Web Scraping et Analyse du HTML en Python avec Beautiful Soup
Time to read:
October 22, 2019
Rédigé par

Internet offre une incroyable diversité d’informations destinées à la consommation humaine. Mais il est souvent difficile d'accéder à ces données par voie programmatique, si elles ne se présentent pas sous la forme d'une API REST dédiée. Grâce à des outils Python comme Beautiful Soup, vous pouvez récupérer, analyser des pages Web puis utiliser ces données dans vos projets.
Par exemple : Comment récupérer des données MIDI sur Internet pour entraîner un réseau neuronal avec Magenta qui sera capable de générer de la musique rétro Nintendo ?
Nous avons besoin pour cela d'un ensemble de musiques MIDI provenant d'anciens jeux Nintendo. Beautiful Soup nous permet d’obtenir ces données à partir des Video Game Music Archive.
Démarrage et installation des dépendances
Avant de continuer, assurez-vous d’avoir bien installé la mise à jour de Python 3 et de pip. Créez et activez un environnement virtuel avant d'installer toutes les dépendances.
Maintenant, vous pouvez installer la bibliothèque Requests. C’est ce qui servira à effectuer des requêtes HTTP afin d'obtenir les données de la page web et de Beautiful Soup pour analyser le HTML.
Une fois votre environnement virtuel activé, exécutez la commande suivante dans votre terminal :
Bon à savoir : Beautiful Soup 4 est la version la plus récente, la 3 n'étant plus développée ni prise en charge.
Utilisation de Requests pour récupérer des données à analyser avec Beautiful Soup
Il nous faut récupérer le HTML de la page Web. Ecrivez le code ci-dessous pour envoyer une requête GET à la page web que nous voulons, ce qui créera un objet BeautifulSoup avec le HTML de cette page :
Avec cet objet soup, vous pourrez naviguer et rechercher les données directement dans le HTML.
Par exemple :
- En exécutant
soup.titleaprès le code précédent dans un shell Python, vous obtiendrez le titre de la page Web - En entrant
print(soup.get_text()), vous pourrez voir le texte entier de ladite page.
Se familiariser avec Beautiful Soup
Pro-tip : les méthodes find() et find_all() sont parmi les armes les plus puissantes de votre arsenal :
soup.find()sera idéale pour les cas où vous ne cherchez qu'un seul élément - comme la balise body.
Sur notre page Web, soup.find(id='banner_ad').text vous donnera le texte de l'élément HTML de la bannière publicitaire.
soup.find_all()sera la méthode que vous utiliserez le plus dans vos aventures de web scraping. En l’utilisant, vous pouvez parcourir tous les liens hypertextes de la page et imprimer leurs URLs :
Il est possible de fournir différents arguments à find_all, tels que des expressions régulières (regex) ou des attributs de balises pour filtrer précisément ce que vous souhaitez.
Pour plus de fonctionnalités intéressantes, lisez la documentation !
Analyse syntaxique et navigation HTML avec BeautifulSoup
Avant d'écrire plus de code pour analyser le contenu, observons d'abord le HTML rendu par le navigateur.
Chaque page web est différente. L'obtention des bonnes données nécessite un peu de créativité, de reconnaissance des patterns, et d'expérimentations !
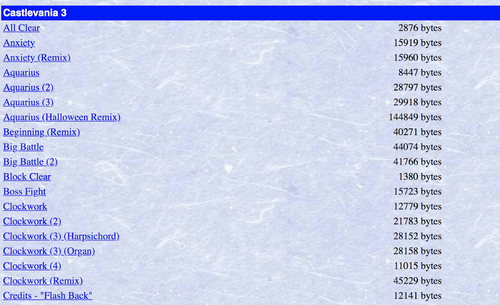
Notre but est de télécharger un paquet de fichiers MIDI. Mais beaucoup sont présents en double sur cette page web ainsi que des remixes de chansons. Sauf que nous ne désirons qu'un seul exemplaire de chaque chanson, et comme nous voulons utiliser ces données pour entraîner un réseau neuronal à générer une musique Nintendo juste et précise, il ne faudrait pas l'entraîner sur des versions différentes créées par des utilisateurs.
