Data Streaming with Kafka and Twilio Messaging
Time to read:
June 03, 2025
Written by
Reviewed by
Explaining Data Streaming using Kafka and Twilio Messaging
The ability to handle and process data in real time has become a critical requirement for many businesses. From sending instant notifications to managing live updates, companies need systems that can process vast streams of data quickly and efficiently. This is where data streaming comes into play, offering a way to continuously ingest, process, and analyze data as it flows in from various sources.
At the core of many real-time data architectures is Apache Kafka, a robust distributed streaming platform designed to handle high-throughput, fault-tolerant data streams. It excels at delivering data streams reliably between producers and consumers, making it a go-to solution for enterprises requiring real-time data processing.
In this article, you’ll learn how Kafka’s real-time streaming capabilities can be combined with Twilio’s messaging services to create efficient, scalable, and responsive communication systems. Whether you’re working on an alert system, notifications for customer transactions, or any other real-time data application, this guide will walk you through the integration of these two powerful tools.
Prerequisite
Here are what you need to follow along in this tutorial
- Node.js installed
- A free Twilio account ( sign up with Twilio for free).
- A Kafka server (locally or live) or Docker/ docker-compose is installed in your local machine.
- Install Ngrok and make sure it’s authenticated.
What is Apache Kafka
Apache Kafka is an open-source distributed streaming platform designed for building real-time data pipelines and streaming applications. It was originally developed by LinkedIn to handle their own data needs but was later open-sourced in 2011. Kafka is now widely used by companies across various industries to handle high-throughput, low-latency data streams.
Kafka's architecture revolves around publish-subscribe messaging, where producers publish data to Kafka topics, and consumers subscribe to those topics to read the data. This model allows for the decoupling of producers and consumers, enabling Kafka to handle a wide variety of use cases from real-time analytics to event sourcing. Kafka’s key components include:
- Topics: The message categories or queues to which producers send messages.
- Producers: Clients that send data to Kafka.
- Consumers: Clients that read data from Kafka topics.
- Brokers: Kafka servers that handle the persistence and distribution of data across multiple nodes.
Kafka stands out because of its fault-tolerance, horizontal scalability, and ability to handle massive volumes of data with very low latency. It is often used in scenarios such as event streaming, monitoring, and log aggregation—making it ideal for businesses needing real-time insights and notifications.
Use case with Twilio WhatsApp API
There are many use cases where we can utilize Kafka and Twilio Messaging API to handle data ingestion and messaging in services or applications. In this section, we will be building a proof of concept for real time monitoring and alert systems for a financial institution. This service detects when a transaction exceeds a threshold in the data pipeline and triggers a notification to the admin via WhatsApp and flag the account for review.
Setting up Twilio account
To set up our Twilio account, sign up for an account and login into your Twilio Console using your account details. From the toolbar's Account menu, select API Keys and Tokens. Take note of the test credentials as shown in the photo below, which include the Account SID and Auth Token, we will use them later in your application.
Setting up Twilio WhatsApp Sandbox
Access your Twilio Console dashboard and navigate to the WhatsApp sandbox in your account. This sandbox is designed to enable us to test our application in a development environment without requiring approval from WhatsApp. To access the sandbox, select Messaging from the left-hand menu, followed by Try It Out, and then Send A WhatsApp Message. From the sandbox tab, take note of the Twilio phone number and the join code. We will add the Twilio WhatsApp phone number to our .env file for later use.
Building the application services
Now that we have our Twilio account and sandbox set up, let’s get into building the demo application. Remember, this application ingests streams of transaction data via Kafka from one service to another and triggers a notification when a certain threshold is exceeded using Twilio.
First, create a new directory for the project and navigate into it:
Then, create a new Node.js project using the npm command:
Next, install the following dependencies:
- dotenv: Zero-dependency module that loads environment variables from an env file into process.env.
- express: Minimal Node.js web application framework.
- kafkajs: Kafka client for Node.js.
- node-cron: Simple and lightweight cron-like job scheduler for Node.js.
- twilio: Twilio Node.js client SDK for utilizing Twilio in Node.js applications.
- faker-js: Module for generating dummy fake data for our data ingestion.
The next step is to create a new file named .env and add the following environment variables:
Setting up Kafka producer and consumer
Now, with the app setup, let's create the services for the application.
We need two services:
- one to stream the transaction data. We will be using a dummy transaction generator.
- another to consume the data streams, store them in MongoDB database and check for suspicious transactions to trigger alerts.
To this end, we will create two new directories named app-producer and app-consumer in the root directory and add two new files called index.js and Dockerfile to each. For the app-producer/index.js file, we'll add the following code.
app-producer service:
Here are key functions and logic from the code above:
- We used the express framework to set up the service and make it listen to a port defined for the first service.
