Bridging Legacy and Future Platforms
Time to read:
April 07, 2021
Written by

Twilio’s sustained growth over the last decade has led to several architectural iterations of the Twilio Console. With each iteration, comes changes to handle the biggest problems of the time. The next generation of the Twilio Console is no exception!
The previous post covered some of the challenges and issues we solved from the UX perspective. In this post, we’ll walk through how and why we went about migrating from the legacy Console to the new Console experience safely (spoiler, iframes were involved).
Legacy Console
In the previous iteration of the Twilio frontend architecture, the legacy Console was constructed in the Micro-Frontend pattern where each product team would have control over their content. The shell around the content was responsible for handling navigation between products, search, and settings for accounts and users.
The proxy layer orchestrated this all by server-side rendering index.html, providing the HTML element for each product to render the content. Teams would configure the proxy to map certain paths to load their static assets, JS, and CSS via CDN. The proxy layer could also be configured to inject server-side rendered markup into the content, which was used mostly for backward compatibility from the previous iteration of the Console.
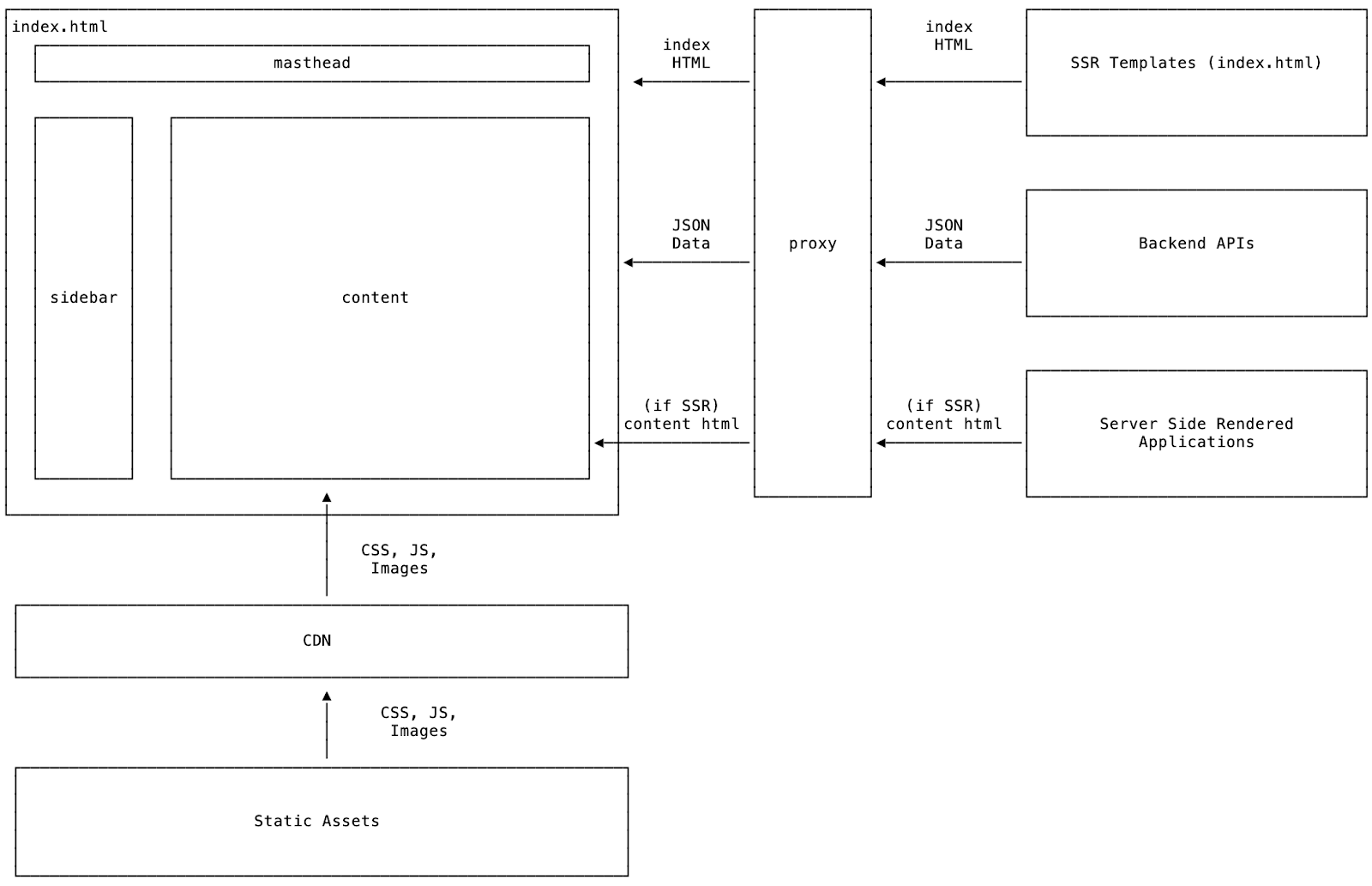
Legacy Console wins
In the Micro-Frontend architecture, teams had independent release cycles and autonomy over their tech stack. This allowed teams to migrate their products out of the original PHP monolith at their own pace and build tooling to support themselves. Over time, teams independently migrated more of the complexity to the frontend with React. To a certain extent, teams were able to share tooling and internal libraries, but they were maintained on a "best effort basis". Proxy configuration enabled teams to self-serve to configure which paths belong to products and their associated APIs.
Legacy Console issues
At first, the new architecture solved much of the tight coupling between teams' release processes. Over time, however, the longer-term effects of working independently were felt across the organization. Tooling, libraries, and tech stacks diverged as time went on, adding friction for teams to collaborate. With independently running teams, success and developer effectiveness were unevenly distributed. Some teams thrived while other teams struggled.
The isolated architecture did not allow the teams that were thriving to easily share what they learned across the organization, so innovation was isolated at the team level. In more extreme cases, some teams had to make the tough decision to not migrate from server-side rendered applications (mostly PHP) when weighed against all of their other priorities. In other cases, teams could only do the initial migration (React) to client-side rendered applications and had limited time for maintenance, so products slowly degraded over time.
