HTTP Requests in Python 3
Time to read:
December 06, 2016
Written by

The Python Package Index (PyPI) is home to almost 100,000 code library packages that help Python programmers accomplish many tasks ranging from building web applications to analyzing data. PyPI is also home to many helper libraries for APIs such as Twilio.
Let’s demonstrate the power of PyPI packages by taking look at how to retrieve and parse JSON results from a RESTful API using four different Python HTTP libraries.
Each example in this post will:
- Define a URL to be parsed. We’ll use the Spotify API because it allows requests without authentication.
- Make an HTTP GET request to that URL.
- Parse the JSON result.
All four of these libraries provide a different path to the same destination; if you pprint the results, you’ll see a dictionary with Spotify search results:
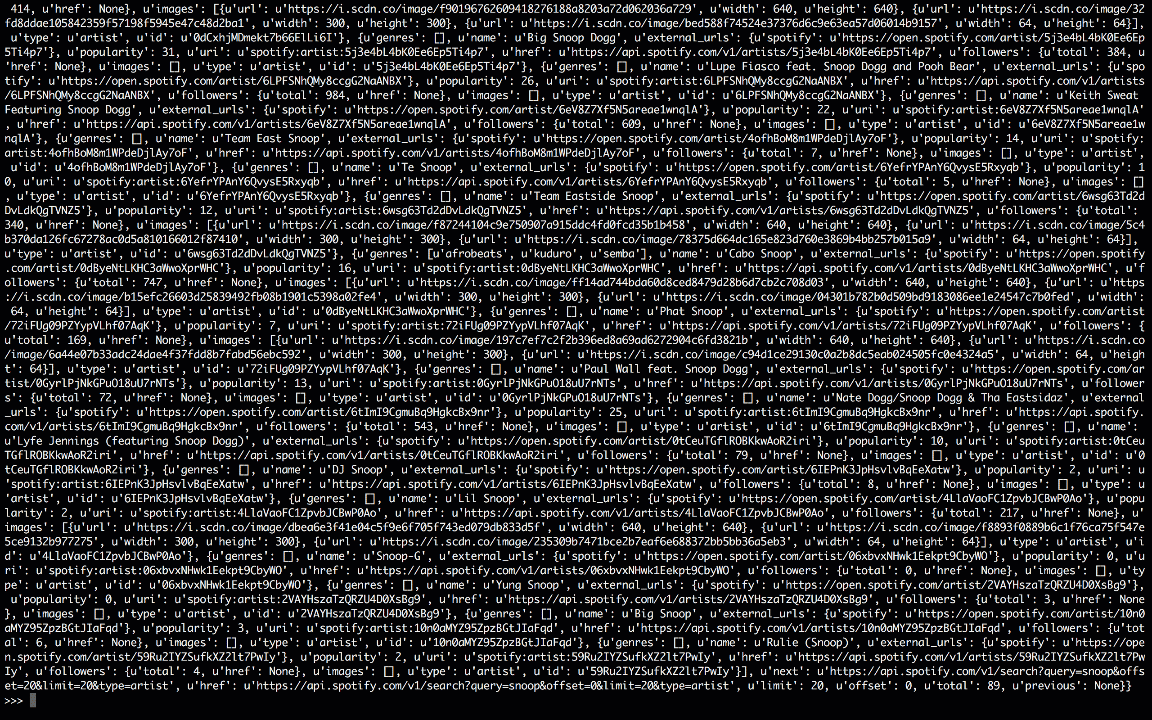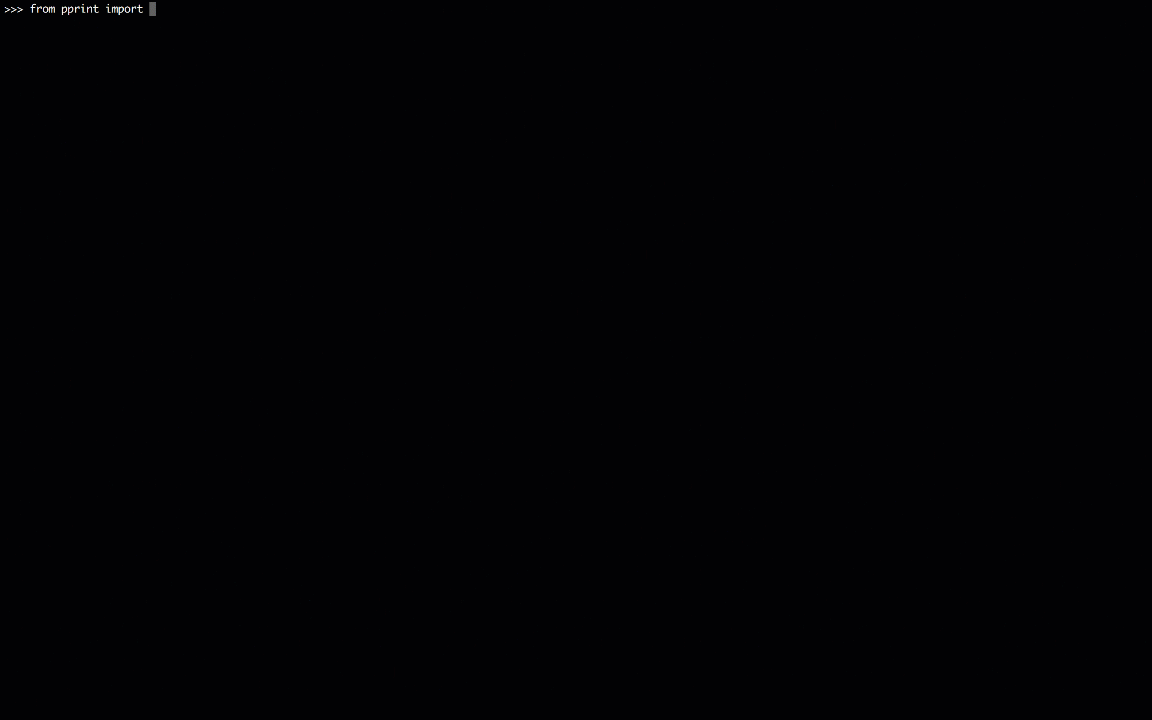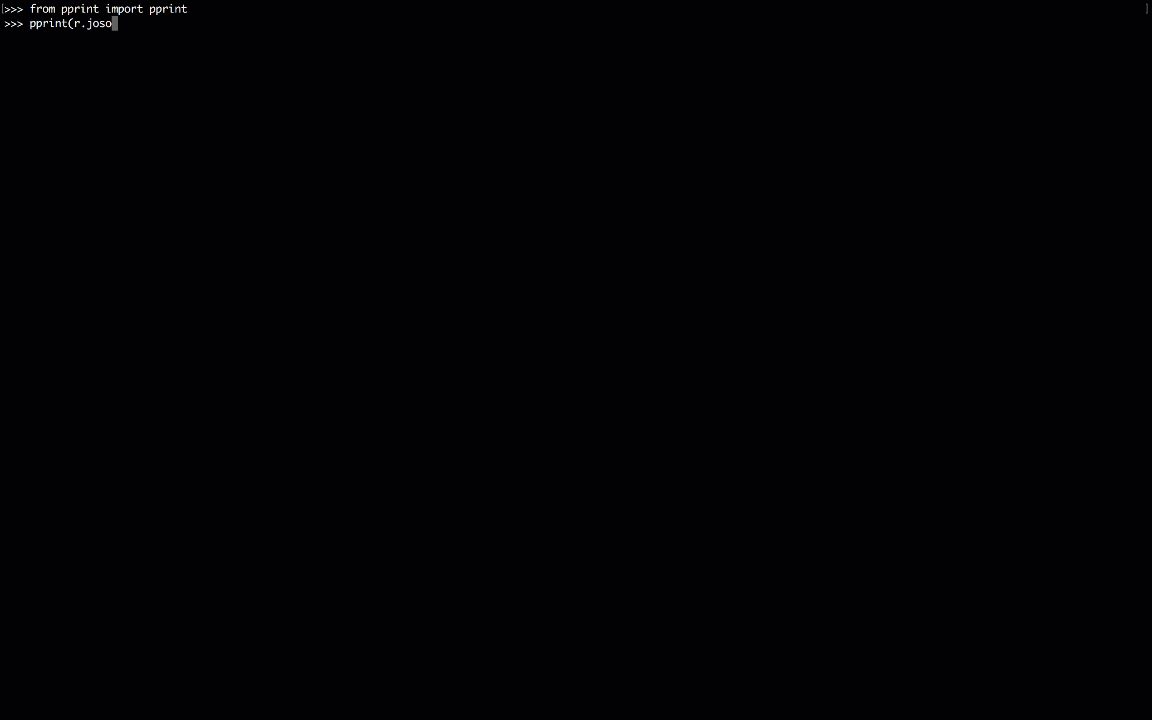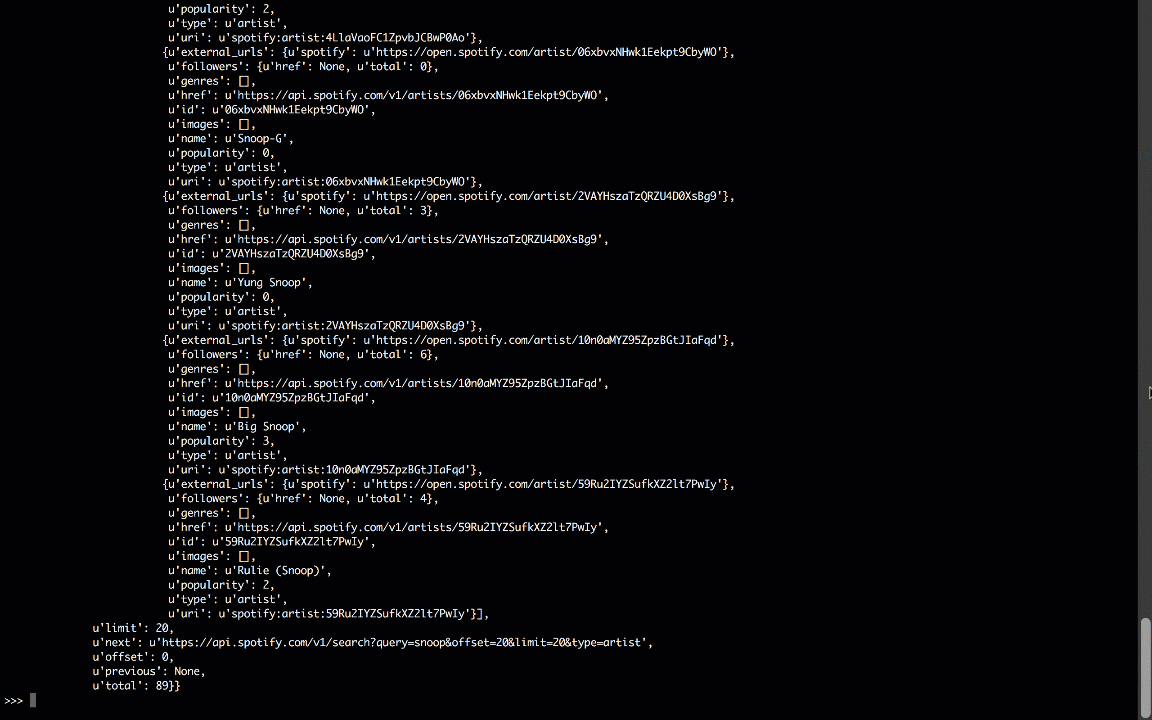
*Notice: Results may vary depending on which version of Python you’re using. In this post, we will use Python 3 for all of the examples. Consider setting up a virtualenv for Python 3 if you are still running Python 2.X system wide.
The following instructions will help you use virtualenv with Python 3:
- Create a directory called
pythreetestfor your Python 3 testing. - Once virtualenv is installed execute the following commands from within the project directory:
Create a new virtualenv with the following command:
Activate myvenv using the source command:
Now you will be able to pip install libraries and start an interpreter using Python 3 inside the virtualenv where you can successfully import packages.
urllib
urllib is a module built into the Python standard library and uses http.client which implements the client side of HTTP and HTTPS protocols. There’s no pip install required because urllib is distributed and installed with Python. If you value stability, this is for you. The twilio-python helper library uses urllib.
urllib can require more work than using the libraries built on top of it. For example, you have to create a URL object before making the HTTP request.
In the above example, we sent our request URL to the stdin of a CGI and read the data it returned to us.
Requests
Requests is a favorite library in the Python community because it is concise and easy to use. Requests is powered by urllib3 and jokingly claims to be the “The only Non-GMO HTTP library for Python, safe for human consumption.”
Requests abstracts a lot of boilerplate code and makes HTTP requests simpler than using the built-in urllib library.
