Llamas on the Edge: Low-Latency Personalization with Segment, Cloudflare, and Llama 2
Time to read:
October 05, 2023
Written by
This post is part of Twilio’s archive and may contain outdated information. We’re always building something new, so be sure to check out our latest posts for the most up-to-date insights.
This post first appeared on the Twilio Segment blog.
Last week Cloudflare and Meta announced that Llama 2 is now available in the Cloudflare Workers platform. This makes Llama 2 accessible for developers, opening up new opportunities to build LLM-augmented experiences directly into the application layer.
Over at Twilio Segment, we have been really excited about the opportunities edge workers can unlock for analytics instrumentation & real time personalization. Last year, we introduced our Edge SDK to help app builders collect high-quality first-party data and run advanced personalization & experimentation with user context.
This year, as we’ve developed CustomerAI, we’ve been learning from some of the most advanced engineering teams in the world on how they’re planning to leverage LLMs and AI to adapt the application experience.
We heard three themes, loud and clear. To deploy AI in the application, developers are going to have to tackle 3 new challenges to put LLMs into production:
- LLMs need to operate closer to real time. Roundtrips and slow inference can break the customer experience - every millisecond counts!
- LLMs lack customer and domain context. AI experiences need to know where a customer is in the journey, what they’re looking for, and how to properly care for a them.
- LLMs struggle to “close the loop”. Dev and marketing teams need to understand how an AI experience impacts the overall customer journey (ex. conversion rate).
This is in addition to figuring out how to avoid hallucinations, model guardrails, and bake in customer trust and transparency – all areas that we’ve had to tackle in building Twilio CustomerAI.
In this post, we’re going to show you how to build a high-context, low-latency LLM app experience in just a little bit of code. We’ll combine Segment’s Edge SDK, Cloudflare Workers, and Llama-2, and talk through a couple of potential use cases you might explore on your own.
Ready to start building?
Meet Your Llama 🦙
Llama 2 is accessible in Cloudflare Workers, Node.js, Python, or from your favorite programming language via the REST API. You can see examples to help you set this up in the Cloudflare docs. What’s exciting about accessing your LLM through Cloudflare Workers is that since your LLM is located at the edge, latency is naturally minimized.
- There’s a great free playground to experiment with Workers here.
This certainly makes it easy to go and build something, but it doesn’t solve the whole problem on its own. In order for the LLM to do its magic, it needs context… without it, all the suggestions will be hollow, empty, and impersonal. 😅
Exploring the Edge 🧗
This need for context-awareness leads us directly to the value of Segment, and the premise of Twilio’s CustomerAI: people respond better when you treat them personally. Segment will enable you to do just that by collecting everything you know about them in one profile that gets shared out to your whole stack.
A major technical limitation that we encounter is that personalizations need to be decisioned and delivered with sub-second latency. - you have to retrieve the profile before you pass it into your LLM and then you have to decide how to respond once the LLM has processed the inputs; your personalization effort may end before it begins because the long wait times cause the customer to abandon the request and go elsewhere!
This is where the Edge SDK helps you - by moving the profile to the edge and minimizing the latency of profile requests, you can use the profile more liberally to personalize without risking long waits.
In order to use the Edge SDK, spin up a Cloudflare Worker and import as follows:
For a deeper dive into how to set up Edge SDK, check out this blog post.
Adding the Llama to the Edge
Now that we’ve seen the two parts, let’s put them together. If our Cloudflare LLM-powered Worker could accept profile data from our Segment Edge SDK, we’d have the ability to quickly enhance everything that the LLM provides with the context of the profile data. Now the LLM responses can be colored by all of the preferences and tendencies of the individual, and we’re not sacrificing a lot of round-trip time to achieve it.
We recommend rolling all of this into the same worker to minimize the code footprint, providing something like this:
And just like that, you can personalize the page using the Segment profile as your guide. Suddenly your nameless, faceless “visitor” gets VIP treatment with a customized poem when they arrive!
The Llama’s on the Edge. So what?
To add some chaos to this animal kingdom metaphor, we’ve got an elephant in the room: What do you expect to achieve by building this? What are some scenarios where realtime LLM-based responses that incorporate customer profile data would be beneficial?