Rendering the index.html server-side in the proxy allowed teams to inject their HTML, JS, and CSS based on the request path. Teams could easily configure which paths belonged to a given product and enabled teams to work in parallel. However, this choice had some negative tradeoffs that lead to subpar performance impacting the customer experience.
The initial request from the browser would have to go to the proxy first to get the initial index.html, and then the JS bundles could be loaded from the CDN. The effect was that the initial request had to go to the nearest proxy, in the worst case leading to a full second before the first byte made it to the customer.
Another impact to performance occurred when switching between products, switching from messaging to phone numbers for example. Within a given product, routing could be handled on the client to avoid a full page reload. However navigating between two products would result in a full page reload so the browser could fetch the other product’s HTML, CSS, and JS bundles.
Considering the previous architecture, these were big improvements and the right trade-offs to be made at the time. Twilio’s rapid growth in terms of customers, number of products, and engineers eventually made this architecture obsolete. Let’s move on to how we went about building the next iteration of Twilio Console.
Ruthlessly prioritize: Choosing which problems to solve
The next step was to start to prioritize the issues we wanted to fix, keeping in mind the future of the company and the growing customer base. The new architecture needed to handle a more globally distributed customer base and order of magnitude more engineers. This meant two key focus areas around improving performance globally and making it easier for teams to build on a shared set of tooling.
Related to performance, this meant pulling the proxy out of the initial render path and moving towards a Jamstack architecture. In the prototypical Jamstack architecture, the new Console would be built into static assets and pushed out to the CDN, that way the initial page load could be served close to customers around the world. Data would still come from the proxy which would route to each team's backend services. This architecture also addresses the issue with full-page reloads when working between products, since routing is handled client-side and applications are asynchronously loaded as chunks.
The other change was to address the issue with shared processes and tooling. The new architecture would have a clear owner, responsible for building and maintaining the frontend platform. The development would be done with the open source contribution model so that teams could influence the platform roadmap and make improvements available for all teams. The platform owner would be the decision-maker on platform-level changes. Platform level changes include (but are not limited to) improvements to CI, testing infrastructure, and common NPM libraries.
