Working with HTML on the Web Using Java and jsoup
Time to read:
September 16, 2019
Written by

So, you need to parse HTML in your Java application. Perhaps you are extracting data from a website that doesn’t have an API, or allowing users to put arbitrary HTML into your app and you need to check that they haven’t tried to do anything nasty?
Have you tried using regular expressions? It won’t end well. The author of that now-infamous text managed to recover from their distress enough to suggest using an XML parser (before, presumably, collapsing into the void). The problem with this is that an awful lot of the HTML in the world is not valid XML. People open tags without closing them, they nest tags wrongly, and generally commit all kinds of XML faux pas. Some non-XML constructs are perfectly valid HTML and admirably, browsers just cope with it.
To adopt the flexible and stylish attitude of web browsers, you really need a dedicated HTML parser, and in this post I’ll show how you can use jsoup to deal with the messy and wonderful web. You’ll see how to parse valid (and invalid) HTML, clean up malicious HTML, and modify a document’s structure too. At the end there is a small app which deals with real-world HTML.
Soup?
The WHATWG, who design HTML, have consistently decided that compatibility with previous versions of HTML and with existing web pages is more important than making sure that all documents are valid XML. Good for them - this lowers the barrier for contribution on the web and makes it more resilient for all of us.
Web browsers are therefore obliged to cope with:
- Mis-nested tags like
<strong>This <em>is</strong> mis-nested</em> - Unclosed tags like
<img src=”cute-dogs.gif”> - Misplaced tags like a
<title>inside the<body>of a document - Unknown tag attributes like
<input model="myModel"> - Made-up tags
and more…
With tags and bits of tags floating around all over the place, this kind of document became known as Tag Soup, hence the name “jsoup” for the Java library.
jsoup offers ways to fetch web pages and parse them from tag soup into a proper hierarchy. You can extract data by using CSS selectors, or by navigating and modifying the Document Object Model directly - just like a browser does, except you do it in Java code. You can also modify and write HTML out safely too. jsoup will not run JavaScript for you - if you need that in your app I'd recommend looking at JCEF.
How to add jsoup to your project
jsoup is packaged as a single jar with no other dependencies, so you can add it to any Java project so long as you’re using Java 7 or later. There are good instructions at jsoup.org/download and I have put all the code used in this post in a GitHub repo which uses Gradle to manage dependencies. To run the code from my repo you will need to have Java 11 or later.
A Few Spoonfuls of jsoup
We'll see a few examples of how to use jsoup, comparing how it interprets tag soup against Firefox. Then we'll see how to build a real app which can fetch data from the web on-demand.
Fetching and Parsing a Web Page
I’ve put a simple web page up at https://elegant-jones-f4e94a.netlify.com/valid_doc. It’s valid HTML5 according to the w3c html validator. Let’s use jsoup to fetch that doc and see what the title of the page is:
This prints out the page title “A Valid HTML5 Document” as expected.
Extracting Data by CSS Selector
Using the same URL as before, there are two <p> elements on that page with ids of interesting and uninteresting. Let’s use the id selector to pull out an interesting fact:
Run this and you’ll find out something rather interesting about owls.
Dealing with malformed HTML
So far what we’ve seen is useful, but not too surprising. Lets see how jsoup copes with something a little… soupier.
We’ll use the page I’ve created at https://elegant-jones-f4e94a.netlify.com/misnested_tags. The W3C validator does not like it, for a number of reasons - including the mis-nested tags <strong>This <em>is</strong> mis-nested</em>.
Firefox does a decent job of rendering it, with everything inside the <strong> tag rendered bold, and the <em> tag as italic.

The Firefox Developer Tools let us inspect the DOM that Firefox has created:
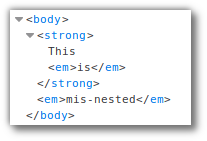
The <em> tag is closed and reopened to make a valid tree-structure DOM. How about jsoup?
The output is:
So JSoup has made the same decision as Firefox in parsing this. Not bad. An XML parser wouldn’t have done so well, and as for regex… I can’t bear to contemplate it.
Preventing XSS - stripping malicious tags
This case is a little different. Imagine that you have created a website which allows users to submit comments using HTML. A malicious user could try to include JavaScript code in a comment to run an XSS attack and hijack a user's session. If their XSS attack is successful they will be able to use your website as if they were logged in as any user who had seen the comment. Uh-oh.
In this case you would probably have the commenter’s HTML as a Java String, so let's see how jsoup can help here:
This prints:
then
I’ve used a preset called basicWithImages. There are a few others built in, or you can create your own custom one by extending this class or modifying an existing instance.
The onclick attribute has been removed from the <a> tag, which prevents the XSS. JSoup has also added rel=”nofollow”, which tells search engines not to consider this link when calculating the target page’s importance. This prevents comment-spamming to drive SEO for the target page. Try doing that with regex! (No, please don’t!)
Using jsoup on the Real Web
Let's write a Java method which takes a String, looks that item up on Wikipedia and returns the first sentence from the article about that thing. This process of programmatically extracting content from web pages is often known as web-scraping or screen-scraping, and can be quite fragile as you might need to change your code whenever the website changes the structure of its HTML.
We’ll use Wikipedia as an example of web-scraping using jsoup. Wikipedia does have an API, but it is a good example for our needs. If you want to code along, you can find the full code on GitHub.
First create a Java method which will do the summarizing. Use jsoup to fetch the page and handle any errors we encounter:
Next, extract the paragraphs in the main section of the page. These are the <p> elements inside the first <div> inside the <div> with id mw-content-text. We can use some CSS selectors here: > (child) and :first-of-type:
Create a backup sentence in case we are not able to extract the first sentence:
Now use the Java Streams API to create our summary, by:
- Removing empty paragraphs,
- Looking for the first paragraph with text in it,
- If there is such a paragraph, removing some things from the text we don’t need like footnote references and pronunciation examples,
- Then returning that text, or if there is no text use the backup sentence
The text of the first paragraph might still be quite long, so cut it off after the first period and return it. If we end up with nothing, return the backup sentence:
The full code with all the imports is on GitHub. I’ve also put in a main method with this code:
This prints out: “Twilio is a cloud communications platform as a service (CPaaS) company based in San Francisco, California.” Perfect!
What Next?
Using your new HTML parsing skills, you could:
- Convert the code above to respond to SMS for quick info on the go, using Twilio’s SMS API
- Write a new lightweight front-end for that awful intranet page which you have to use at work (you know the one)
- Check your own website for images without alt-text. The
altattribute on images is not mandatory in HTML, but is very helpful for accessibility.
Also, check out traintimes.org.uk - a highly accessible, fast and bookmarkable website for rail journeys in the UK. It works by screen-scraping the National Rail Enquiries website.
I do hope this was helpful for you. If you make anything with jsoup I’d love to hear about it at mgilliard@twilio.com or on Twitter I am @MaximumGilliard - I can’t wait to see what you build.

Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.