3 Ways of Querying Data using LangChain Agents in Python
Time to read:
July 11, 2023
Written by
Reviewed by
I decided to analyze data from my workouts to use it in a large language model (LLM) app and quickly learned there are multiple ways to query Strava data using LangChain–read on to learn 3 ways of querying Strava data using LangChain's OpenAPI, CSV, and Pandas Dataframe Agents in Python.
LangChain Agents
LangChain, a framework for building applications around LLMs, provides developers an interface for connecting and working with models and that data.
LangChain agents use an LLM to decide what actions to take and the order to take them in, making future decisions by iteratively observing the outcome of prior actions. Agents can be chained together and they can connect the LLM to external knowledge sources or tools for computation. If there is an error, it can attempt to fix it. With Agents, the model makes more decisions.
This tutorial will compare 3 agents: the
- OpenAPI agent, which helps consume arbitrary APIs that conform to the OpenAPI/Swagger specification (in the case of this tutorial, the Strava API.) We'll need a spec file that allows you to describe the API we wish to consume, including available endpoints, authentication methods, etc.
- CSV agent, an agent built on top of the Pandas DataFrame agent capable of querying structured data and question-answering over CSVs. It loads data from CSV files and can perform basic querying operations like selecting and filtering columns, sorting data, and querying based on a single condition.
