Parse HTML for Book quotes with Python, Beautiful Soup, and WhatsApp
Time to read:
August 25, 2018
Written by
This post is part of Twilio’s archive and may contain outdated information. We’re always building something new, so be sure to check out our latest posts for the most up-to-date insights.

My first real paid job was working at the local library in high school. This was perfect because I love reading. With a monthly book stipend company perk and more time to read in my post-grad life, I've started using Goodreads to find new books and to keep track of what I've already read.
This post will go over how to parse the Goodreads quotes page. We'll target popular book quotes and quotes with a specific tag received as input from a WhatsApp message and then send a random quote as an outbound WhatsApp message.
Setting Up Twilio API Sandbox for WhatsApp
At the moment, only approved business accounts can use Twilio's WhatsApp API so we need to use the Twilio API Sandbox for WhatsApp to play around. Let's go on over to the Sandbox in our Twilio console. To activate it we must choose a Sandbox number, agree to the terms of WhatsApp, and select Activate Sandbox.
To join a Sandbox, send “join <your sandbox keyword found in your console>” to your Sandbox number in WhatsApp and you should get a response confirming you’ve joined. You can follow these instructions to install the WhatsApp Sandbox Channel in your account and connect your WhatsApp account with the Sandbox.
Setting up your Developer Environment
You will be using the Beautiful Soup Python package to scrape a webpage and extract data from its HTML. Before we can dig into some code, make sure that your Python and Flask development environment is setup. If you haven't done so already,
- Install Python 3--this is important! It must be Python 3.
- Install Ngrok to make your Flask app visible from the internet so Twilio can send requests to it
- Set up your development environment
If you're new to Python and Flask check out this handy guide for more information on getting started.
Now run the following command in the terminal in the directory you'll put your code in.
You should see a screen similar to the one below:
That publicly-accessible ngrok URL to our Flask app needs to be used when a message is sent to our WhatsApp number which we will configure below.
We need the following modules:
- Requests to access HTML pages to scrape
- Twilio to generate TwiML to respond with a quote to incoming HTTP requests with each message sent to your WhatsApp number
- Flask to respond to incoming web requests
- String to help clean texts we parsed the HTML page for
- bs4 (Beautiful Soup) to read HTML pages
- Random to pick a random number to generate random quotes.
In the terminal, run the following command to install those modules:
If this throws permission errors run
Reading and Parsing the Web Page
To start off we have to scrape and clean the Goodreads page that is selected based on the inbound message. The message can either be "popular", which is the default for https://goodreads.com/quotes, or it can be anything else, such as a title, series, or author like "Harry Potter" or "Jane Austen".
Create a file called goodreads.py where you'll put all your code. The top of goodreads.py should include the following import statements.
Now we will open the webpage and create a BeautifulSoup object representing the document as a nested data structure. An optional second parameter would be "html.parser" which is the default parser used when using BeautifulSoup. Other parsers you could use include lxml or html5lib which both require an external dependency.