- Initialize a Kafka connection using the Node.js client library and setting up the producer with a retry mechanism.
- We define three logic, generateTransactions(), sendToKafka() and the cron scheduler. The generateTransactions user faker to generate 200 transaction data, sendToKafka() streams it to the Kafka server we initialized for consumers listening to use and the cron scheduler runs the transaction generation every 5 minutes.
- We also defined a health check route to confirm our service is in shape.
- On start, the generateTransactions() function runs and reruns every 5 minutes.
For the consumer service, the directory will have an extra file called model.js for setting our MongoDB schema. The file will contain the code below:
After that, we will add the following code to the app-consumer/index.js file. This entry file will handle the data ingestion to the database and handle the alert logic.
app-consumer service:
Just like the producer code, here are key functions and logic from the code above:
- We used the express framework to set up the service and make it listen to a port defined for the second service.
- Initialize a Kafka connection using the Node.js client library and setting up the consumer with a retry mechanism.
- We define four logic, sendAlert(), saveTransactionToMongo(), processMessage() and the startConsumer() functions. The startConsumer() uses the consumer client setup to subscribe to the topic called transaction-data coming from the producer services. It then processes each transaction in the array using the processMessage() function. The processMessage() function handles the ingestion to the database using the saveTransactionToMongo() function and if the particular transaction data exceeds a set amount, it triggers the sendAlert() function which uses Twilio messaging.
- We also defined a health check route to confirm our service is in shape.
- On start, the startConsumer() function runs and subscribes to the Kafka stream from the producer service. Also the app makes a connection to MongoDB to confirm it is running and initializes the Twilio client too.
Containerizing and running the app
For easy and speedy setup for MongoDB database and Kafka server, we will be running their official docker images locally together with both app-producer and app-consumer services. To get started, add the code below to the individual Dockerfile we created earlier for each services:
app-producer/Dockerfile:
app-consumer/Dockerfile:
The next step is to create the docker-compose.yml file in the root directory. This is where we will define and configure all the services we want to run in a container. Add this code to the docker compose file you created.
docker-compose.yml:
This file will pull the images of the defined services with the configurations(ports, environment variable, settings) provided. Kafka for data streaming, Zookeeper to provide the clustering system that Kafka uses, MongoDB for the database and the two services we created to generate transactions and ingest it respectively.
Testing the app
At this stage, our application is ready to be used or tested. In your terminal where your project directory is opened, run the command below to pull the docker images and start them.
This command runs the docker container in a detached mode meaning the logs will not be outputted to the terminal as the services start running(not when the images are downloading).
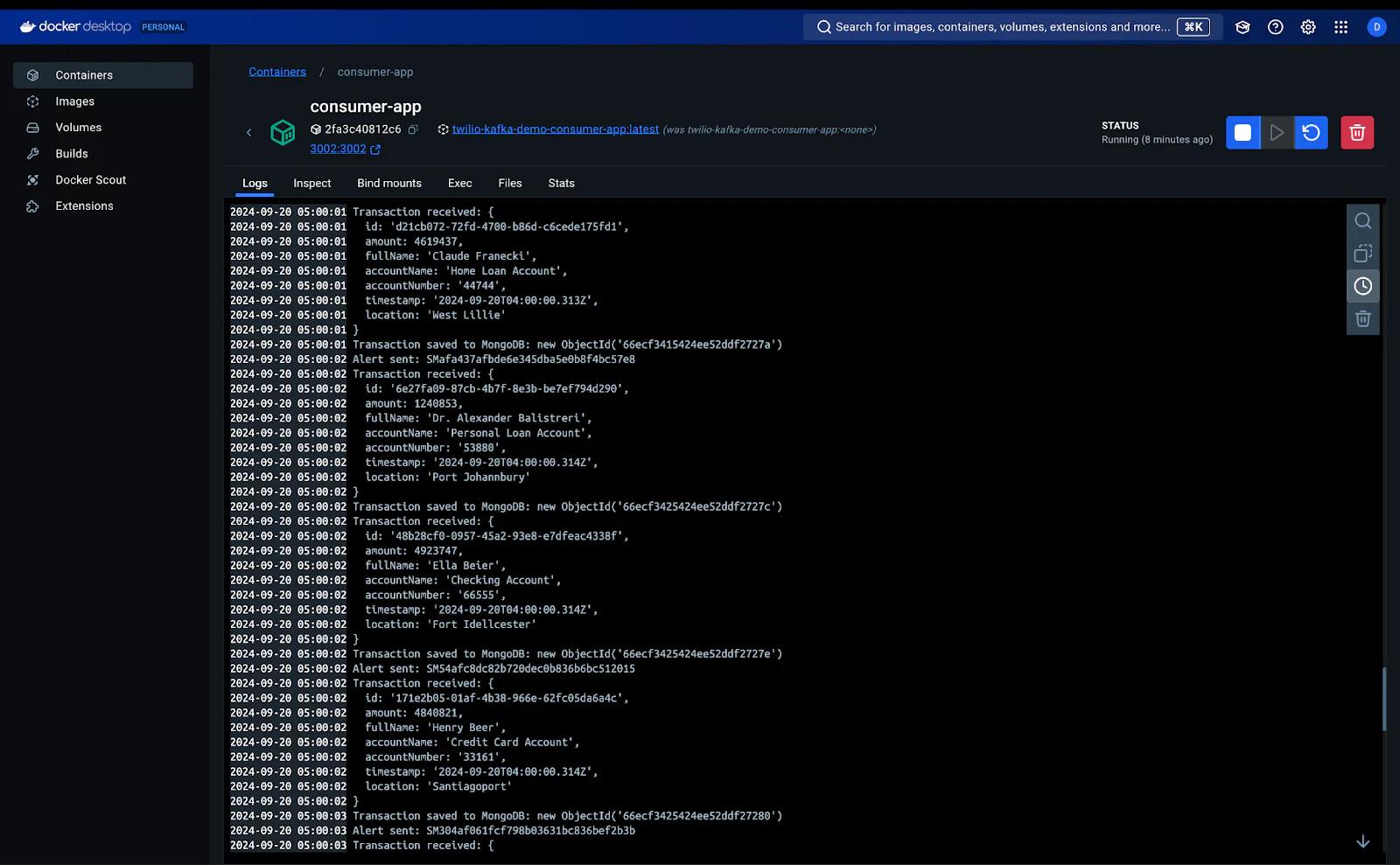
To see how the producer and consumer app are streaming and ingesting data respectively, we will use the Docker desktop app to check the logs or run the command docker compose logs to see the logs from the services.