- Pandas DataFrame agent: an agent built on top of the Python agent capable of question-answering over Pandas dataframes, processing large datasets by loading data from Pandas dataframes, and performing advanced querying operations. It can group and aggregate data, filter data based on complex conditions, and join numerous dataframes.
To get started, make a new folder called Strava-LangChain and you will need the following prerequisites:
Prerequisites
- OpenAI Account – make an OpenAI account here
- Python installed - download Python here
- A Strava account - sign up for a Strava account if you don't have one already
If you're using a Unix or macOS system, open a terminal and enter the following commands:
If you're following this tutorial on Windows, enter the following commands in a command prompt window:
Setup the Strava API
In order to use the Strava API, you need to create an app. If you’re reading this, you likely already have a Strava account but if not go ahead and create one now from the Prerequisites link above. Sign in to your Strava account and navigate to your API settings page. You can alternatively find that by selecting My API Application in the dropdown menu on the left of your regular account settings.
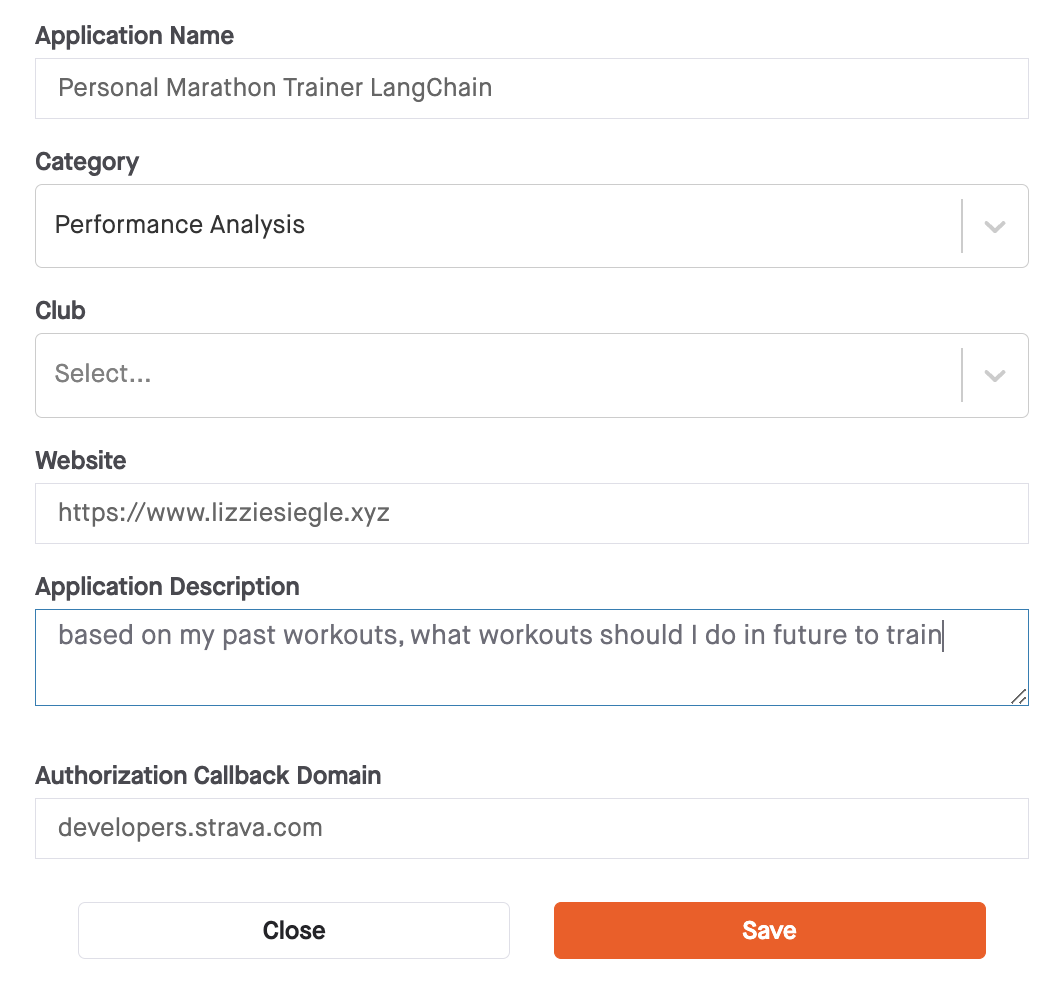
You should now see the “My API Application” page. Fill it out accordingly:
Agree to Strava's API agreement and click Create. Yay! You have your first Strava application.
