La guía máxima para el modelo de lenguaje GPT-3 de OpenAI
Time to read:
August 25, 2020
Redactado por
Revisado por
El Generative Pre-trained Transformer 3 (GPT-3, por sus siglas en inglés) es un nuevo modelo de lenguaje creado por OpenAIel cual es capaz de generar texto escrito de tal calidad que, a menudo, es difícil diferenciar del texto escrito por un humano.
En este artículo, exploraremos cómo trabajar con GPT-3 para una variedad de casos de uso, desde cómo usarlo como asistente de escritura hasta la creación de un bot de chat altamente sofisticado. Al final, sabrá cómo programar GPT-3 para chatear con usted acerca de sus temas favoritos. Este es un ejemplo de conversación breve que tuve con el bot sobre Python y el desarrollo de la Web.

¿Qué tan bueno es, en realidad?
¿Le resulta difícil creer que GPT-3 puede generar texto que sea prácticamente idéntico a lo que un humano puede producir? Lo dejaré juzgar por usted mismo con otro ejemplo.
Los dos párrafos siguientes fueron generados por el motor GPT-3 para describirse a sí mismo, después de que lo entrené simplemente mostrándole el primer párrafo del artículo sobre GPT-3 en Wikipedia. Tenga en cuenta que copio el texto siguiente de manera textual, esto es exactamente lo que GPT-3 produce sin edición.
GPT-3 es una red neuronal profunda que utiliza el mecanismo de atención para predecir la palabra siguiente en una oración. Se entrena con un corpus de más de 1000 millones de palabras y puede generar texto con una precisión en el nivel de los caracteres. La arquitectura de GPT-3 consta de dos componentes principales: un codificador y un decodificador. El codificador toma como entrada la palabra anterior en la oración y produce una representación de vectores de ella, que, luego, se pasa a través de un mecanismo de atención para producir la predicción de la siguiente palabra. El decodificador toma como entrada la palabra anterior y su representación de vectores, y produce una distribución de probabilidad de todas las palabras posibles dadas dichas entradas.
El rendimiento de GPT-3 está a la par con los mejores modelos de lenguaje para la generación de texto, lo que es significativamente mejor que los modelos de GPT anteriores. El modelo de Turning NLG de Microsoft puede generar texto con precisión en el nivel de los caracteres en un conjunto de pruebas con artículos de Wikipedia, pero requiere una enorme cantidad de datos de entrenamiento para hacerlo. OpenAI afirma que GPT-3 puede alcanzar este nivel de rendimiento sin ningún dato de capacitación adicional después de su período inicial de capacitación previa. Además, GPT-3 es capaz de generar oraciones y párrafos más largos que los modelos anteriores, como BERT de Google y el transformador de NLP de Stanford.
Impresionante, ¿verdad?
Lo que vamos a construir
Aprenderemos a trabajar con OpenAI Playground, una interfaz basada en la Web que, como su nombre en inglés lo sugiere (“playground” significa “área de juegos”), le permite jugar y crear prototipos de soluciones basadas en GPT-3.
No vamos a construir un solo proyecto específico. En cambio, implementaremos algunos prototipos diferentes para una gama de problemas diferentes.
Hacia el final, también veremos cómo transferir el trabajo que haya realizado en Playground a una aplicación Python independiente.
Requisitos previos
Para seguir los ejemplos que se muestran en este tutorial, el único requisito que necesita es tener una licencia de GPT-3 de OpenAI. En el momento en que escribo esto, OpenAI está ejecutando un programa beta para GPT-3, y puede solicitar una licencia beta directamente a ellos.