Begin with the pip install:
Make a request to Spotify:
For pretty printing:
We just made a GET request to our Spotify webpage creating a Response object called r. Then, we use the builtin JSON decoder to deal with the content of our request.
Octopus
Octopus is for the developer who wants to GET all the things. What if you want to make multiple requests to Spotify at the same time while working on your awesome new karaoke app? Much like its namesake, this library uses threads to concurrently retrieve and report on the completion of HTTP requests by using the familiar Requests library.
Alternatively, you can use Tornado’s IOLoop to asynchronously perform requests, but we won’t attempt that here.
Install it via pip:
Setup for Octopus is slightly more involved than our previous requests. We have to build a response handler and JSON encode the result using the built in JSON library.
In the snippet above, we define the function create_requests to use threaded Octopus requests. We start with an empty list, data, and create an instance of the Octopus class otto. We’ve configured it with the default settings from the documentation.
Then we build response handler where the response argument is an instance of Octopus.Response. Following each successful request, the response content will be added to our data list. With the handler in place we can use the main method in the Octopus class, .enqueue. This method is used to enqueue new URLs.
We specify the .wait method to wait for all the URLs in the queue to finish loading before we JSON encode our Python list and pprint the results.
Whew!

HTTPie
HTTPie is for the developer who wants to interact with HTTP servers, RESTful APIs, and web services fast – like one line of code fast. This library is “an open source CLI HTTP client that will make you smile: a user-friendly curl alternative.” While it is available outside of the Python ecosystem, it can be installed via Pip and is built on top of Requests.
