Loves Me, Loves Me Not: Classify Texts with TensorFlow and Twilio
Time to read:
February 12, 2020
Written by

Valentine's Day is coming up and both love and machine learning are in the air. Some would use flower petals to determine if someone loves them or not, but developers might use a tool like TensorFlow. This post will go over how to perform binary text classification with neural networks using Twilio and TensorFlow in Python. Text +16782767139 to test out this text classification.

Prerequisites
- A Twilio account - sign up for a free one here and receive an extra $10 when you upgrade through this link
- A Twilio phone number with SMS capabilities - configure one here
- Set up your Python and Flask developer environment - Make sure you have Python 3 downloaded as well as ngrok.
Setup

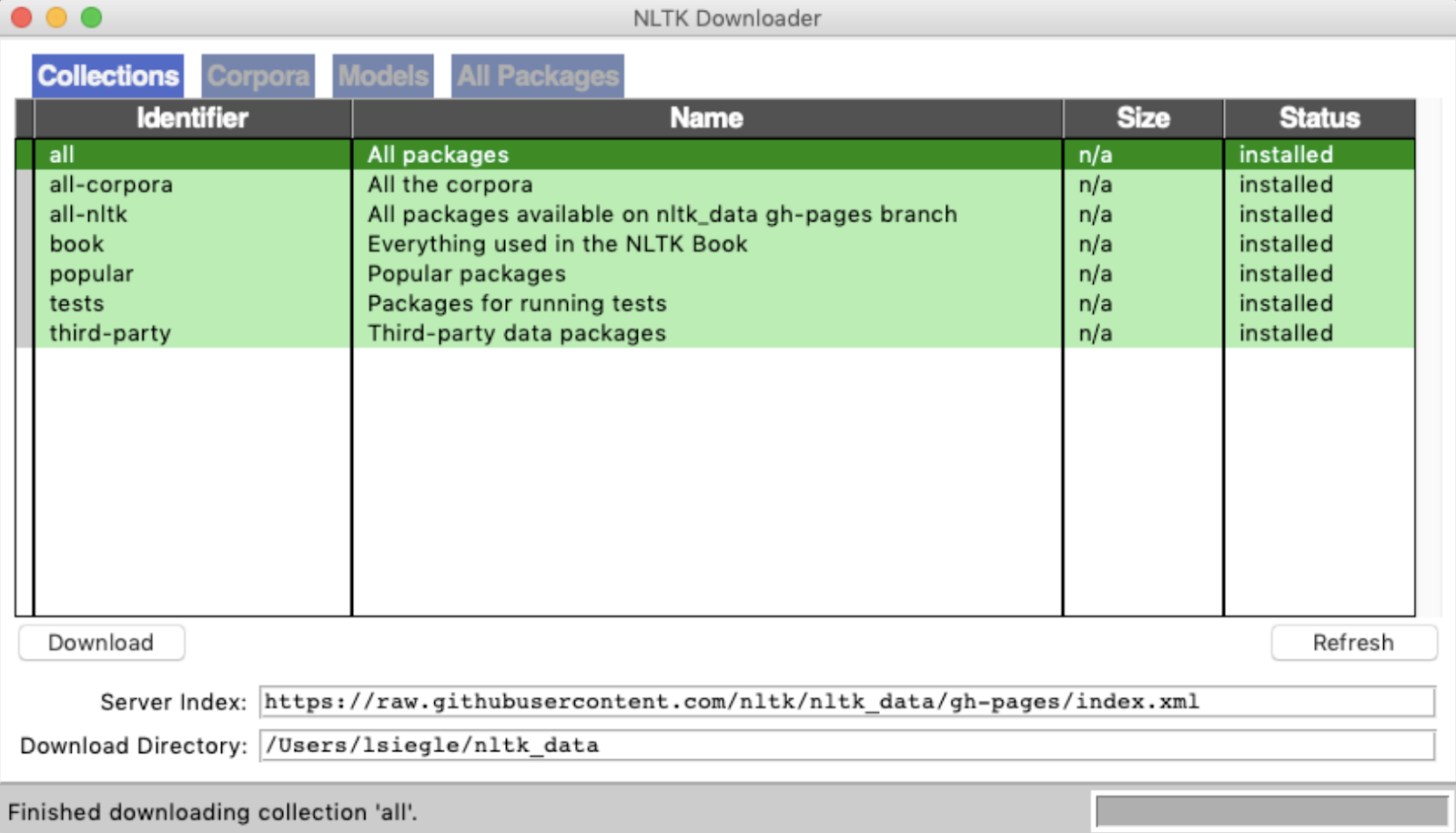
Activate a virtual environment in Python 3 and download this requirements.txt file. Be sure to use Python 3.6.x for TensorFlow. On the command line run pip3 install -r requirements.txt to import all the necessary libraries and then to import nltk, make a new directory with mkdir nltk_data, cd into it and then run python3 -m nltk.downloader. You should see a window like this, select all packages as shown in the screenshot below:
Your Flask app will need to be visible from the web so Twilio can send requests to it. Ngrok simplifies this. With Ngrok installed, run ngrok http 5000 in the directory your code is in.
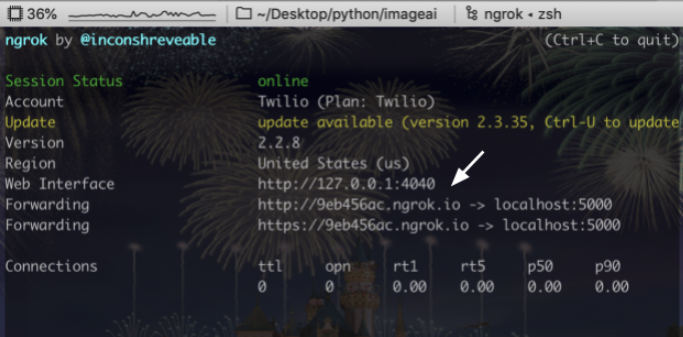
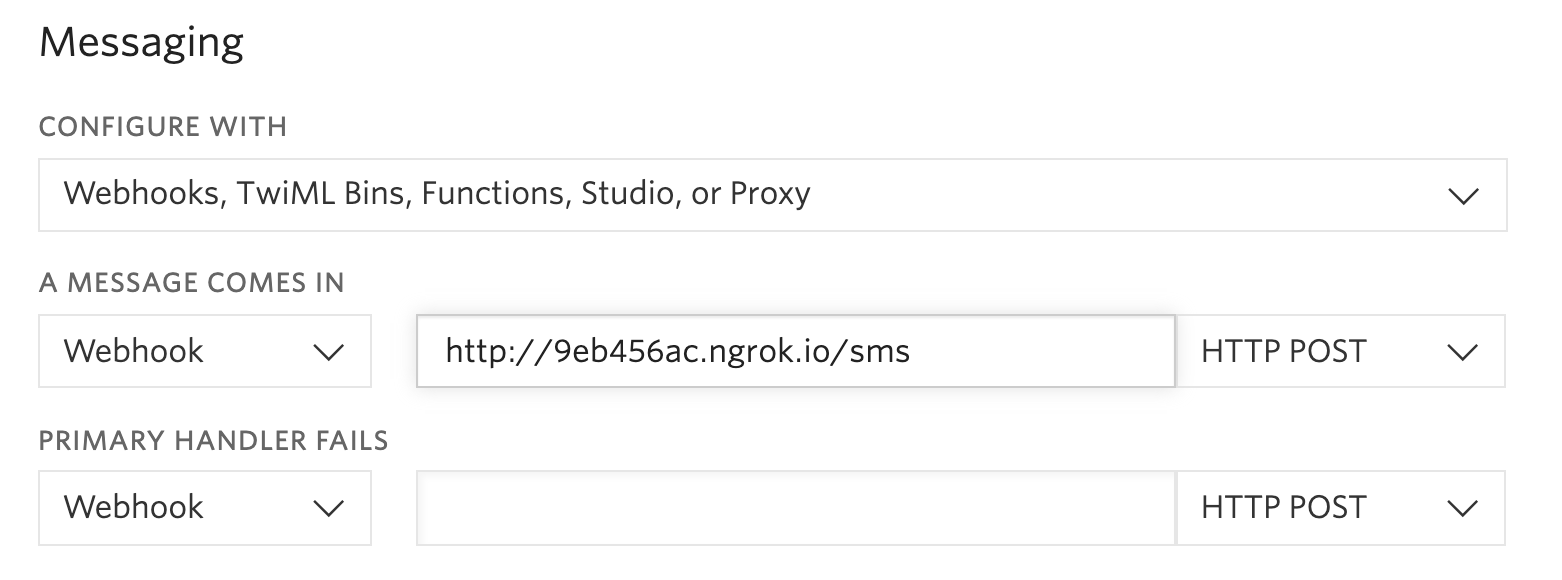
You should see the screen above. Grab that ngrok URL to configure your Twilio number:
Prepare Training Data
Make a new file called data.json to contain two arrays of phrases corresponding to labels: either "loves me" or "loves me not". Feel free to modify phrases to the arrays or add your own (the more training data, the better--this is not close to being enough but it's a fun start.)