Si está interesado en escribir aplicaciones de GPT-3 independientes en Python, también deberá tener instalado Python 3.6 o una versión más reciente. Esto es completamente opcional; puede omitir la sección de Python si no está interesado.
El OpenAI Playground
Mencioné anteriormente que tenía que “entrenar” a GPT-3 para producir la salida de texto deseada. Esto es sorprendentemente fácil y se puede hacer en OpenAI Playground. A continuación, puede ver una captura de pantalla de la instancia de OpenAI Playground en la que generé el texto que se muestra arriba:
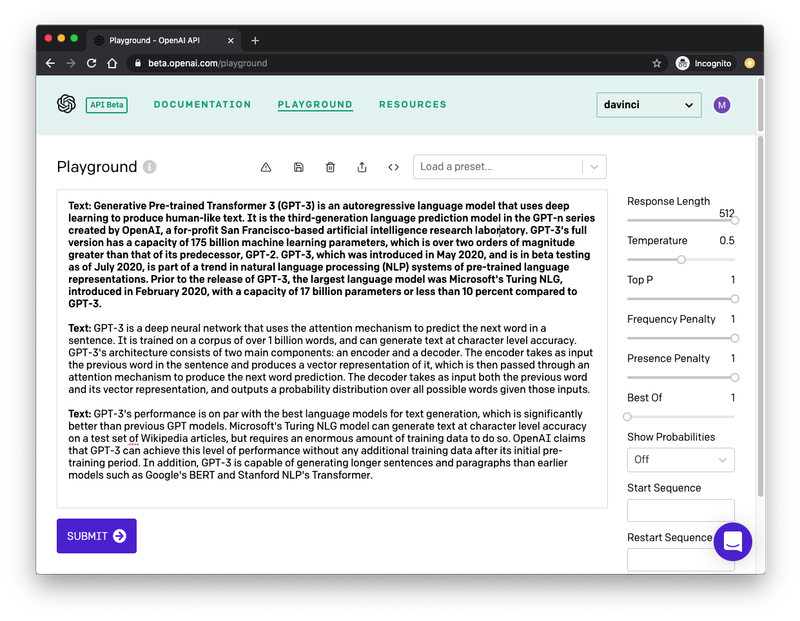
Permítanme explicarles los aspectos principales de esta interfaz.
La barra lateral de la derecha tiene algunas opciones para configurar el tipo de salida que esperamos que GPT-3 produzca. Más adelante en este artículo, veremos esta configuración en detalle.
El área grande de texto es donde interactúa con el motor de GPT-3. El primer párrafo, que aparece en negrita, es lo que GPT-3 recibirá como entrada. Inicié este párrafo con el prefijo Text: y seguí pegando el texto que copié desde un artículo de Wikipedia. Este es el aspecto clave del entrenamiento del motor: se le enseña qué tipo de texto desea que genere por medio de ejemplos. En muchos casos, un solo ejemplo es suficiente, pero puede brindarle más.
El segundo párrafo comienza con el mismo prefijo Text:, que también aparece en negrita. Esta segunda apariencia del prefijo es la última parte de la entrada. Le damos a GPT-3 un párrafo que tiene el prefijo y una muestra de texto, seguido de una línea que solo tiene el prefijo. Esto le da la clave que necesita para generar algo de texto para completar el segundo párrafo, de modo que coincida con el primero en cuanto al tono y el estilo.
Una vez que tenga el texto de entrenamiento y las opciones a su gusto, presione el botón “Submit” (Enviar) en la parte inferior, y GPT-3 analiza el texto de entrada y genera algunos más para que coincidan. Si presiona “Submit” (Enviar) de nuevo, GPT-3 se vuelve a ejecutar y produce otro fragmento de texto.
Todo lo que hice para generar los dos párrafos anteriores fue crear mi texto de entrada y presionar el botón “Submit” (Enviar) dos veces.
Trabajar con configuraciones predefinidas de GPT-3
Bien, ¡empecemos! Inicie sesión en OpenAI Playground para familiarizarse con la interfaz.
En la esquina superior derecha de la barra de navegación hay un menú desplegable para seleccionar uno de varios modelos de lenguaje:
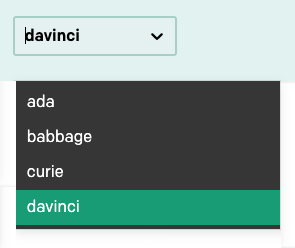
En este tutorial, solo usaremos el modelo davinci, que es el más avanzado en este momento, así que asegúrese de que es el que está seleccionado. Una vez que aprenda a trabajar con Playground, podrá cambiar a los otros modelos y experimentar también con ellos.
Sobre el área de texto hay otro menú desplegable con la etiqueta “Load a preset…” (Cargar una configuración predefinida…).
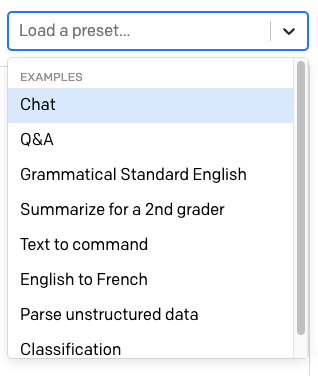
Aquí, OpenAI ofrece una serie de configuraciones predefinidas listas para usar para diferentes usos de GPT-3.
Seleccione la configuración predefinida “English to French” (Inglés a francés). Cuando elige una configuración predefinida, los contenidos del área de texto se actualizan con un texto de entrenamiento predefinido. También se actualizan las configuraciones en la barra lateral derecha.
En el caso de la plantilla “English to French” (Inglés a francés), el texto muestra algunas frases en inglés, cada una con su traducción al francés:

Como en mi propio ejemplo anterior, cada línea se inicia con un prefijo. Debido a que esta aplicación tiene líneas en inglés y líneas en francés, el prefijo es diferente para ayudar a GPT-3 a comprender el patrón.
Observe cómo, en la parte inferior del texto, hay un prefijo English: vacío. Aquí es donde podemos ingresar el texto que queremos que GPT-3 traduzca al francés. Siga adelante e ingrese una oración en inglés y, a continuación, presione el botón “Submit” (Enviar) para que GPT-3 genere la traducción al francés. Este es el ejemplo que utilicé:

La configuración predefinida agrega otra indicación English: vacía para que usted pueda escribir directamente la siguiente oración que desea traducir.
Todas las configuraciones predefinidas que ofrece OpenAI son fáciles de usar y se explican por sí solas, por lo que, en este punto, sería una buena idea que usted juegue con otras. En particular, recomiendo las configuraciones predefinidas de “Q&A” (Preguntas y respuestas) y “Summarize for a 2nd grader” (Resumen para alguien que asiste al segundo grado).
Creación de sus propias aplicaciones de GPT-3
Aunque las configuraciones predefinidas que ofrece OpenAI Playground son divertidas para jugar, seguramente usted tendrá sus propias ideas para utilizar el motor de GPT-3. En esta sección, analizaremos todas las opciones que se proporcionan en Playground para crear sus propias aplicaciones.
Crear su propia solución basada en GPT-3 implica escribir el texto de entrada para entrenar el motor y ajustar las configuraciones en la barra lateral según sus necesidades.
Para seguir los ejemplos de esta sección, asegúrese de restablecer Playground a su configuración predeterminada. Para ello, elimine todo el texto del área de texto y, si tiene una configuración predefinida seleccionada, haga clic en la “x” junto a su nombre para eliminarla.

Temperatura
Una de las configuraciones más importantes para controlar la salida del motor de GPT-3 es la temperatura. Esta configuración controla la aleatoriedad del texto generado. Un valor de 0 hace que el motor sea determinista, lo que significa que siempre generará la misma salida para una entrada de texto determinada. Un valor de 1 hace que el motor tome la mayor cantidad de riesgos y use mucha creatividad.
Me gusta comenzar a crear prototipos de una aplicación estableciendo la temperatura en 0, así que empecemos por hacerlo. El parámetro “Top P” (P máximo) que aparece debajo de la temperatura también tiene cierto control sobre la aleatoriedad de la respuesta, por lo que debe asegurarse de que el valor predeterminado sea 1. Deje todos los demás parámetros también en sus valores predeterminados.
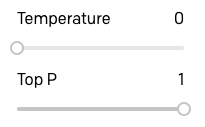
Con esta configuración, GPT-3 se comportará de una manera muy predecible, por lo que este es un buen punto de partida para probar las cosas.
Ahora puede escribir algo de texto y, luego, presionar “Submit” (Enviar) para ver cómo GPT-3 agrega un poco más. En el siguiente ejemplo, escribí el texto Python is (Python es) y dejé que GPT-3 complete la oración.

Esto es increíble, ¿verdad?
Antes de continuar, tenga en cuenta que a GPT-3 no les gustan las cadenas de entrada que terminan en un espacio, ya que esto provoca comportamientos extraños y, a veces, impredecibles. Es posible que usted tienda a agregar un espacio después de la última palabra de su entrada, así que tenga en cuenta que esto puede causar problemas. Playground le mostrará una advertencia si, por error, deja uno o más espacios al final de su entrada.
Ahora aumente la temperatura a 0,5. Elimine el texto generado anteriormente y deje solo Python is (Python es) y, luego, haga clic en “Submit” (Enviar). Ahora, GPT-3 se tomará más libertades cuando complete la oración. Esto es lo que obtuve:

Cuando lo pruebe, es probable que obtenga algo diferente. Y si lo prueba varias veces, obtendrá un resultado diferente cada vez que lo haga.
No dude en probar diferentes valores de temperatura para ver cómo GPT-3 se vuelve más o menos creativo en sus respuestas. Una vez que esté listo para continuar, vuelva a establecer la temperatura en 0 y vuelva a ejecutar la solicitud original de Python is.
Longitud de respuesta
Las compleciones de texto en la sección anterior eran muy buenas, pero probablemente notó que, a menudo, GPT-3 se detiene en medio de una oración. Para controlar la cantidad de texto que se genera, puede utilizar la configuración “Response Length” (Longitud de respuesta).
La configuración predeterminada para la longitud de respuesta es 64, lo que significa que GPT-3 agregará 64 tokens al texto, con un token definido como “una palabra o una marca de puntuación”.
Si la respuesta original a la entrada Python is con la temperatura establecida en 0 y con una longitud de 64 tokens, puede presionar el botón “Submit” (Enviar) una segunda vez para que GPT-3 agregue otro conjunto de 64 tokens al final.

