Parsen von HTML im Internet mit Java und jsoup
Time to read:
September 16, 2019
Autor:in:

Du musst HTML in deiner Java-Anwendung parsen? Möglicherweise willst du Daten von einer Website extrahieren, für die es keine API gibt, oder du hast es Benutzern erlaubt, deiner Anwendung willkürliches HTML hinzuzufügen, und willst sicherstellen, dass sie keine bösen Überraschungen hinterlassen haben.
Hast du schon einmal versucht, reguläre Ausdrücke dafür zu verwenden? Das wird nicht gut ausgehen. Dem Verfasser dieser mittlerweile berühmt-berüchtigten Antwort gelang es gerade noch, seine Verzweiflung halbwegs im Zaum zu halten und den Einsatz eines XML-Parsers vorzuschlagen (bevor er vermutlich doch den Verstand verloren hat). Leider ist es so, dass ein Großteil des weltweiten HTML kein gültiges XML ist. Der Grund: Entwickler öffnen Tags, aber schließen sie nicht, sie betten Tags falsch ein und begehen alle erdenklichen weiteren XML-Fauxpas. Einige Nicht-XML-Konstrukte sind als HTML absolut in Ordnung, und Browser kommen überraschenderweise damit zurecht.
Um der Flexibilität und dem Stil von Web-Browsern gerecht zu werden, braucht man einen dedizierten HTML-Parser. Und in diesem Blog-Beitrag zeige ich, wie man mithilfe von jsoup das chaotische und wunderbare Internet in den Griff bekommt. Du erfährst, wie man gültiges (und ungültiges) HTML parst, schädliches HTML beseitigt und die Struktur eines Dokuments anpasst. Und am Ende zeige ich eine kleine App mit einem HTML-Beispiel aus der Praxis.
Soup? Suppe?
Die WHATWG ist eine Arbeitsgruppe, die HTML entwirft und die Meinung vertritt, dass Kompatibilität mit früheren HTML-Versionen und bestehenden Webseiten wichtiger ist, als dass alle Dokumente gültiges XML enthalten. So weit, so gut – zum einen erleichtert dies das Beisteuern von Inhalten zum Internet, zum anderen profitieren wir dadurch alle von mehr Resilienz.
Allerdings müssen Browser dadurch mit einigen Problemen fertig werden, darunter:
- Falsch eingebettete Tags wie
<strong>This <em>is</strong> mis-nested</em> - Nicht geschlossene Tags wie
<img src="cute-dogs.gif"> - Falsch platzierte Tags wie ein
<title>im<body>eines Dokuments - Unbekannte Tag-Attribute wie
<input model="myModel"> - Selbst erstellte Tags
und vieles mehr …
Dokumente dieser Art mit wild verteilten Tags und Tag-Bestandteilen haben sich den Namen Tag Soup (Tag-Suppe) eingehandelt, und genau daraus entstand der Name „jsoup“ für die Java-Bibliothek.
jsoup macht es möglich, Webseiten abzurufen und sie zu parsen, sodass aus der Tag Soup eine ordentliche Hierarchie wird. Die Daten können mit CSS-Selektoren oder durch das direkte Navigieren und Anpassen des Document Object Model extrahiert werden – also praktisch genau das, was ein Browser machen würde, nur mit Java-Code. Noch dazu kann das HTML problemlos angepasst und ausgeschrieben werden. jsoup führt das JavaScript nicht für dich aus. Falls das für deine Anwendung nötig ist, solltest du einen Blick auf JCEF werfen.
Hinzufügen von jsoup zu deinem Projekt
jsoup kommt als einzelne JAR-Datei ohne Abhängigkeiten, d. h. solange du Java 7 oder höher verwendest, kannst du es in jedem beliebigen Java-Projekt nutzen. Unter jsoup.org/download sind ein paar sehr gute Anleitungen zu finden, und ich habe den Code aus diesem Blog-Beitrag in einem GitHub-Verzeichnis gespeichert, das Gradle zum Verwalten von Abhängigkeiten nutzt. Um den Code aus meinem Verzeichnis ausführen zu können, brauchst du Java 11 oder höher.
Ein paar Löffel jsoup
Wir werden uns einige Beispiele zur Verwendung von jsoup ansehen und vergleichen, wie es Tag Soup bei Firefox interpretiert. Anschließend entwickeln wir eine echte Anwendung, die „on demand“ Daten aus dem Internet abrufen kann.
