Dependencies, Confusions, and Solutions: What Did Twilio Do to Solve Dependency Confusion
Time to read:
August 03, 2021
Written by

Early February 2021, the Product Security team at Twilio came across an article that spoke about a novel supply chain attack based on dependency package naming conventions. The attack consisted of uploading malware to open source repositories such as PyPI, NPM, and RubyGems, and naming them such that they would be downloaded and used by the target company’s application. In this post, we’ll talk about how we at Twilio went about protecting our customers' data from this attack and the various detections and controls we put in place.
Common questions about dependency confusion
Since dependency confusion is a novel attack, you probably have some questions about what it is and what’s currently happening. In this section, we’ve gathered some answers about how dependency confusion works, how we’re defending against it at Twilio, and how you can protect your own codebase.
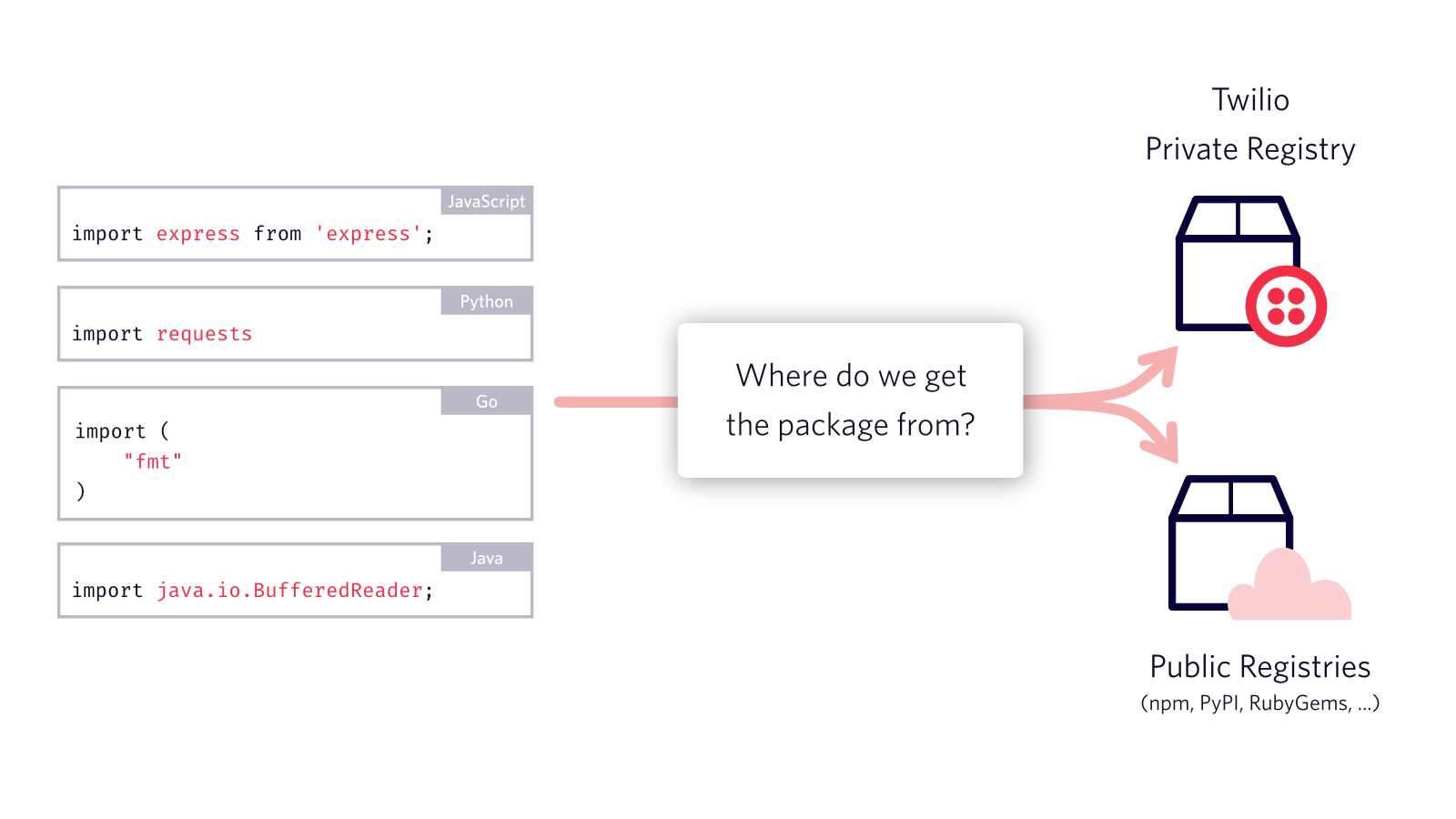
What’s a dependency?