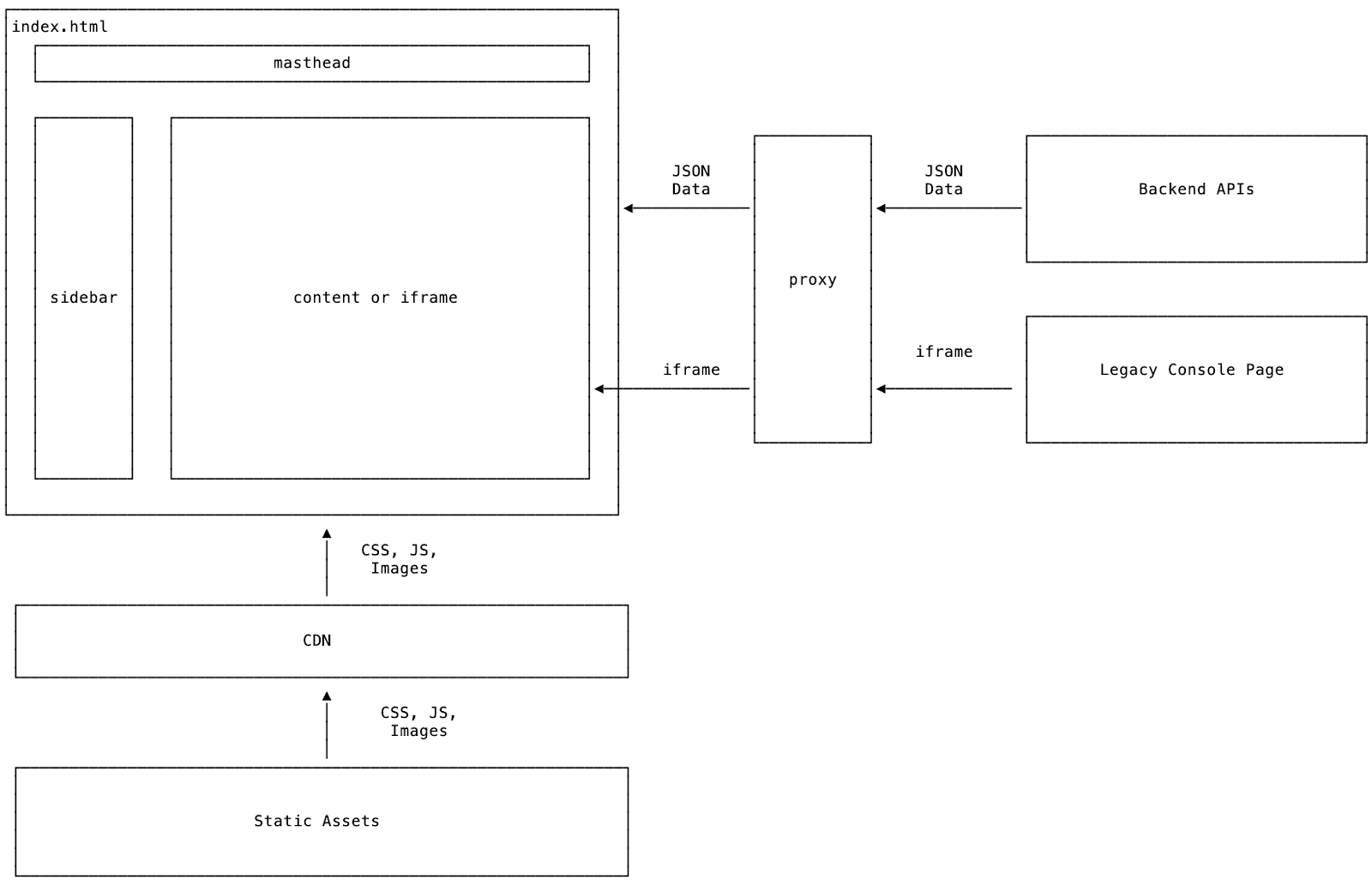
New console
The new architecture follows the Jamstack architecture and pulls the UI into a frontend monolithic repo. The navigation components (sidebar and masthead) are loaded from static assets from the CDN and allow customers to navigate between products. For migration purposes, product content can be loaded from the legacy console via an iframe or from a static asset. This allows teams to migrate at their own pace, rather than having to do a complete rewrite of the Console.