Abrufen und Parsen einer Webseite
Ich habe unter https://elegant-jones-f4e94a.netlify.com/valid_doc eine einfache Webseite eingestellt. Gemäß dem W3C-HTML-Validator handelt sich um gültiges HTML5. Wir rufen das Dokument jetzt mit jsoup ab und prüfen, wie der Titel der Seite lautet:
(vollständiger Code auf GitHub)
Wie erwartet wird der Titel der Seite als „A Valid HTML5 Document“ gedruckt.
Extrahieren von Daten mit einem CSS-Selektor
Wir verwenden dieselbe URL wie zuvor und sehen auf der Seite zwei <p>-Elemente mit den IDs interesting und uninteresting. Mithilfe des ID-Selektors rufen wir jetzt einen interessanten Fakt ab:
(vollständiger Code auf GitHub)
Wenn du den Code ausführst, wird eine interessante Info zu Eulen angezeigt.
Interpretieren von falsch formuliertem HTML
Das bisher Gelernte war hilfreich, hielt aber nicht allzu viele Überraschungen bereit. Daher sehen wir uns jetzt mal an, wie jsoup sich bei komplizierteren Zusammenhängen schlägt.
Auch hier arbeiten wir wieder mit der Seite, die ich unter https://elegant-jones-f4e94a.netlify.com/misnested_tags eingestellt habe. Der W3C-Validator meckert hier aus verschiedenen Gründen, unter anderem wegen der falsch eingebetteten Tags <strong>This <em>is</strong> mis-nested</em>.
Firefox rendert das Ganze gar nicht so schlecht: Der Text mit dem Tag <strong> wird fettgedruckt angezeigt und der Text mit dem Tag <em> in Kursivschrift.

Mit den Firefox Developer Tools können wir das von Firefox erstellte DOM prüfen:
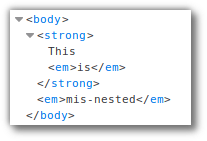
Das <em>-Tag wird geschlossen und neu geöffnet, um ein DOM mit einer gültigen Baumstruktur zu schaffen. Und bei jsoup?
(vollständiger Code auf GitHub)
Die Ausgabe sieht wie folgt aus:
JSoup hat beim Parsen also die gleiche Entscheidung getroffen wie Firefox. Nicht schlecht. Ein XML-Parser hätte das nicht so gut hinbekommen, und was mit regex (einem regulären Ausdruck) passiert wäre, möchte ich gar nicht erst wissen ...
Verhindern von XSS-Angriffen – schädliche Tags entfernen
Als Nächstes sehen wir uns ein anderes Szenario an. Stell dir vor, du hast eine Website entwickelt, auf der Benutzer über HTML Kommentare hinterlassen können. Ein Benutzer mit böswilligen Absichten könnte versuchen, JavaScript-Code in einen Kommentar zu packen, um dann einen XSS-Angriff auszuführen und die Sitzung eines Benutzers zu kompromittieren. Bei einem erfolgreichen XSS-Angriff kann der böswillige Benutzer deine Website so nutzen, als wäre er als ein beliebiger anderer Benutzer, der den Kommentar gesehen hat, angemeldet. Nicht gut.
Das HTML des Kommentierers würde in diesem Fall vermutlich als Java-String vorliegen. Sehen wir uns einmal an, wie jsoup hier helfen kann:
(vollständiger Code auf GitHub)
Dies wird gedruckt als:
und dann als
Ich habe ein Preset namens basicWithImages verwendet. Es gibt noch einige andere integrierte Presets, aber du kannst auch ein eigenes erstellen, indem du diese Klasse erweiterst oder eine bestehende Instanz anpasst.
Das Attribut onclick wurde aus dem <a>-Tag entfernt, und dadurch wird der XSS-Angriff verhindert. JSoup hat außerdem rel="nofollow" hinzugefügt. Das ist ein Hinweis für Suchmaschinen, den betreffenden Link auszuschließen, wenn die Bedeutung der Zielseite berechnet wird. So wird Kommentar-Spam verhindert, der die SEO für die Zielseite in die Höhe treibt. Und nun versuch mal, das mit einem regulären Ausdruck zu erzielen! (Bloß nicht!)