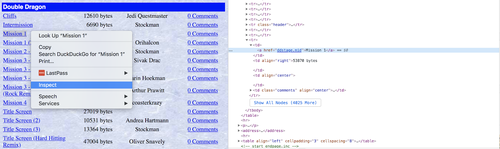
Lorsque vous élaborez du code pour analyser une page Web,vous pouvez vous servir des outils de développement disponibles dans la plupart des navigateurs modernes.
Faites clic droit sur l'élément qui vous intéresse et vous pourrez inspecter le code HTML qui se cache derrière et déterminer comment accéder aux données que vous souhaitez grâce au code.
Servons-nous de la méthode find_all pour parcourir tous les liens de la page. Cette fois, nous allons utiliser des expressions régulières pour les filtrer.
Ainsi nous n’obtenons que les liens contenant des fichiers MIDI sans parenthèses dans le texte - ce qui exclut tous les doublons et remixes.
Créez un fichier appelé nes_midi_scraper.py et ajoutez-y le code suivant :
Les fichiers MIDI seront filtrés, et cela imprimera la balise de lien correspondante, puis le nombre de fichiers filtrés.
Exécutez ensuite ce code dans votre terminal avec la commande :
Téléchargement des fichiers MIDI souhaités à partir de la page web
Maintenant que nous avons un code fonctionnel permettant d'itérer à travers tous les fichiers MIDI, nous devons en écrire un autre pour tous les télécharger.
Dans nes_midi_scraper.py, ajoutez une fonction intitulée download_track, et appelez-la dans la boucle qui parcourra toutes les pistes :
Dans cette fonction download_track, nous passons l'objet Beautiful Soup représentant l'élément HTML du lien vers le fichier MIDI, avec un numéro unique dans le nom du fichier pour éviter les éventuelles collisions de noms.
Exécutez ce code à partir du répertoire où vous voulez sauvegarder tous les fichiers MIDI. Regardez votre écran de terminal afficher les MIDI que vous avez téléchargés (2230 pour nous au moment de l'écriture de ce tutoriel).
Et ce n'est qu'un exemple concret de la multitude de possibilités qu’offre Beautiful Soup !

La vaste étendue du World Wide Web
Maintenant que vous pouvez extraire des éléments des pages Web via la programmation, vous avez accès à une énorme source de données pour tous les besoins de vos projets.
A ne pas oublier : si les propriétaires d’une page Web y apportent des modifications, le HTML peut changer. Ce qui veut dire qu’il faudra changer votre manière de le parcourir en mettant à jour votre propre code.
Et maintenant, que faire avec les données que vous venez de récupérer dans les Video Game Music Archive ? Voici quelques suggestions !
- Essayez d'utiliser des bibliothèques Python comme Mido pour travailler avec des données MIDI et les nettoyer.
- Entraînez un réseau neuronal avec ces données via Magenta
- Mais aussi vous amuser à créer un numéro de téléphone que les gens peuvent appeler pour écouter de la musique Nintendo.
J'ai hâte de voir ce que vous allez construire !
- Email: sagnew@twilio.com
- Twitter: @Sagnewshreds
- Github: Sagnew
- Twitch: Sagnewshreds
Articles associés
-
 Les 11 meilleures plateformes de marketing par e-mail en 2026Nathalia Velez Ryan Jesse Sumrak
Les 11 meilleures plateformes de marketing par e-mail en 2026Nathalia Velez Ryan Jesse Sumrak -
 Plus de 19 conseils et bonnes pratiques pour optimiser la délivrabilité de vos e-mails en 2026Jesse Sumrak
Plus de 19 conseils et bonnes pratiques pour optimiser la délivrabilité de vos e-mails en 2026Jesse Sumrak -
Comment envoyer des e-mails avec Twilio SendGrid depuis des serveurs hébergés dans l’Union européenneYukti Ahuja Brandon Walker
Ressources connexes
Twilio Docs
Des API aux SDK en passant par les exemples d'applications
Documentation de référence sur l'API, SDK, bibliothèques d'assistance, démarrages rapides et didacticiels pour votre langage et votre plateforme.
Centre de ressources
Les derniers ebooks, rapports de l'industrie et webinaires
Apprenez des experts en engagement client pour améliorer votre propre communication.
Ahoy
Le hub de la communauté des développeurs de Twilio
Meilleures pratiques, exemples de code et inspiration pour créer des expériences de communication et d'engagement numérique.