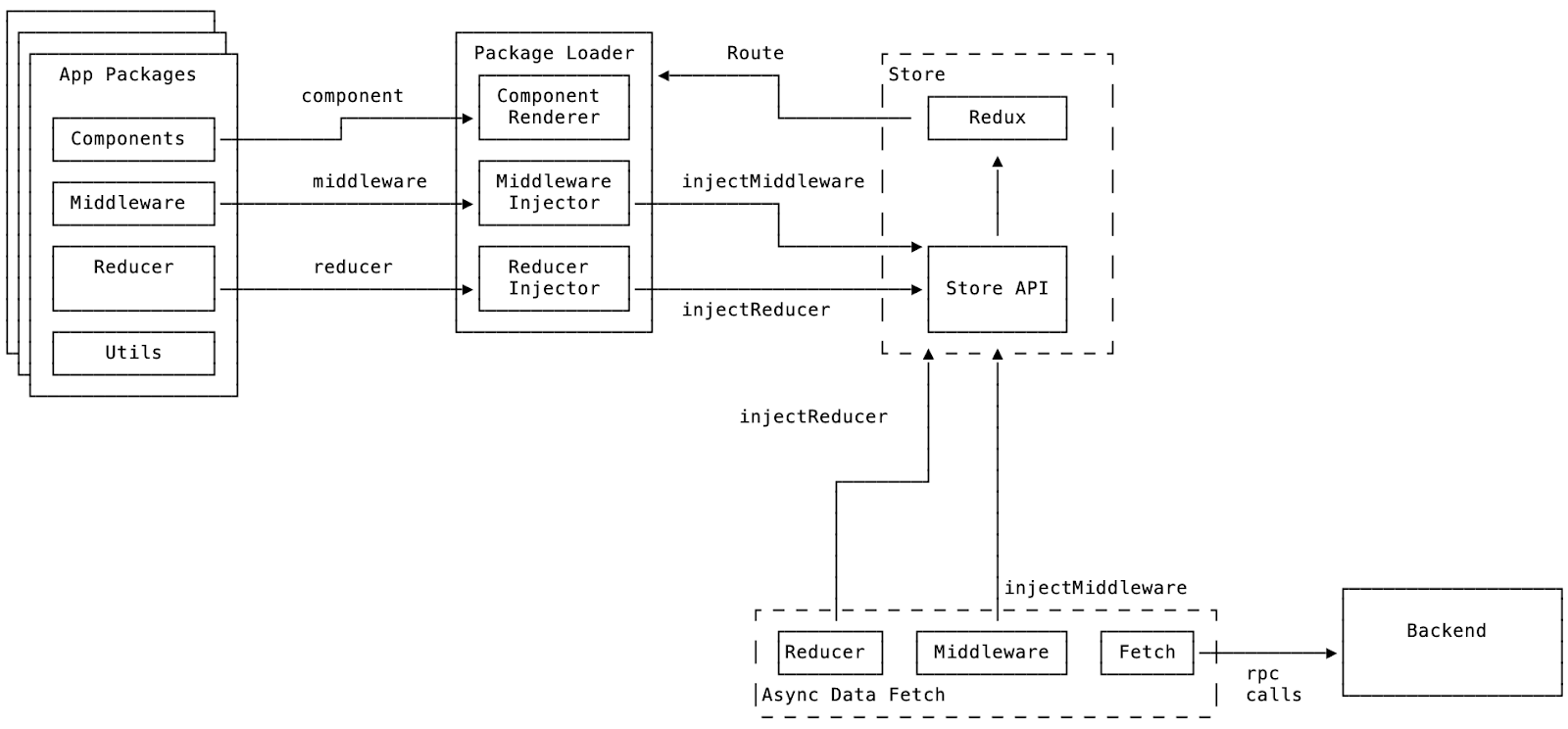
Products are loaded as application packages that contain a reducer, middleware, components, and tests. Application packages are loaded as chunks with React Suspense within error boundaries so they are unable to impact other products.