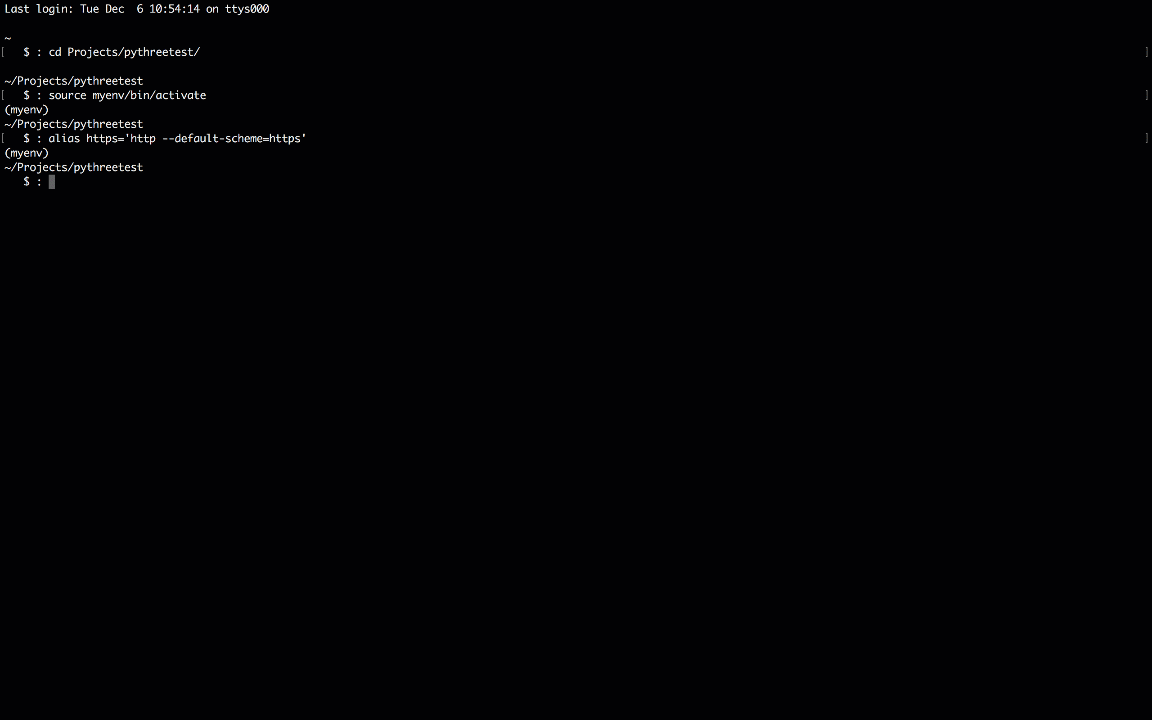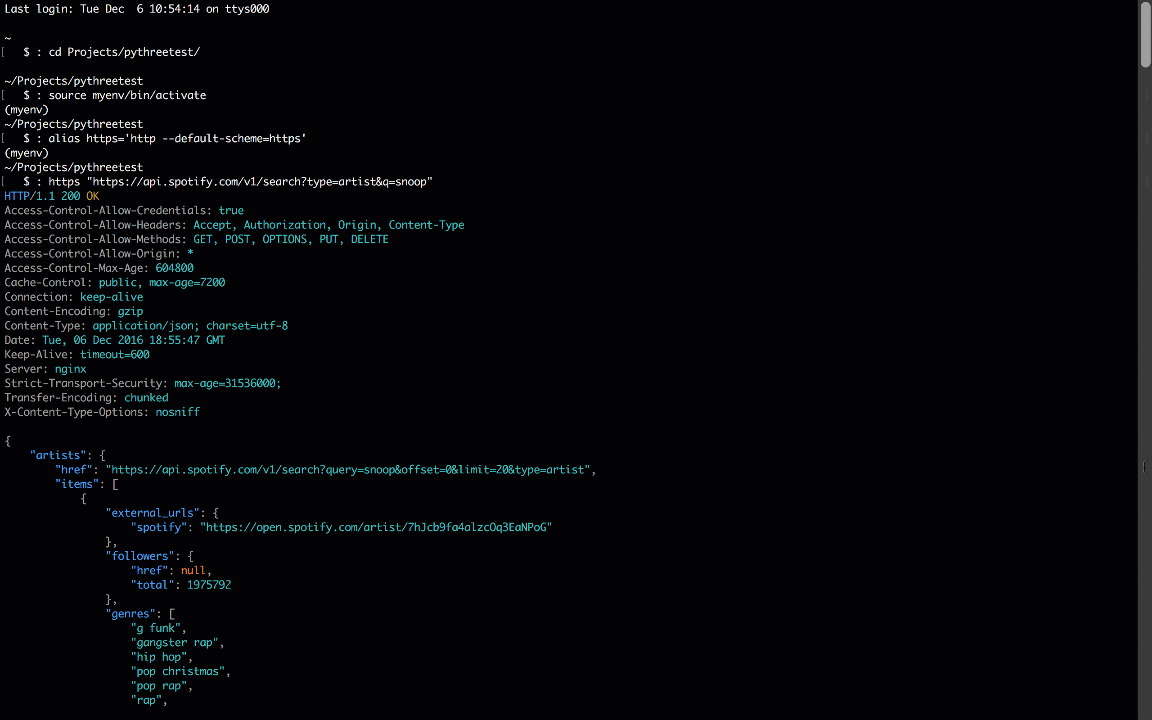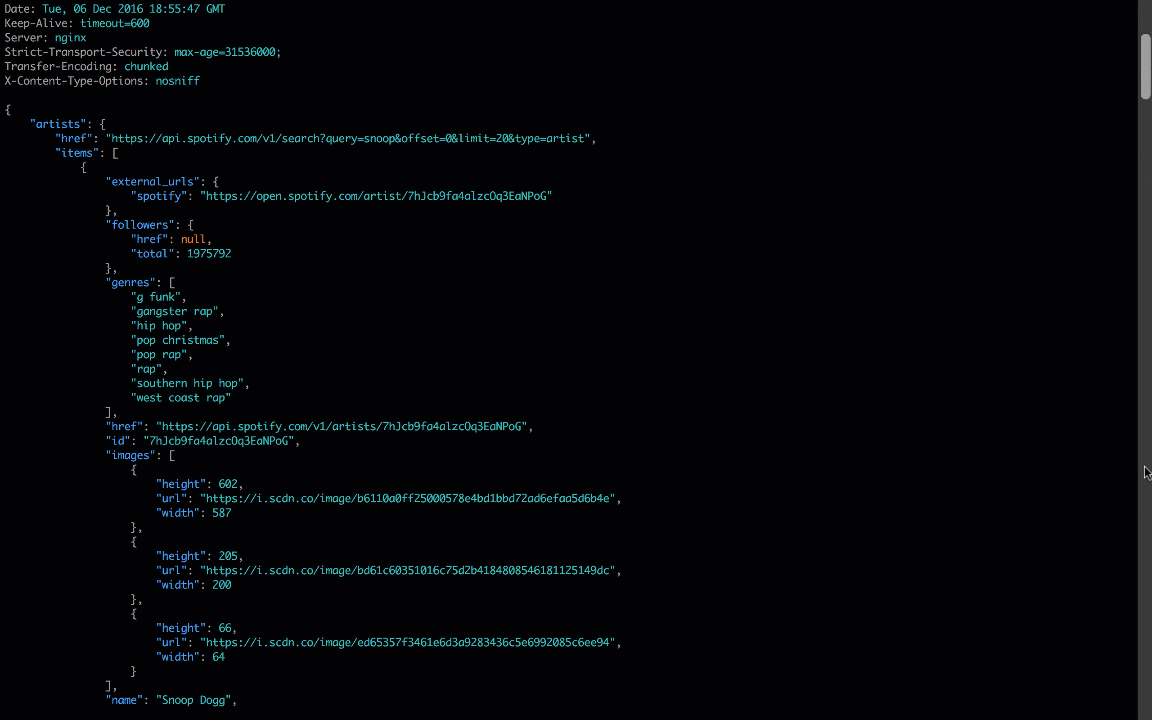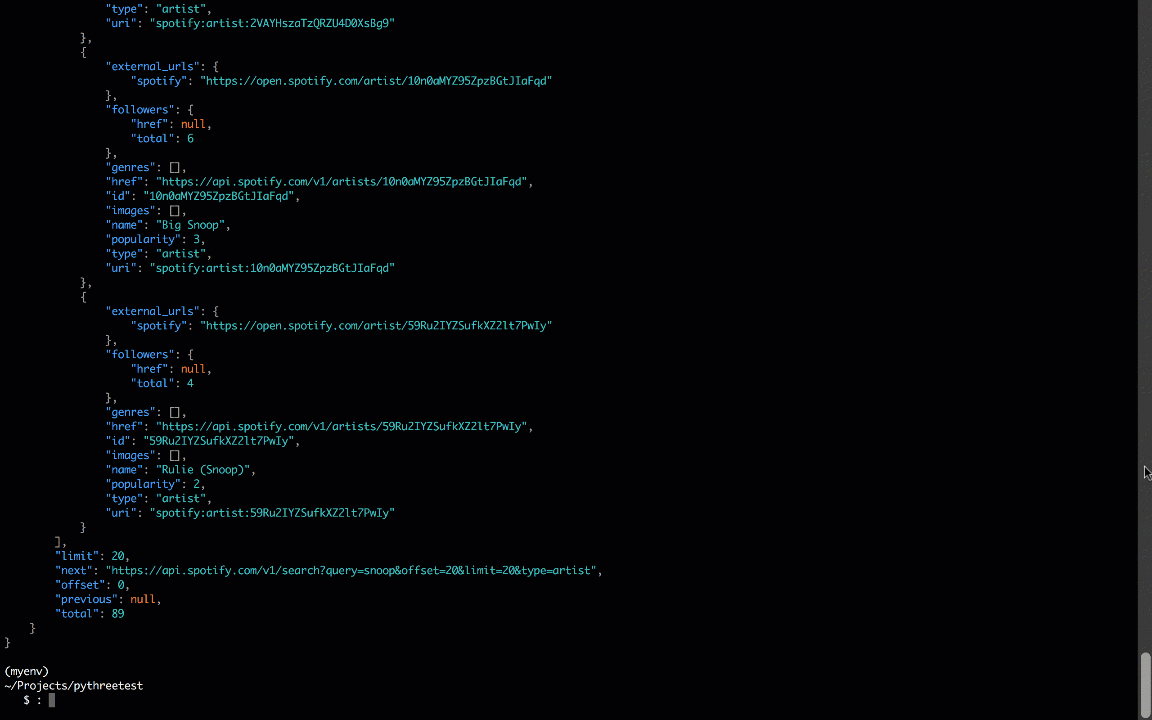
The default protocol is HTTP but you can create an alias and reset the default for HTTPS like so:
And then make a request:
The only information HTTPie needs to perform a request is a URL and boom we’re done.
Final Thoughts
The Python ecosystem offers many options for interacting with JSON APIs. While these approaches are similar for the simplest of GET requests, the differences become more apparent as your HTTP requests grow in complexity. Play around and see which one best fits your needs. You might even give it a try in another language like Ruby, Node, or Swift.
Did we miss your favorite library? Let us know in the comments or find me @meganspeir on Twitter and let me know.


Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.