Common SMS Problems and How to Solve Them, Part 2 (Unicode)
Time to read:
August 31, 2015
Written by

Earlier this month we walked you through a common SMS delivery challenge that occurs when sending long messages, and how a developer can address it successfully. In this post, we’ll show you how the many different languages and characters that can be sent in an SMS can also cause complications – and that it’s not necessarily easy to send them all.
[Read Common SMS Problems + How To Solve Them Part 1 to learn how about to ensure that long messages (which need to be broken up to be sent) are delivered in the correct order].
The Wrench: Compatibility with Emojis, Kanji, and Other Characters
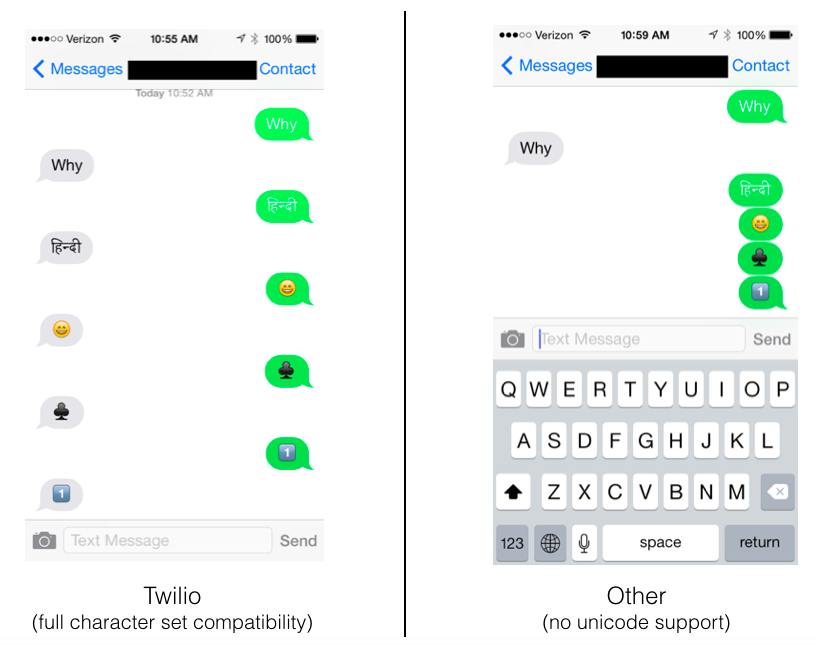
How many times a day do you receive one of these a smiley face or thumbs emoji? What about 漢字or العربية? When developers build an SMS app, they need to take extra steps to ensure all your thumbs up emojis, kanji, arabic, and smiley faces are sent and received properly. If they don’t, these messages may show the dreaded ☐, or worse – nothing at all.
We tested two different messaging APIs (Twilio and another) to echo back inbound messages that contained a variety of different characters. You can see the results below. The left example uses Twilio’s API with unicode support, and the API on the right doesn’t support it.
Encoding
To avoid the above problem, the first thing a developer typically needs to do is programmatically determine which character set to use. They then need to pass this information to the SMS gateway (the mechanism to send SMS) they’re using for the message to be sent with proper encoding.
Additionally, developers need to check that the API or SMPP gateway they use supports the encoding that they need. They need to verify, for example, that the provider they select can encode both the characters sent by their end users (eg emoji, kanji) AND encode the character sets required by the receiving user’s phones (eg GSM).
The trouble is some character sets are harder for these providers to encode than others. The character set GSM 3.38, for example, is not natively supported by most programming runtimes, and therefore is extremely challenging to support. Some providers decide the juice isn’t worth the squeeze and choose not to support the troublesome character sets.
So what happens if a provider does not to support GSM, for example? If either the user sending a character – or a user receiving that character – is using a carrier that requires GSM encoding, the message will not pass through correctly (eg ☐) or will be dropped entirely. To specify, even though an SMS gateway supporting SMPP 3.4 may support many character encodings (like ISO 8859-1, ISO 8859-8, ISO 8859-5, IA5), the message will eventually need to get converted to GSM 3.38 when sending to most GSM/3G handsets. And because that Gateway does not support GSM, the message will not pass through correctly despite any initial encoding compatibility.
The Solution: Unicode with Broad Compatibility & Character Recognition
Twilio makes developers lives easier here. First, we’ve built in a recognition feature that automatically recognizes which kind of encoding a particular message needs. We then take those characters and encode them appropriately for sending to the SMS gateway. This means that the developer does not need to delve into messages and figure out how to encode the characters from their code to an SMS gateway.
Second, we offer full unicode support (including non-BMP), which means we support nearly all human written languages and characters. We do this because we have customers in many locations around the globe, and want to ensure that messages are sent as expected no matter which language is being used or who the receiving carrier is (this is why we support GSM 3.38 despite the challenges).
Take a look at what was returned when we tried sending to two APIs that both support unicode, but do not have the same encoding options. These seemingly small technical differences can have a big impact on customer experience, because many people get frustrated when messages don’t get through or or received improperly.
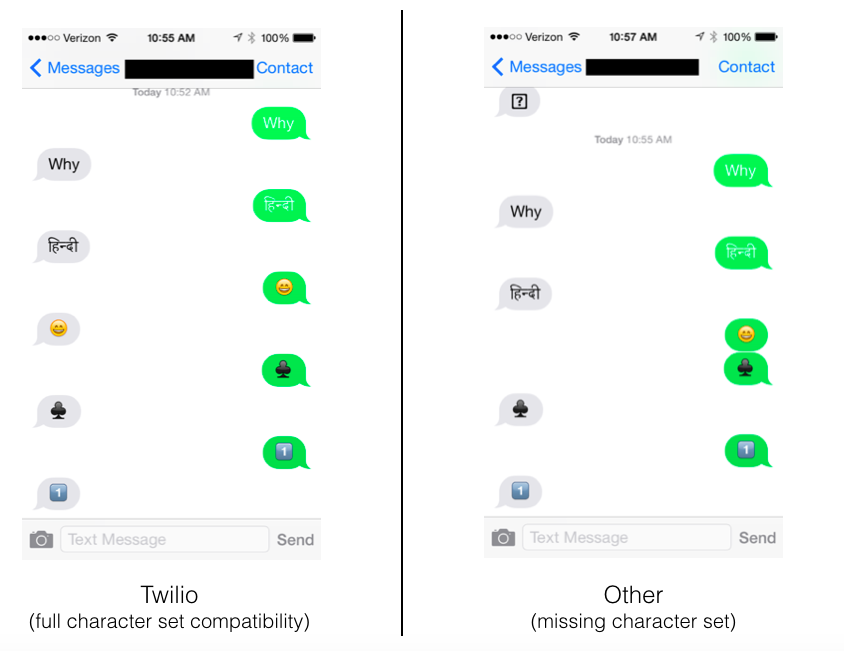
To delve deeper into unicode, check out our unicode glossary entry here.



Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.