I’d like to speak to a representative, please
Anyone who’s used a website chat bot in the past few years has probably felt this way… the experience is generally pretty terrible. Why? Because the bot just doesn’t know what it needs in order to effectively help meet my needs.
However, imagine a world where that bot now has instant access to everything required to know about me as a customer… no more annoying repeated questions about what product I ordered or what size or whether I can type in my 32-digit order ID number correctly or any of that.
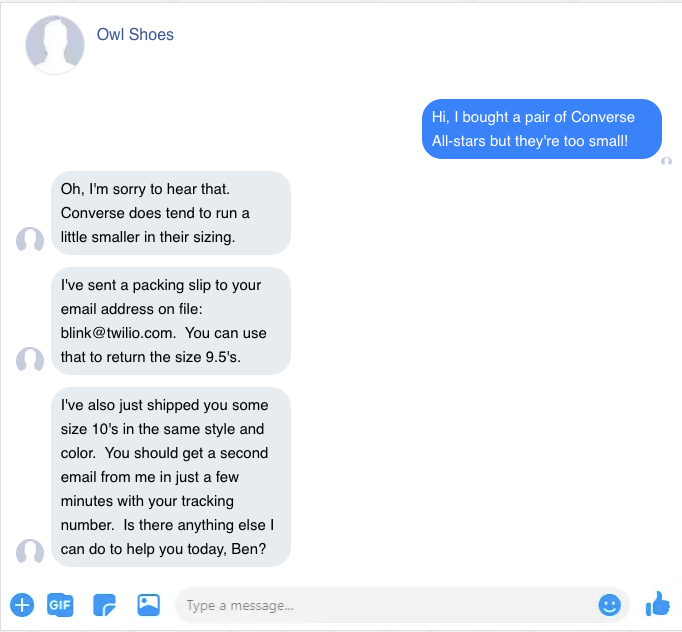
A customer who has this experience will feel seen and appreciated, just as if they interacted with a friendly associate in-store. Good customer service is anticipating your customer’s needs and fulfilling them without making the customer do more work!
A fully custom website experience for each and every person
Have you ever seen someone else’s Amazon homepage? It just feels… weird. All of their preferences and tastes and… nothing of your own.
What if every customer saw a completely personalized version of your website in that same fashion? You can personalize any call that your page makes, but you’d risk slowing things down every time you had to query the profile again. Moving the profile to the edge minimizes the expense of those calls, giving you the flexibility to personalize the experience however you see fit.
Live updates while you’re in our shop
What if you knew you could convert a sale simply by offering a coupon while the person was shopping in your store? If they happen to open your app and you detect their location is in or around your store, you can send them a live offering for an item that you know they’ve been eyeing to seal the deal. This of course has to happen very quickly - we don’t have time to send off for a lengthy event data processing job! Putting the LLM on the edge, where it can read the Segment Profile and take immediate action, ensuring that we deliver the offer to the customer before they get too far away.
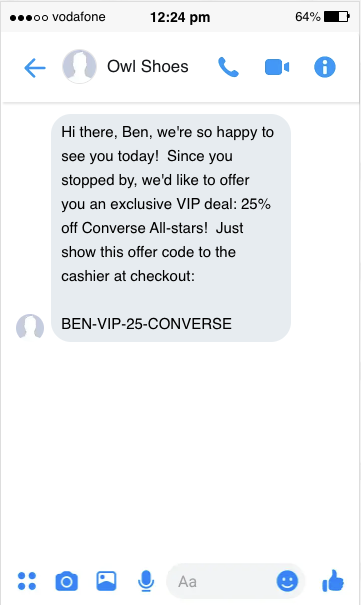
Whoa… I have my own coupon code? I may never have felt this special to a company before. I guarantee I’ll be visiting your store first in the future for all my footwear needs!
The bottom line
Great customer engagement at scale is a three-legged stool: you absolutely must have good data about your customer (provided by Segment!), a quality experience (provided by AI!), and minimal latency (on the edge with a Cloudflare Worker!). This combination of technologies will enable you to build systems that cultivate loyalty within your customers.
If you’d like to get started building customer profiles in Segment or collecting data on the Edge, sign up for a free workspace today.
Related Posts
Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.