Dependencies are code modules packaged for easy consumption in application code that you write. It’s a mechanism to enable code reusability for commonly solved problems and are imported into your applications.
Where can I learn more about this attack?
This article does a great job of explaining dependency confusion and would be a great place to learn more about the attack and how it impacts companies if not addressed.
How did we check to see if Twilio is vulnerable?
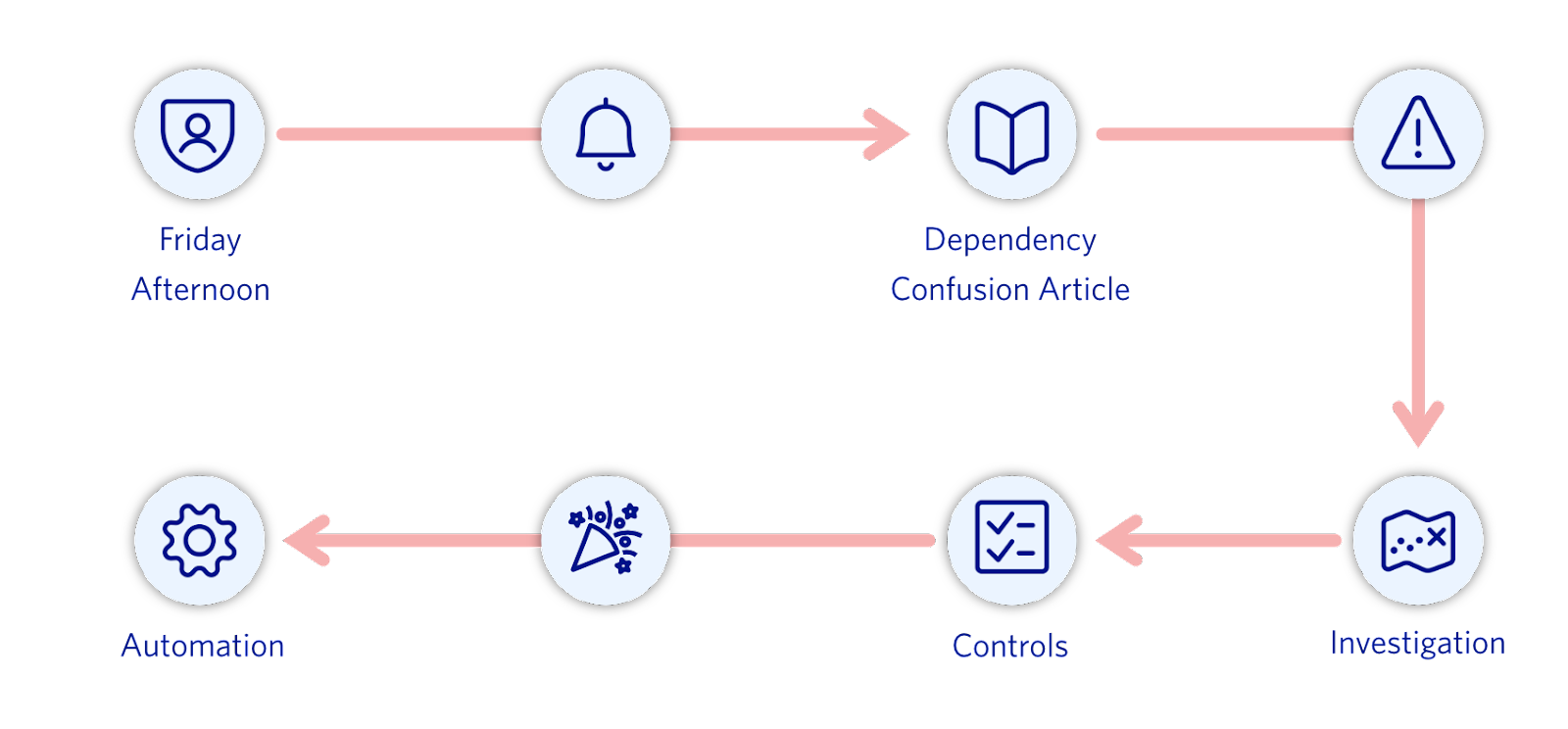
It was a Friday afternoon (exciting security things always happen on a Friday) when we came across the dependency confusion article and we realized we didn’t entirely know how packages were used in Twilio. So we started our investigation from scratch. To kick things off we got on a call with our Platform team that manages our dependency packages store and started cataloging all the languages used in Twilio and their associated package managers (pro tip: your DevOps team is your best friend).

Once we had a list of languages widely used in Twilio, we started investigating on a per language basis. We started going through package managers (npm, pip, gomod, maven, etc.) and how they interact with package registries (public vs. private registries). We then checked if it was possible to have package name collisions between private and public packages and which package managers might be susceptible to pulling the external dependencies instead of the internal one intended to be pulled. After a thorough investigation we came to the conclusion that GO and Java languages were not vulnerable since they used fully-qualified names and group id reference conventions respectively. But, with how we had packages set up in other languages at Twilio we were at risk of being vulnerable to this attack vector.
What did Twilio do to safeguard its customers' data against dependency confusion attacks?
After we identified all the languages that were susceptible to this attack, we started implementing controls to protect Twilio services and add monitors for attack vectors related to dependency confusion. So what changes did we make and why?

Introduced & enforced naming conventions for all internal packages published and consumed in Twilio