Migrating to the monolithic repo
One of the design constraints for the architecture was to minimize the impact of migrating an application. Requiring teams to do a complete rebuild all at once was too much of a burden to place on product teams. The level of effort would vary based on the tech stack. For example, teams on React would have an easier time than teams starting from a server-side rendered PHP application.
To meet the constraints we built a system to enable teams to migrate a single page route at a time. By default, pages from the legacy Console are loaded within an iframe and when a team is ready to migrate a page they can override the configuration for a specific route (or a subset of routes). The configuration would include a bundle to load in the content:
export let routerCollection: RouterItem[] = [
{ route: "/productOne", bundle: "ProductOneBundle" },
{ route: "/productTwo", bundle: "ProductTwoBundle" },
// ... other products
];By breaking the problem down per page route, we estimate that most teams will be able to complete parts of the migration within a sprint (for most Twilio teams this is ~2 weeks). Teams with more expensive migrations can work at their own pace since the legacy Console pages will continue to function.
Building new applications
When product teams are ready to start migrating or building their application the first choice they need to make is which set of routes they want to handle. The routing configuration is used to determine which bundle to load at runtime. An application bundle exports the display logic (a React component) and, optionally, state management (Redux reducer and middleware):
type ApplicationPackageType = {
component: ComponentType;
key?: string;
reducer?: Reducer;
middleware?: Middleware;
};
//Example application bundles:
// A component only application
export default ApplicationPackage({
component: () => <h1>Simple App</h1>,
});
// Typical Application will export everything
export default ApplicationPackage({ component, key, reducer, middleware });When a route match is found the application bundle is loaded async with React Suspense, the exported React component is rendered, and if the reducer or middleware are exported each is injected into the Redux store. The bundle is cached so that the next time a matching route occurs subsequent load times are minimal.
Contrasting the previous and new architectures, teams do not need to think about building an entire React application with state management from scratch and can focus on creating the business logic that benefits customers. In addition, teams can write Storybook stories and different kinds of tests by using the following file syntax in their application packages:
*.story.ts # storybook story
*.test.ts # unit/integration tests
*.e2e.ts # e2e testsThis allows teams to stay focused on writing tests and stories, rather than needing to think about setup and configuration. The approach also enables a shared configuration of stories and tests so that fixes, improvements, and maintenance can be done across the entire application.
When a team is ready to make a change they modify the codebase and submit a pull request. We use a CODEOWNERS file to track who owns certain parts of the codebase. If the files changed in the pull request are exclusive to their team’s application bundle they only need to get a +1 from their team.
If files outside of their application are modified, say the package.json file, for example, the team would need to get a +1 from the Console team in order to merge the change. With each change in a PR, all linting, testing, validation, etc. is run and if everything is successful a preview deployment is generated with a unique URL. Links to the preview deployment are sent back to the PR in comments for easy access to internal Twilio developers. This makes it easy for team members to verify changes in an environment that is very close to production.
Once a PR is approved and all automated checks pass, the developer can merge the pull request to the main branch. The merge triggers another set of checks and deploys the change to the production environment. Operational metrics are automatically created for teams to build alerting/monitoring and are broken down per package. In the event that an error or performance issue occurs outside of an application package, the Console team will be alerted.
Looking forward
While we’re still early in the migration process, we’ve learned something from each team as they’ve been onboarded. Treating product teams like our customers had led to improvements to documentation, the addition of critical features, and improvements to existing features like state management.
Since the governance model works similar to open source, teams can provide contributions indirectly by filing feature/bug requests or directly by submitting pull requests. By listening to our developers, the Twilio Console platform can continue to evolve and improve over time. This way we’re meeting the needs of our frontend developers who can build the right thing to meet the needs of our customers.



Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.