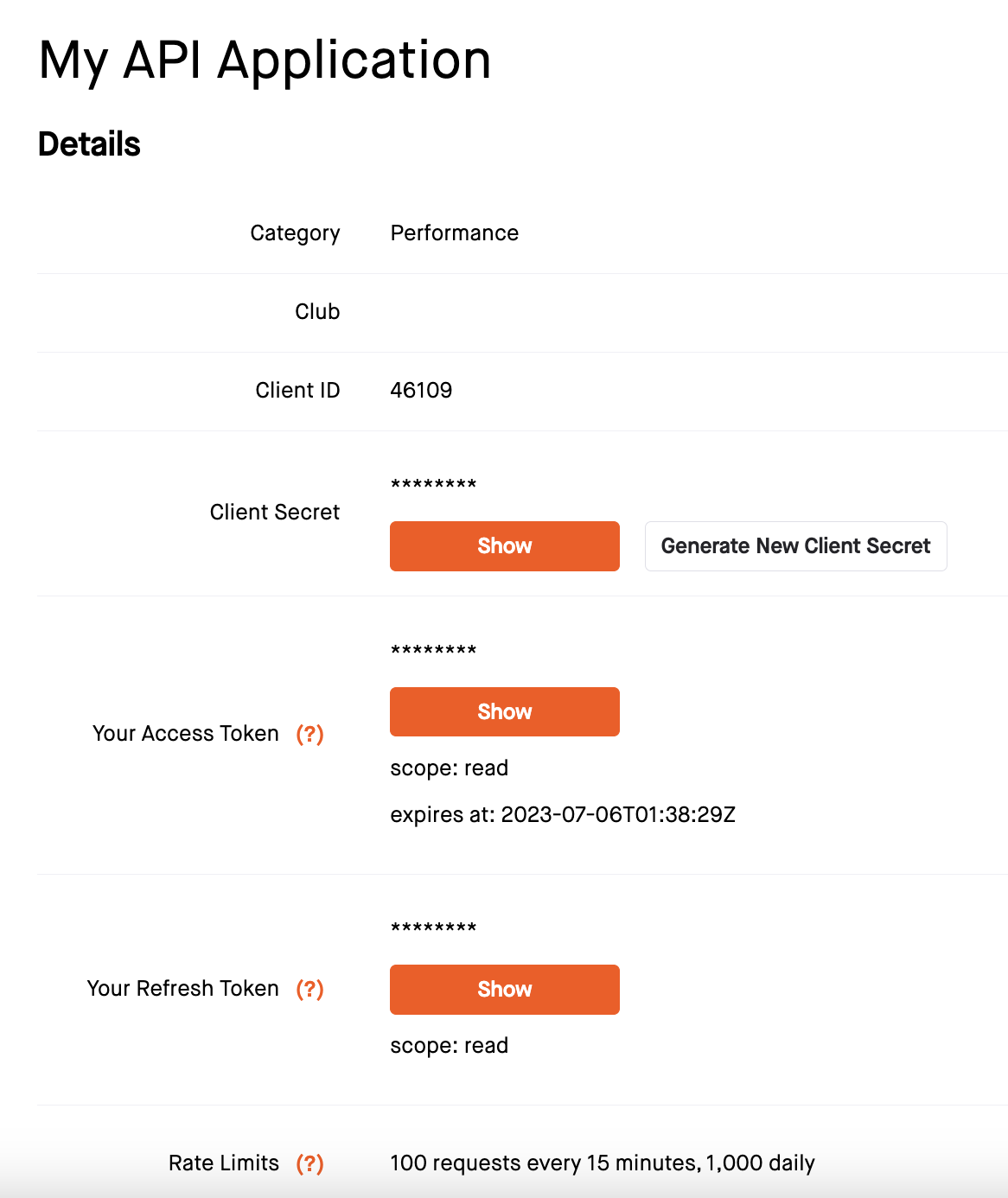
Save your Client Secret as an environment variable called STRAVA_CLIENT_SECRET.
Strava Activity Webhook Authentication
Now make a file called strava-token.py and add the following code:
Run the file with the command python strava-token.py. Then click the link and in the webpage, click Authorize.
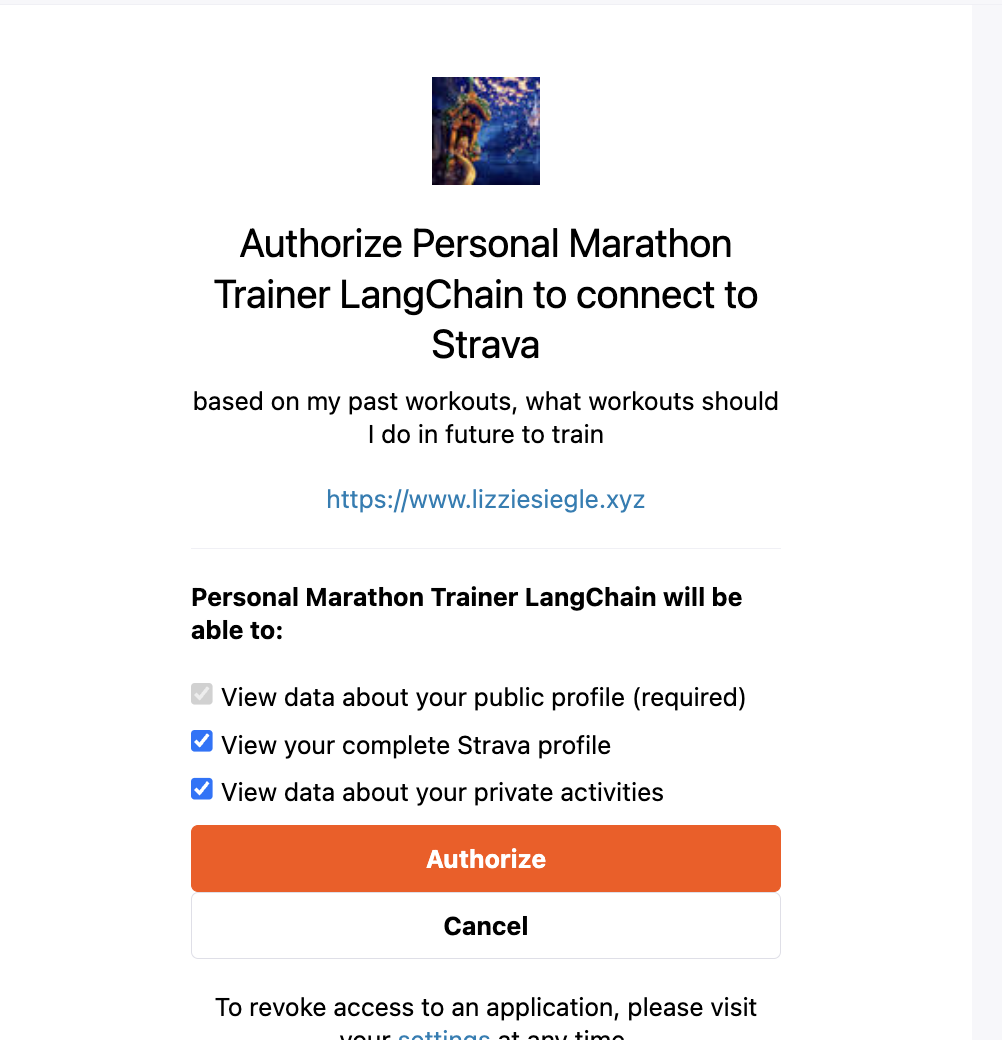
Then grab the code from the generated URL (redirection URL) you set.

Paste it in your terminal:

You should get your Access Token–save it as an environment variable STRAVA_TOKEN.

Now let's look at three different LangChain Agents we can use to collect and work with the Strava data we can get now that we have an API token.
1. Query Strava Data from the Strava API with an OpenAPI Agent
We will interface with Strava's API via the OpenAPI Swagger, a set of open-source tools built around the OpenAPI Specification that can help developers work with and consume REST APIs.
LangChain lets you call an endpoint defined by the OpenAPI specification with purely natural language. They offer two ways of interacting with APIs:
OpenAPIEndpointChaina chain that wraps a specific endpoint to provide a "Natural Language API"- OpenAPI Planner/Executor Agent - an agent good for interacting with large specs
I found that the chain was correct less often than the agent–it didn't correct itself if it couldn't perform a task and outputted "The API response does not contain any information" more often–good thing LangChain is open source so we could dig into the code to see why!
In the current directory, add this code to a file called swagger.yml. This document provides information defining and describing the Strava API and its elements, like what endpoints developers can use.
At the top of a file called openai-agent.py, include the following code to import the following libraries, read the swagger.yml file to collect some OpenAPI specs, load your .env file, set your Strava token, and set the headers:
Next get the API credentials, create our LLM, and ask it a question.

The output is correct! When asked about my last run, the OpenAPI agent knows I want information about the one that happened most recently.
Now before we can compare this with querying data from a CSV Agent or a Pandas Dataframe Agent, we have to get our data into a CSV.
Make a CSV file of data from the Strava API
On the command line, run pip install requests pandas dotenv_values. In a new file called strava_csv_lc.py, include the following lines to import libraries needed to make a request to the Strava API, use a .env file, and make a CSV of your activities:
The next code hits the Strava API's "/athlete/activities" endpoint and loops through four pages of Strava activities.
We then only look at certain columns in the dataset, use json_normalize to quickly flatten the JSON into a DataFrame object, and then write the activities to a CSV file called activities.csv.
The CSV file called activities.csv is made! Let's now ask it questions with a CSV agent.