Wherever possible, we registered namespace/scope/vendor in public registries to Twilio. This makes it that only Twilio could publish here to reduce/eliminate the chances of unintentional downloads. If registering a namespace wasn't possible, we mandated the use of specific package naming formats internally.
Blocked proxying of external packages that collide in the specified naming convention
At our package management system level, we blocked proxying of public packages that have a name collision with what was published internally. Say, we have an internally published package called “twilio_package” and this package is also available on the public registries then we setup our package management system to never proxy “twilio_package” from the public registries and always serve the one published internally. Even if a public package name collides with an internal package name, we'll default to the internally produced and published package.
Mandated all package installs come through internal package manager proxies
Before this supply chain attack we allowed some language projects to pull in build time dependencies directly from the public registries. But now we’ve changed this such that all projects need to mention the internal registry URL if they want to pull packages from at build time. If projects do not mention a valid internal URL, then the build for the project fails ensuring that projects always use our internal proxies where we control the precedence of how dependency packages should be accessed in projects.
Block registry access on deployed hosts
We blocked any and all registry access from deployed hosts and mandated all packages to be pulled in at build time only. The only thing pulled onto hosts would be the internally built end artifact that has all the code and dependencies needed for it to function after a deployment pipeline is finished running.
Delete all old packages that did not follow the introduced naming conventions
Once we did all the above steps and confirmed all projects have moved away from the old internal packages names to the newly implemented naming convention references, we deleted all these packages from our package manager. This was to ensure we cover all the not-so-commonly used projects as well which would now be required to use the new naming convention references else their projects would break. This removes the possibility of having old projects reference packages unintentionally.
What about laptop access to packages?