Make a Python file called main.py. At the top import the required libraries, then make a function open_file to save the data from data.json as a variable data.
Read Training Data
This post will use a lemmatizer to get to the base of a word, ie. turning "going" into "go". A stemmer, which also reduces words to their word stem, could be used for this task but would be unable to identify that "good" is the lemma of "better." Though lemmas take more time to use, they tend to be more efficient. You can experiment with both stemmers and lemmatizers when working with natural language processing (NLP).
Right underneath the data variable declaration, initialize the lemmatizer and make this function to stem each word:
This next function will read the training data, remove punctuation, handle contractions, and extract words in each sentence, appending them to a word list.
Next, get the possible labels ("loves me" and "loves me not") that the model will train for and initialize an empty list json_data to hold tuples of words from the sentence and also the label name. The training_words list will contain all the unique stemmed words from the training data JSON and binary_categories contains the possible categories they could classify as.
The json_data returned is a list of words from each sentence and either loves_me or loves_me_not; for example, one element of that list is ([“do”, “you”, “want”, "some", "food], “loves_me”). This list does not cover every possible contraction but you get the idea:
Then stem each word to remove duplicates and call the read_training_data function.
For TensorFlow to understand this data the strings must be converted into numbers. This can be done with the bag-of-words NLP model, which keeps a count of the total number of occurrences of the most commonly-used words. For example, the sentence "Never gonna give you up never gonna let you down" could be represented as:

For the loves_me and loves_me_not labels a bag-of-words is initiated as a list of tokenized words, called vector here. We loop through the words in the phrase, stemming them and comparing with each word in the vocabulary. If the sentence has a word in our training data or vocabulary, 1 is appended to the vector, signaling which label the word belongs to. If not, a 0 is appended.
At the end our training set has a bag of words model and the output row corresponding to the label the bag belongs to.
Convert training to a numpy array so TensorFlow can process it as well, and split it into two variables: data has the bag of words and labels has the label.
Now reset the underlying graph data, and clear defined variables and operations from the previous cell each time the model is run. Next build a neural network with three layers:
- The
input_datainput layer is for inputting or feeding data to a network, and the input to the network has sizelen(data[0])for the length of our encoded bag of words and labels. - Then make two fully-connected intermediate layers with 32 hidden units or neurons. While some functions need more than one layer to run, more than three layers probably won't make a difference, so two layers is enough and shouldn't be too computationally-expensive. We use the
softmaxactivation function in this case because the labels are exclusive. - Lastly, we make the final net from the estimator layer, like regression. At a high level, regression (linear or logistic) helps predict the outcome of an event based on the data. Neural networks have multiple layers to better learn more complicated abstractions relationships from the input.
A deep neural network (DNN) automatically performs neural network classifier tasks like training the model and prediction based on input. Calling the fit method begins training and applies the gradient descent algorithm, a common first-order optimization deep learning algorithm. n_epoch is the number of times the network will see all the data and batch_size is the size data is sliced in to for the model to train on.
Similar to how the data for the bag-of-words model was processed, this data needs to be converted to a numerical form that can be passed to TensorFlow.
To test this without text messages you could add
This calls the predict method on the model, getting the position of the largest value which represents the prediction.
We will test this with text messages by building a Flask application.
Create a Flask App
Add the following code to make a Flask app, get the inbound text message, create a tensor, and call the model.
Open a new terminal tab separate from the one running ngrok. In the folder housing your code run and text your Twilio number a phrase like "get someone else to do it" and you should see something like this:

The complete code and requirements.txt can be found on GitHub here.
What's Next

What will you classify next? You could use TensorFlow's Universal Sentence Encoder to perform similar text classification in JavaScript, classify phone calls or emails, use a different activation function like sigmoid if you have categories that are mutually exclusive, and more. Let me know what you're building online or in the comments.
- GitHub: elizabethsiegle
- Twitter: @lizziepika
- email: lsiegle@twilio.com


Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.