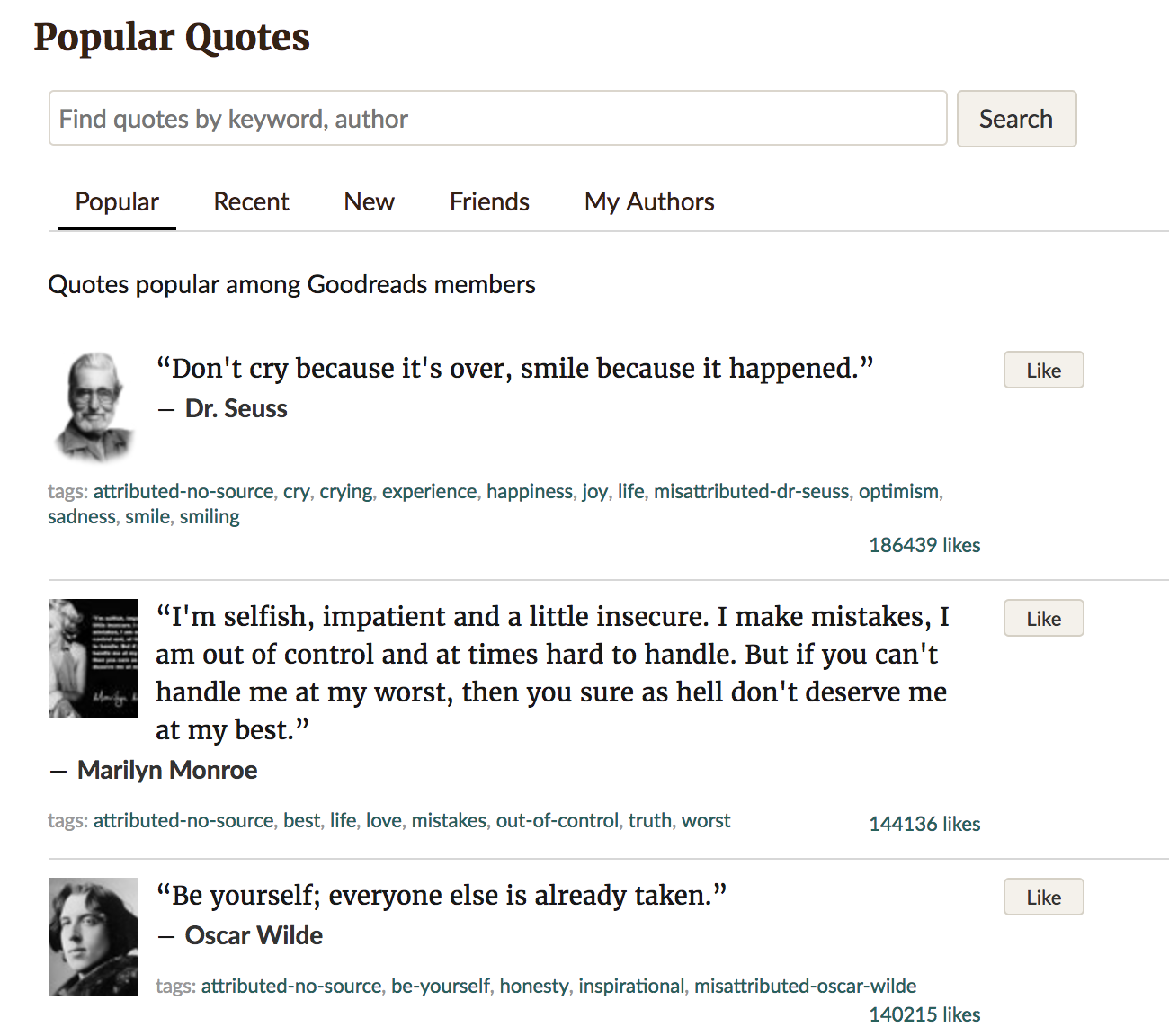
Next, we want to get quotes from the page. If you visit https://goodreads.com/quotes and right click -> view page source you would see HTML classes are nested like so:
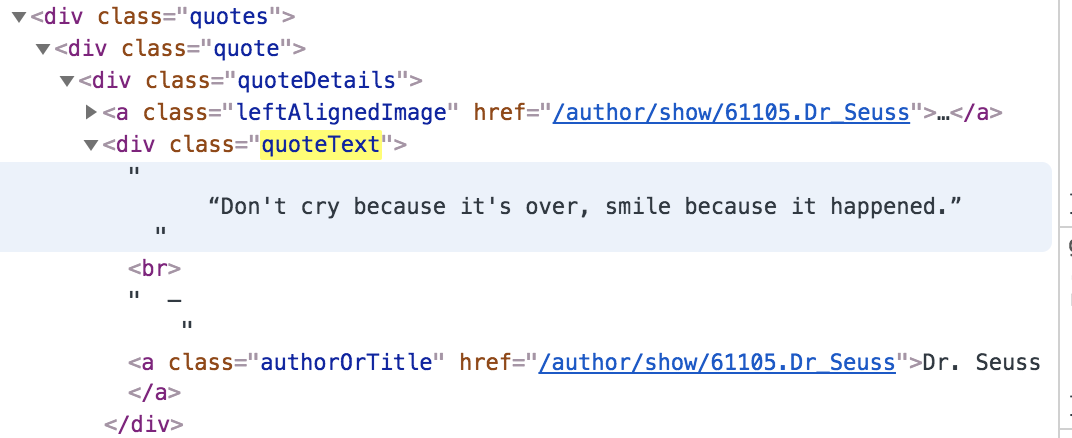
With this nested structure in mind we will find every div with the class "quoteText." We can do this with the shorthand for Beautiful Soup's find_all method: soup("div"), which is the same as writing soup.find_all("div").
