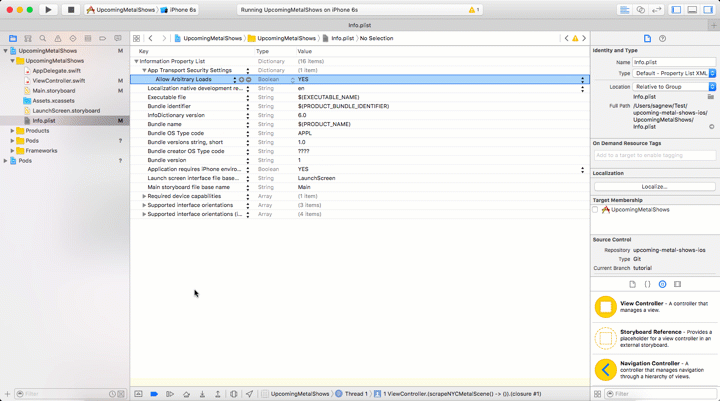
Before making the request we have to configure our app to allow making an HTTP request to a non-secure website, or a website that is not accessible via HTTPS. Starting in iOS 9, Apple enabled App Transport Security which by default disallows requests to non-secure websites. To make our app work we will need to add an exception to this policy by editing the Info.plist file.
Open Info.plist, add a new Key to the Information Property List called App Transport Security Settings and set the Allow Arbitrary Loads value to YES as seen in this GIF:
With the exception in place we can grab HTML from the page we are trying to scrape. To do this, we need to send a GET request with Alamofire.
Open your ViewController.swift and add the following code to the ViewController class:
The parseHTML(html: String) -> Void method will take the HTML from our GET request and use Kanna to make sense of it.
Trigger the loading of the data by adding a call to this new function at the end of viewDidLoad:
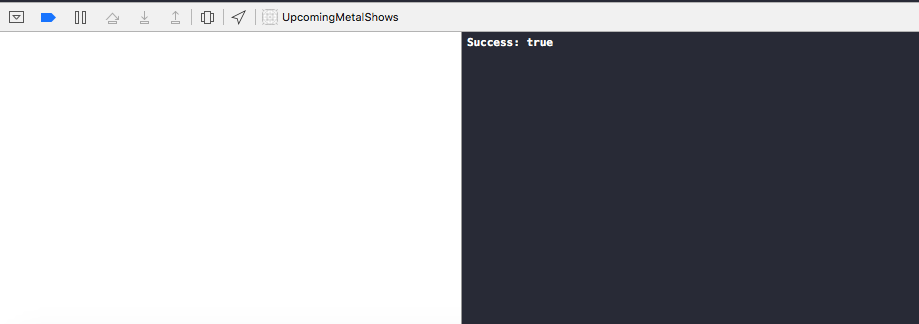
Now run the app again to see if the request is sent successfully
Parsing scraped data with Kanna
Before writing code to parse the content returned from the GET request, let’s first take a look at the HTML that’s rendered by the browser. Every web page is different, and sometimes getting data out of them requires a bit of pattern recognition and ingenuity.
In our case we want to grab all of the metal shows included in the markup.
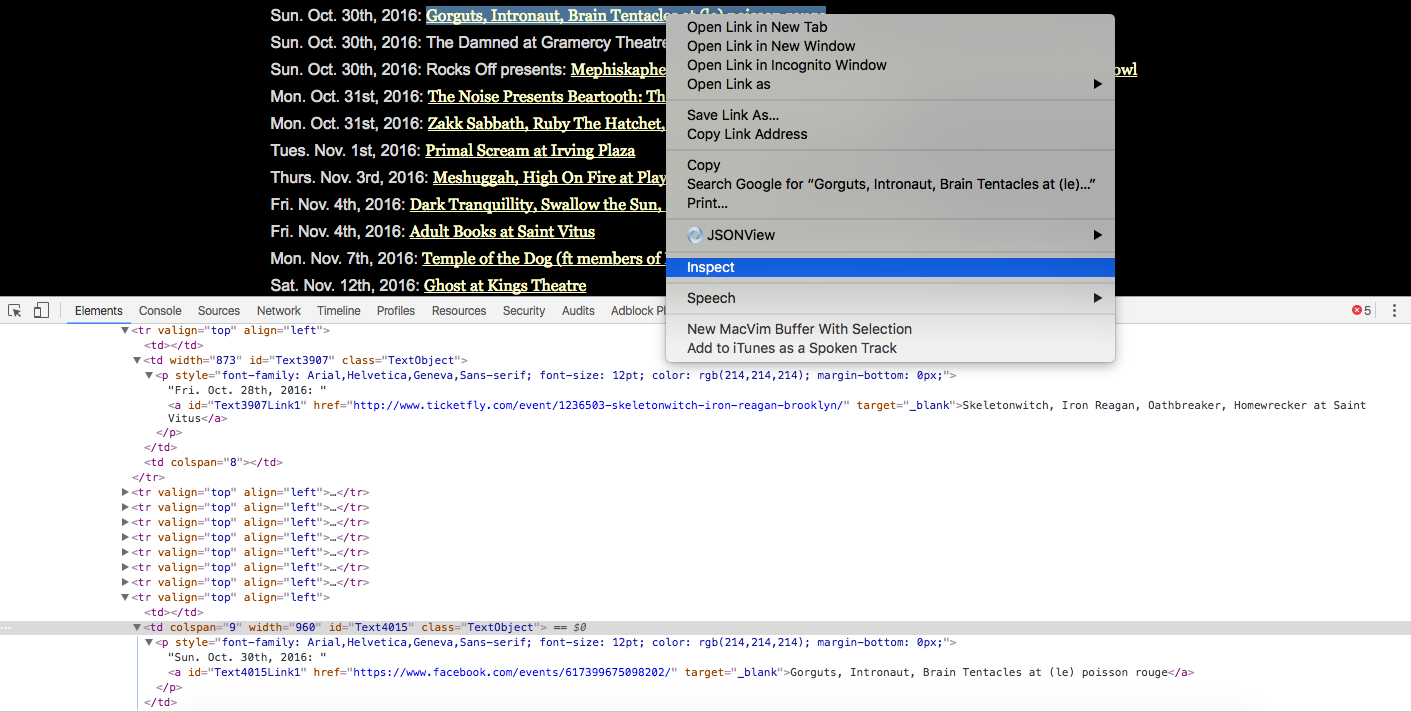
Each show exists in a td tag and has an ID of Text followed by some number. This is the first pattern we’ll use to grab the HTML elements that contain the show info.