2. Query Strava Data with a CSV Agent
Add the following code to create a CSV agent and pass it the OpenAI model, and our CSV file of activities. Then run it and ask it questions about the data contained in the CSV file:
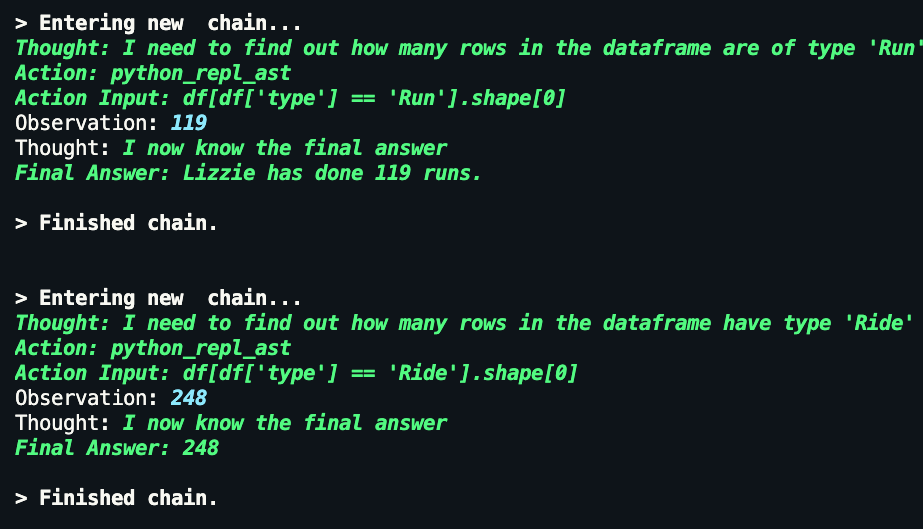
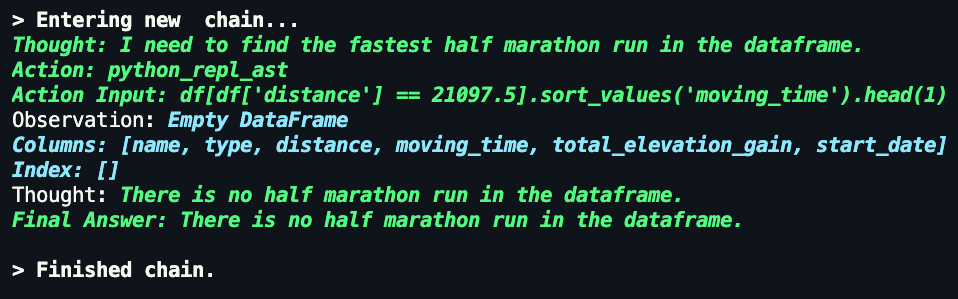
The chain does not take the steps from the string "half marathon" to "13.1 miles", but can find the fastest half marathon when given the specific distance (both 13.1 miles or 21.0975km.)
Pretty good! Let's see how the Pandas Dataframe Agent does.
3. Query Strava Data with a Pandas Dataframe Agent
Run pip install pandas and import it:
At the top of the file import the following libraries and set the required OPENAI_API_KEY variable.
Finally we can read our CSV file into a Pandas Dataframe object and initialize our agent.
Now run the agent asking it about previous Strava activities.