Since all code repositories now need to mention the internal registry URL for their builds to pass, it inherently safeguards laptops as well. Since we set package registry precidenses in our package manager such that the internal registry is always preferred over the public registry proxy, the likelihood of someone from their laptop accessing the wrong packages is close to non-existent.
We are also working on alerting on naming collisions for public packages following Twilio’s internal nomenclature, which we talk about a little further down. This alerting acts as a defence in depth measure for Twilion’s laptops trying to access internal packages from public package managers.
This was a wild ride, what challenges did we face?
This supply-chain attack definitely presented an interesting set of challenges. Below are a few of the challenges we faced when trying to investigate and address dependency confusion attack vectors at Twilio.
Programming languages: the number of choices are a boon and a bane
When we started our investigation we really did not have an idea about the scope. Here at Twilio we give engineers the freedom to build services in a broad range of languages they see fit for their project. This meant we had a lot of languages to investigate for impact. The first problem we needed to answer was, how do we identify all the languages that are used?
Language specific package managers
Every language has a set of package managers that make dependency installation and management easier. These are things like npm, Yarn for Node.js, PIP for Python, Maven for Java. While we always hear about and see these package managers in action almost everyday of our professional lives, when we were investigating this attack we had no idea of the internal workings of these package managers, i.e., how do they create a dependency tree? How do they interact with the public registries when we explicitly mention it to pull packages from an internal registry and don't find the package there?
The marvels of the build system
While we did have a central build system, we did enable our engineers to craft their builds how they see fit without any restrictions. This caused blockers for us in our investigation since we weren’t entirely sure how some language builds were happening and required us to spend additional time to identify how builds are set up in Twilio.
Legacy code just works
Like every company out there that’s a few years old, Twilio also had legacy code with no owners. It’s like one of those things that just works, but no one really knew how they worked. It was difficult to identify people who knew the inner workings of such codebases and address this issue in them. But, ultimately we were able to identify such people and address this vulnerability in such codebases.
Acquisitions and their environments
Twilio has a fast paced acquisition process which brings not only new people, but also a plethora of new codebases, CI/CD strategies, and workflows. This adds to the list of things we need to monitor and verify to cross off the viability of the attack in these acquisitions. There are acquisitions that had their own Security teams that worked on addressing this attack in their respective workflows, but we also had a few acquisitions that did their own CI/CD, but didn’t have a dedicated Security team and we were tasked to handle these systems as well.
What’s next? And the ever increasing blast radius
Dependency-confusion brought to light our ever increasing, unmonitored need for third party packages and how their naming/scoping can cause unintended vulnerabilities and add more work rather than their intended purpose to reduce work during code development. It is impossible to monitor for attack vectors manually. So, we automate.
Automating for alerting
In places where we cannot stop people from publishing package names that might collide with what we have internally — like Python which doesn’t have the concept of scopes, or vendors as seen in npm and PHP respectively — we built out an automation to monitor what packages are being used internally versus what’s there on the public registries. This service looks for collisions in names of packages of what’s published internally in our package manager and what is available on the public registries and sends a report to a Slack channel that the Security team continuously monitors with any and all collisions identified. We use this report to decide if any additional steps like blocking proxying, renaming a package, etc. are needed or not.
Conclusion
There will always be security issues in systems and we’re only as secure as the users of the systems want to be. The only way to completely eliminate the possibility of dependency confusion is to stop using dependencies in projects which is counter-productive and adds more risk via errors made by developers trying to create a bespoke version of a dependency in areas they’re not well-versed in. So blocking all dependencies is never the answer. It’s more about having a clean inventory of all the dependencies, programming languages, and CI/CD systems used in your organisation and ensuring you have a baseline security configuration across all of them and then have active monitoring tools around them to alert you when something goes wrong.
Another thing to highlight is that this investigation and mitigation effort could not have been possible without the collaboration of Twilio Engineering, especially the Platform teams that own CI/CD systems by working with the Security team to not only investigate the issue, but also implement new security controls and enforce them throughout our deployment workflow.
Friday evening, many weeks later……..


Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.