Next, you may notice that every piece of text on the page follows that ID pattern, not just the shows. To extract just the text nodes for concerts, we will use a second regular expression to find text that begins with the first three letters of a weekday. This pattern indicates that the text is referring to a concert.
With the two patterns for extracting concert data we’re ready to parse the content. Using Kanna, developers can use CSS selectors or Xpath queries to navigate through the HTML in a document. Let’s use CSS selectors with a regular expression to find all td nodes that have an ID beginning with “Text.” Next we’ll loop over those results and apply the day-of-week regular expression.
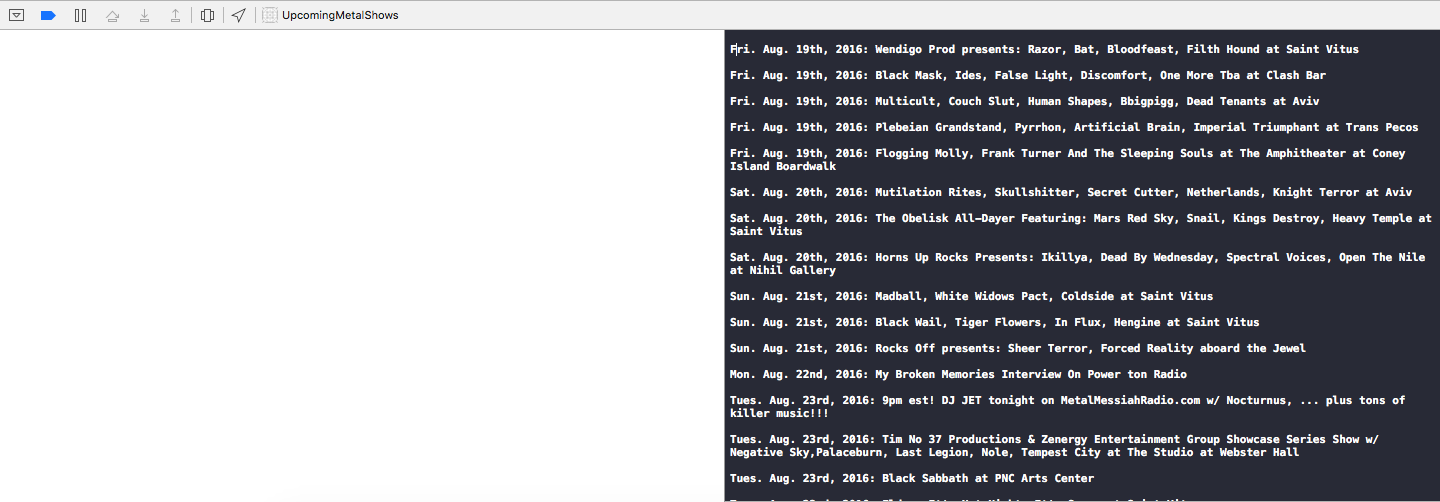
Edit the parseHTML method to contain the following example code that will print out the text for all of the shows on the page:
Run the app to see that it is printing out only the shows on the page and not all of the unnecessary text, similar what is shown in the following Xcode screenshot.
Next, we will work on displaying this data in the mobile app.
Displaying the data that we scraped in a UITableView
Let’s display all of the shows in a UITableView so we have an actual app.
The sample project already has one added to the application and configured in Main.storyboard, as well as the required methods in ViewController.swift. All we need to do is link our data to this view.
We are using the shows array as the data source for the UITableView. Add a line to the end of our parseHTML function to make sure that the data in the UITableView is being loaded once we are done parsing the shows:
We also need to define what data a cell in our table view contains. Replace the tableView(tableView: UITableView, cellForRowAtIndexPath indexPath: NSIndexPath) function with the following:
Now run the app and look at the list of upcoming metal shows in NYC

Wow it looks like Megadeth, Amon Amarth, Suicidal Tendencies, Metal Church and Havok are all playing the same show in October! Sounds like a pretty sick lineup.
The vast expanse of the World Wide Web
Now you can build apps using data that isn’t neatly available to you in the format of a publicly accessible API by just grabbing it from the Internet.
Beware that changes to a web page’s HTML might break your app, so make sure to keep your code up to date.
If you want to build with something that doesn’t require scraping data from old web pages, check out Twilio’s Video and IP Messaging iOS SDKs for adding video conferencing and real time chat to your Swift applications.
I’m looking forward to see what you build now that you have access to all of the data on any web page. Feel free to reach out for any questions or to show off what you built:
- Email: sagnew@twilio.com
- Twitter: @Sagnewshreds
- Github: Sagnew
- Twitch (streaming live code): Sagnewshreds

Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.