ASTs - What are they and how to use them
Time to read:
June 11, 2020
Written by
Reviewed by
If you are writing code, chances are that ASTs are involved in your development flow. AST stands for Abstract Syntax Tree and they power a lot of parts of your development flow. Some people might have heard about them in the context of compilers but they are being used in a variety of tools. Even if you don't write general development tools, ASTs can be a useful thing to have in your toolbelt. In this post we'll talk about what ASTs are, where they are used and how you can leverage them.
What is AST?
Abstract Syntax Trees or ASTs are tree representations of code. They are a fundamental part of the way a compiler works. When a compiler transforms some code there are fundamentally the following steps:
- Lexical Analysis
- Syntax Analysis
- Code Generation
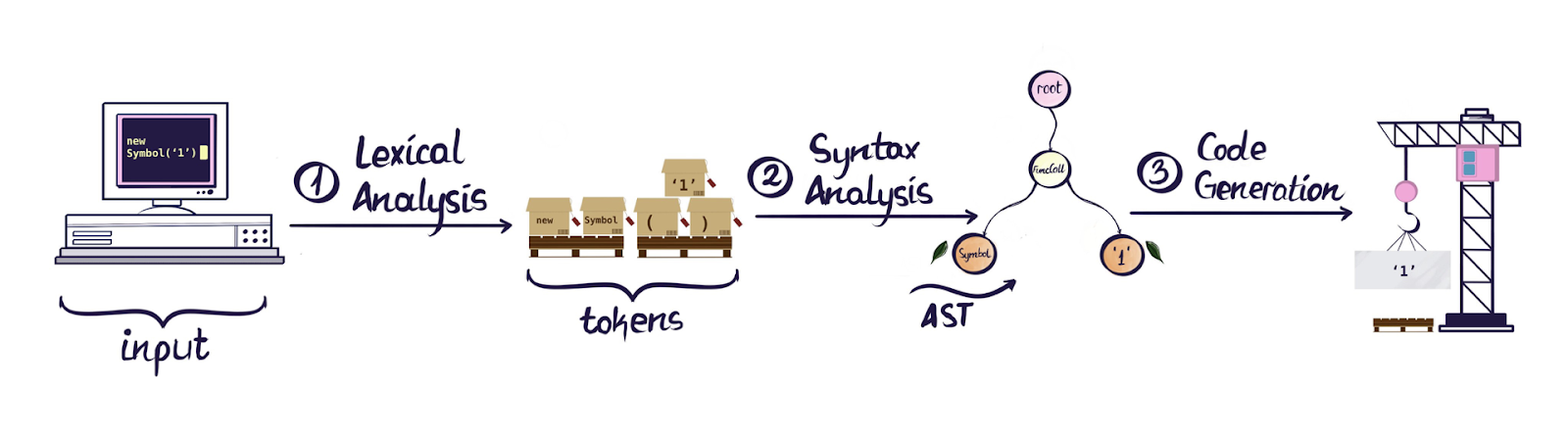
Lexical Analysis aka Tokenization
During this step, code that you wrote is going to be converted into a set of tokens describing the different parts of your code. This is fundamentally the same method that basic syntax highlighting is using. Tokens don't understand how things fit together and purely focuses on components of a file. You can imagine it as a list or array of different types of tokens.

You can imagine this as if you'd take a text and you break it into words. You might be able to make a differentiation between punctuation, verbs, nouns, numbers, etc. but at this stage you don't have any deeper understanding of what's part of a sentence or how sentences fit together.
Syntax Analysis aka Parsing
This is the step where we turn our list of tokens into an Abstract Syntax Tree. It converts our tokens into a tree that represents the actual structure of the code. Where previously in the tokens we only had a pair of () we now have an idea of whether it's a function call, a function definition, a grouping or something else.

The equivalent here would be turning our list of words into a data structure representing things such as sentences, what role a certain noun plays in a sentence or whether we are in a listing.
Another example that this can be compared to is the DOM. Where the previous step would just break down the HTML into "tags" and "text", this step would generate the hierarchy represented as the DOM.
One thing to note is that there is no "one" AST format. They might differ both depending on the language you are turning into an AST as well as the tool you are using for the parsing. In JavaScript a common standard is ESTree but you'll see that different tools might add additional properties.
In general an AST is a tree structure where every node has at least a type specifying what it is representing. For example a type could be a Literal that represents an actual value or a CallExpression that represents a function call. The Literal node might only contain a value while the CallExpression node contains a lot of additional information that might be relevant like "what is being called" (callee) or what are the arguments that are being passed in.
Code Generation
This step can be multiple steps by itself. Once we have an Abstract Syntax Tree we can both manipulate it as well as "print" it into a different type of code. Using ASTs to manipulate code is safer than doing those operations directly on the code as text or on a list of tokens.
Manipulating text is always dangerous; it shows the least amount of context. If you ever tried to manipulate text using string replacements or regular expressions you probably noticed how easy it is to get it wrong.
Even manipulating tokens isn't easy. While we might know what a variable is, if we would want to rename it we would have no insight into things like the scope of the variable or any variables it might clash with.
The AST provides enough information about the structure of code that we can modify it with more confidence. We could for example determine where a variable is declared and know exactly which part of the program this affects due to the tree structure.