app-producer service log

app-consumer service log
WhatsApp alert for over the threshold transactions

Common challenges and best practices for data streaming
When working with data streaming, especially at scale, several challenges can arise. Addressing these challenges effectively requires adopting best practices that ensure the system runs smoothly while maintaining reliability and performance. Here are some common challenges and the corresponding best practices for mitigating them:
Handling Message Latency
Challenge: Delays between producing and consuming messages can impact real-time performance.
Best Practice: Use Kafka's in-built compression and partitioning to optimize message delivery times. You should also fine-tune the replication factor to ensure data redundancy without compromising speed.
Scaling Kafka for High Throughput
Challenge: As data volume grows, ensuring consistent performance becomes difficult.
Best Practice: Use horizontal scaling by adding more brokers and creating more partitions for topics. Proper partitioning allows Kafka to handle large amounts of data across distributed systems, balancing load efficiently.
Message Delivery Reliability
Challenge: Ensuring that messages are not lost or delivered multiple times can be complex in distributed systems.
Best Practice: Leverage Kafka’s exactly-once semantics (EOS), which ensures that messages are delivered exactly once, even in the case of network failures. Implement consumer groups to ensure load balancing and fault-tolerance for consumers.
Security and Access Control
Challenge: Exposing Kafka topics to the public or unauthorized users can lead to data breaches.
Best Practice: Use SSL encryption and SASL authentication for securing Kafka clusters. Ensure fine-grained access control using Access Control Lists (ACLs) to manage who can produce or consume messages from specific topics.
Monitoring and Observability
Challenge: It can be difficult to monitor Kafka’s performance and troubleshoot issues.
Best Practice: Use monitoring tools like Prometheus and Grafana for real-time insights into Kafka clusters. Also, utilize Kafka’s built-in metrics to track throughput, lag, and error rates for early detection of potential issues.
Rounding up
Combining the power of Apache Kafka’s real-time data streaming capabilities with Twilio’s robust messaging platform allows you to build scalable and responsive communication systems. Kafka ensures seamless data flow across distributed systems, while Twilio provides the necessary tools to notify users in real time via SMS, WhatsApp, or other channels.
Whether you're building an alert system, processing financial transactions, or managing customer engagement, Kafka and Twilio can be integrated to create a powerful, real-time communication pipeline. By following best practices, addressing common challenges, and ensuring proper scaling and security, you can build a system that not only meets the demands of real-time data processing but also grows with your business needs.
You can learn more about transactions by referring to:
Desmond Obisi is a software engineer and a technical writer who loves doing developer experience engineering. He’s very invested in building products and providing the best experience to users through documentation, guides, building relations, and strategies around products. He can be reached on Twitter , LinkedIn, or through email at desmond.obisi.g20@gmail.com .

Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.