Let's loop through the quotes and find each quote author. As shown in the HTML code, the only a tag in our div_quotes is the author.

If an
a tag exists then we know an author exists. We can access all that text inside a tag as a single Unicode string with the get_text() method. If we can't find an author, we skip it because it may not be a good quote.
Now we need to turn multi-line quotes into a single string. Python 3 uses Unicode by default, so every string is a sequence of Unicode characters. We will loop through a given tag's children by calling .contents on a Beautifulsoup object, and then tell it to encode each child as ASCII while ignoring any foreign Unicode characters. Once those characters have been filtered out they can be converted (or decoded) back into a readable string. A string would not have .contents because it can't contain anything. If a line starts with a tag symbol then characters that are not part of the quote are ignored. Otherwise, that line is added to the quote string to turn multi-line quotes into a single string.
To clean and format each quote, we will call strip() to remove leading and trailing characters which could mess up what is included in the list of quotes we pull from Goodreads. We also format the quote along with the author, and add on a "#" character to know where to parse the list. Finally, we filter through all the quotes to find and return the printable quotes which may include digits, letters, punctuation, or whitespace.
Sending the Goodreads Quotes with Twilio's WhatsApp API
Now that we have the quotes we want from Goodreads, let's send them with Twilio's WhatsApp API.
With the following code we make our Flask app and point it at the /whatsapp route where we will take the incoming message we receive.
With the inbound message we now figure out which URL to search through for Goodreads quotes. If the message is "popular", we would search the main /quotes page on Goodreads. Otherwise, we'd search the quotes page for the tag that was sent in.
We then make a list of quotes from passing that URL to our scrape_and_clean function, splitting at each # character. A different message is sent based on the length of that list of quotes. If there's only one quote for that Goodreads tag, we send that quote. If there are no quotes, we say to send in a different message. Otherwise, we randomly select one of the quotes.
Finally we can run our Flask app by adding this code at the bottom.
You may have noticed that this code is the same as what you would write to respond to an incoming text message to a Twilio number--the only difference is where the message is coming from.
If you run
on the command line in the directory your file is saved and text your Twilio WhatsApp Sandbox number a book title or author (can include spaces), you should get a random quote back.
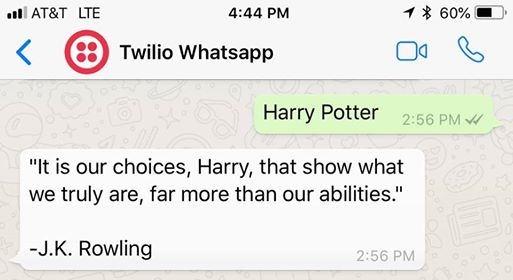
Nice!
We've now parsed an HTML page for book quotes on goodreads.com and returned a randomized quote with Python 3, Beautiful Soup, and Twilio's WhatsApp API. Check out the GitHub repo for completed code and also the official Twilio WhatsApp documentation to keep up-to-date on any new features. If you have any questions, comments, or if you built something neat, feel free to message me online!
Twitter: @lizziepika
GitHub: elizabethsiegle
Email: lsiegle@twilio.com

Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.