Once we have manipulated the tree we can then print the tree to output whatever code output is expected. For example if we would build a compiler like the TypeScript compiler we'd output JavaScript while another compiler might output machine code.
Again this is more easily achieved with an AST because different outputs might have different formats for the same structure. It would be more difficult to generate the output with a more linear input like text or a list of tokens.
What to do with ASTs?
With the theory covered what are actually some real life use cases for ASTs? We talked about compilers but we are not all building compilers all day.
The use cases for ASTs are wide and can generally be split into three overarching actions: reading, modifying and printing. They are sort of additive, meaning if you are printing ASTs, chances are high that you previously also read an AST and modified it. But we'll cover examples for each of these that primarily focuses on one use case.
In each of these sections we'll also cover ways how you can perform the respective action. Since I'm a JavaScript developer all of the examples will be in JavaScript but basically every programming language has similar tools and libraries.

Reading/Traversing ASTs
Technically the first step of working with ASTs is parsing text to create an AST but in most cases the libraries that offer the parsing step also offer a way to traverse the AST.
Traversing an AST means visiting the different nodes of the tree to gain insights or perform actions.
One of the most common use cases for this is linting. ESLint for example uses espree to generate an AST and if you want to write any custom rules you'll write those based on the different AST nodes. The ESLint docs have extensive documentation on how you can build custom rules, plugins and formatters.
If you want to see an abbreviated example here is a code example in the AST explorer that establishes a rule that you can only have one class in your file.
In this code snippet we are looking for ClassDeclaration nodes and every time increase a global counter. Once we reach a certain limit we use ESLint's reporter API to raise a complaint.
Now this is a very ESLint specific syntax but you could build a similar script without building an ESLint plugin. We could for example use the underlying espree library to do the parsing and traversing of nodes manually using a basic Node.js script.
This script manually reads a file, parses it using espree and then checks every top-level node and whether it is a ClassDeclaration at which point it will increase a local counter. Once it's done it checks if the count is bigger than expected and will throw an error.
As you can see it involves quite the additional code compared to our previous example. Plugins for existing linters are certainly the more code efficient solutions but sometimes you want to have more control or want to ship a linter independent tool.
If you search npm you'll also find a collection of other tools to parse and traverse ASTs. They typically differ in API design and occasionally in JavaScript parsing capabilities. Some common examples are acorn and esprima for parsing or estree-walker for traversing ESTree compatible trees.
Modifying/Transforming ASTs
As previously covered, having an AST makes modifying said tree easier and safer than modifying the code as tokens or a raw string. There's a wide variety of reasons why you might want to modify some code using ASTs.
Babel for example modifies ASTs to down-transpile newer features or to turn JSX into function calls. Which is what happens when you compile your React or Preact code for example.
Another use case would be bundling code. In the world of modules, bundling code is often much more complex than just appending files together. Having a better understanding of the structure of the respective files makes it easier to merge those files and adjust imports and function calls where necessary. If you check out the codebases of tools such as webpack, parcel or rollup you'll find that all of them use ASTs as part of their bundling workflow.
A use case that might seem less obvious is test coverage. Have you ever wondered how code coverage tools such as Istanbul determine your test coverage? I certainly did. The tl;dr is that they inject additional code that is increasing different counters for every line, function and statement. That after all your tests ran they can inspect said counters and give you a detailed insight in what has been executed and what hasn't. Doing this without ASTs is both incredibly difficult as well as less predictable. I found this article explaining what's happening under the hood of test coverage tools that you can check out if you want to learn more.

Now all of these are tools that you likely won't write a lot yourself. But there is one use case that can be beneficial for your regular development flow. And that's doing code modifications for optimization, macros or to update larger parts of your code base all at once.
The React team for example maintains a collection of scripts called react-codemod that can perform common operations related to updating your React version. The tool they use under the hood is called jscodeshift and we can use that to write our own transformation scripts as well.
Let's say we for example love debugging using alert() but we want to avoid shipping that to our customers. We could write a script such as the following to replace all calls to alert with console.error without worrying that we might override something like myalert().
If you want to check out this example, head over to AST Explorer.
You can also use the same skill set to build for example your own Babel or ESLint plugins that will perform code fixes for you.
Printing ASTs
In most cases printing and modifying ASTs go hand in hand since you'll have to output the AST you just modified. But while some libraries like recast explicitly focus on printing the AST in the same code style as the original, there's also a variety of use cases where you want to explicitly print your AST differently.
Prettier for example uses ASTs to reformat your code according to your configuration without changing the content/meaning of your code. The way they do it is by converting your code into an AST which is completely formatting agnostic and then rewriting it based on your rules.
Common other use cases would be to print code in a different target language or build your own minification tool.
There's a couple of different tools you can use to print ASTs such as escodegen or astring. You could also go all in and build your own formatter depending on your use case or build a plugin for Prettier.
What's next?
We barely scratched the surface of awesome things you can build with ASTs. One of my favorite examples we didn't cover is Esper.JS. It was developed by the folks at CodeCombat to allow people to write Python and other languages in the browser and execute them on a step-by-step basis for educational purposes. All of that is heavily powered by parsing the different languages into an AST that's compatible with a JavaScript AST and then modifying it accordingly for execution.
While ASTs might be things most developers don't work with on a daily basis I believe they are a useful tool to have in your toolbelt. What are some use cases of ASTs that you have seen that are not covered here? I'd love to hear about them!
- Twitter: @dkundel
- Email: dkundel@twilio.com
- GitHub: dkundel
- Web: dkundel.com
Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.