Verwenden von jsoup in der Praxis
Wir schreiben jetzt eine Java-Methode, die anhand eines Strings ein Element auf Wikipedia sucht und den ersten Satz des Artikels über das Thema zurückgibt. Dieses programmgesteuerte Extrahieren von Inhalt aus Webseiten wird häufig als Web Scraping oder Screen Scraping bezeichnet. Das Verfahren kann recht anfällig sein, und eventuell sind Anpassungen deines Codes erforderlich, wenn sich die HTML-Struktur der Website ändert.
Wir nehmen Wikipedia als Beispiel für das Web Scraping mit jsoup. Wikipedia hat zwar eine API, ist aber trotzdem ein gutes Beispiel für unsere Zwecke. Wenn du mitentwickeln möchtest, findest du den vollständigen Code auf GitHub.
Als Erstes erstellen wir eine Java-Methode, die eine Zusammenfassung erzeugt. Mit jsoup rufen wir die Seite ab und bearbeiten Fehler, die eventuell auftreten:
Danach extrahieren wir die Absätze aus dem Hauptabschnitt der Seite. Dabei handelt es sich um die <p>-Elemente im ersten <div> innerhalb des <div> mit der ID mw-content-text. Wir können hier CSS-Selektoren verwenden: > (untergeordnetes Element) und :first-of-type:
Für den Fall, dass wir den ersten Satz nicht extrahieren können, sichern wir uns mit einem erklärenden Satz ab:
Jetzt setzen wir die Java Streams-API ein, um unsere Zusammenfassung zu generieren, indem wir wie folgt vorgehen:
- Wir entfernen leere Absätze.
- Wir suchen nach dem ersten Absatz, der Text enthält.
- Wenn es einen solchen Absatz gibt, entfernen wir aus dem Text alles, was wir nicht brauchen, z. B. Fußnoten und Aussprachehinweise.
- Danach wird dieser „abgespeckte“ Text zurückgegeben bzw. wenn es keinen Text gibt, wird der erklärende Satz angezeigt, mit dem wir uns für diese Eventualität abgesichert haben.
Es kann sein, dass der Text des ersten Absatzes noch immer sehr lang ist. Wir kürzen ihn daher nach dem ersten Punkt ab und geben ihn zurück. Falls dies kein Ergebnis liefern sollte, wird wieder der absichernde Satz zurückgegeben:
Der vollständige Code mit allen Importen ist auf GitHub zu finden. Ich habe bei diesem Code auch eine main-Methode eingebettet:
Das Ergebnis lautet: „Twilio ist ein CPaaS-Unternehmen (Cloud Communications Platform as a Service) mit Sitz in San Francisco, Kalifornien.“ Perfekt!
Wie geht es weiter?
Mit deinen neu erworbenen Fähigkeiten zum Parsen von HTML könntest du beispielsweise:
- Den obigen Code konvertieren, um mit der SMS-API von Twilio auf SMS zu antworten, für Schnellinfo unterwegs
- Ein neues leichtgängigeres Front-End programmieren, z. B. für die furchtbare Intranet-Seite, die du im Büro nutzen musst (du weißt schon, welche ich meine)
- Deine eigene Website auf Bilder prüfen, die nicht das Attribut alt-text enthalten. Das Attribut
altist in HTML zwar nicht zwingend erforderlich für Bilder, aber sehr nützlich für die Barrierefreiheit.
Auch ein Blick auf traintimes.org.uk lohnt sich. Es handelt sich um eine barrierefreie, schnelle und mit Lesezeichen versehbare Website für Bahnreisen in Großbritannien. Sie bezieht ihre Informationen durch Screen Scraping von der National Rail Enquiries-Website.
Ich hoffe, dass dieser Blog-Beitrag hilfreich für dich war. Wenn du jsoup für deine Projekte nutzt, würde ich gerne mehr darüber erfahren. Du erreichst mich unter mgilliard@twilio.com oder auf Twitter unter @MaximumGilliard – ich bin gespannt auf deine Ergebnisse.


Ähnliche Ressourcen
Twilio Docs
Von APIs über SDKs bis hin zu Beispiel-Apps
API-Referenzdokumentation, SDKs, Hilfsbibliotheken, Schnellstarts und Tutorials für Ihre Sprache und Plattform.
Ressourcen-Center
Die neuesten E-Books, Branchenberichte und Webinare
Lernen Sie von Customer-Engagement-Experten, um Ihre eigene Kommunikation zu verbessern.
Ahoy
Twilios Entwickler-Community-Hub
Best Practices, Codebeispiele und Inspiration zum Aufbau von Kommunikations- und digitalen Interaktionserlebnissen.