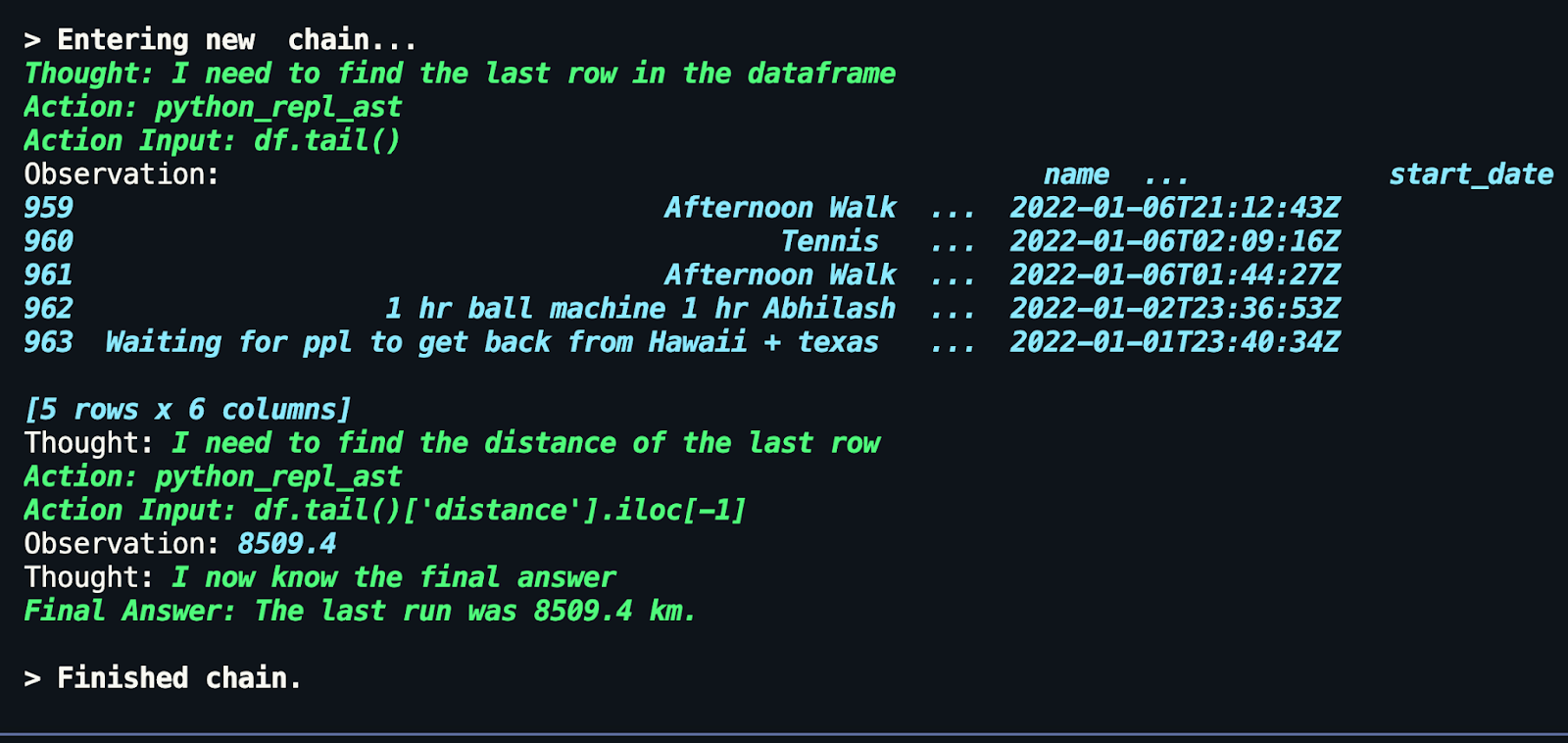

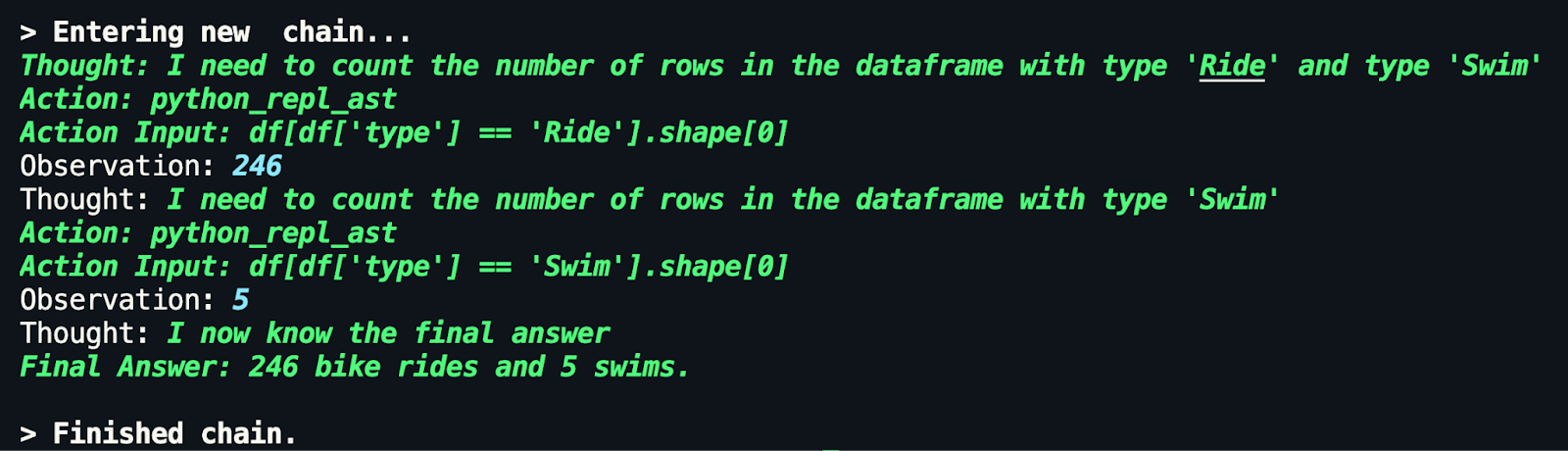
Alas, my last run was not 8509.4km (but the last run in the Dataframe, which is the least recent, is 8509.4km! When asked for my most recent run, the distance is correct!), but the other information is correct! Moral of the story: be careful what you ask and how, and see the steps, thoughts, and observations the agent takes to get to its final answer.
Comparing these different ways of querying data
These agents CSV and Pandas Dataframes agents offer a new approach to querying data, differing from more traditional query languages. Instead of writing code to handle data, these agents let users ask questions via natural language and get answers more conversationally and quickly, no need for crafting complex queries.
However, we did see that this natural language approach sometimes doesn't handle more complex queries with multiple operations or steps and can sometimes be imprecise, leading to inaccurate results.
The outputs of the CSV agent and Pandas Dataframe agents are similar, which makes sense because both agents call the Pandas DataFrame agent under the hood, which in turn calls the Python agent. The CSV agent uses the Python agent to execute code but particularly utilizes the Pandas DataFrame agent to work with CSV files.
Ultimately, I think the Dataframe Agent would be better than the CSV Agent for most operations because it makes it easier for developers to perform operations on the data–a CSV doesn't provide the scientific data manipulation tools that Pandas does.
The OpenAPI Agent hits the API which would give more up-to-date data than a static CSV file. I found its answers to queries to be more accurate than those from the OpenAPI Chain. I thought this was because of proper parsing and ignoring of other things, and looking at LangChain's open source code for its OpenAPI Chain's LLM usage, a line that stands out to me is If the question does not seem related to the API, return I don't know. Do not make up an answer. Only use information provided by the tools to construct your response. It knows the base URL to use to make the request, but sometimes does not get the correct endpoint.
When asked to get the number of runs I've done, it wants to use "GET /athletes/{id}/activities endpoint" but that does not exist so it does not answer that query.
What's Next for Querying Data with LangChain in Python?
The complete code can be found on GitHub here. LangChain's OpenAPI, Pandas Dataframe, and CSV agents are powerful developer tools that offer builders efficient querying capabilities. Being able to chain different agents together to build more complex applications opens up a wide range of possibilities for data-driven applications. Stay tuned for more tutorials on the Twilio blog about querying data with LangChain, especially with APIs like Strava!

Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.