Pero, por supuesto, una vez más, nos quedamos con una oración incompleta al final. Un truco simple que puede usar es fijar la longitud en un valor mayor que el que necesita y, luego, descartar la parte incompleta del final. Más adelante, veremos cómo enseñarle a GPT-3 que se detenga en el lugar correcto.
Prefijos
Ha visto que, cuando generé los dos párrafos de demostración cerca del comienzo de este artículo, arreglé cada párrafo con anterioridad con un prefijo Text:. También ha visto que la configuración predefinida de la traducción del inglés al francés usó los prefijos English: y French: en las líneas correspondientes.
Usar un prefijo corto para cada línea de texto es una herramienta muy útil para ayudar a GPT-3 a comprender mejor qué respuesta se espera. Considere una aplicación simple en la que queremos que GPT-3 genere nombres de variables metasintácticas que podamos usar cuando escribimos el código. Estas son variables de marcador de posición, como foo y bar, que suelen utilizarse en ejemplos de codificación.
Podemos entrenar a GPT-3 mostrándole una de estas variables y permitiéndole generar más. Después del ejemplo anterior, podemos utilizar foo como entrada, Pero esta vez, presionaremos Intro y moveremos el cursor a una nueva línea para indicar a GPT-3 que queremos la respuesta en la siguiente línea. Lamentablemente, esto no funciona bien, ya que GPT-3 no “consigue” lo que queremos:

El problema aquí es que no le estamos diciendo claramente a GPT-3 que lo que queremos es tener más líneas como la que ingresamos.
Intentemos agregar un prefijo para ver cómo mejora nuestro entrenamiento. Lo que vamos a hacer es utilizar var: foo como nuestra entrada, pero también forzaremos a GPT-3 a seguir nuestro patrón escribiendo var: en la segunda línea. Debido a que la segunda línea está incompleta ahora en comparación con la primera, estamos aclarando que queremos que se agregue “algo como un foo”.
Y esto funciona mucho mejor:

Secuencia de detención
En todos los ejemplos que hemos estado probando, tenemos el problema de que GPT-3 genera un flujo de texto hasta la longitud solicitada y, luego, se detiene, a menudo, en la mitad de una oración. La opción “Stop Sequences” (Secuencias de detención), que puede encontrar en la parte inferior de la barra lateral derecha, le permite definir una o más secuencias que, cuando se generan, fuerzan a GPT-3 a detenerse.
Con el ejemplo de la sección anterior, supongamos que nos gustaría tener solo una variable nueva cada vez que invoquemos el motor de GPT-3. Dado que estamos poniendo un prefijo en cada línea con var: y estamos preparando el motor con el prefijo solo en la última línea de la entrada, podemos utilizar este mismo prefijo como secuencia de detención.
Busque el campo “Stop Sequences” (Secuencias de detención) en la barra lateral e ingrese var: seguido de Tab.
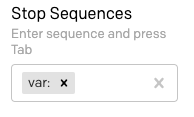
Ahora, restablezca el texto de entrada para que var: foo esté en la primera línea y solo var: en la segunda línea, y haga clic en "Submit" (Enviar). Ahora, el resultado es una sola variable:

Escriba otra var: en la tercera línea del texto de entrada, envíela de nuevo, y obtendrá una más.

Texto de inicio
Estamos progresando para que GPT-3 dé las respuestas que esperamos, pero nuestra próxima molestia es que cada vez que queremos solicitar una respuesta, debemos escribir de forma manual el prefijo para la línea que GPT-3 debe completar.
La opción “Inject Start Text” (Inyectar texto de inicio) en la configuración le indica a Playground qué texto se anexará de manera automática a la entrada antes de enviar una solicitud a GPT-3. Coloque el cursor en este campo y escriba “var:”.

Ahora restablezca el texto a una sola línea de texto que tenga var: foo. Presione Intro para que el cursor se ubique en la segunda línea y presione “Submit” (Enviar) para ver la siguiente variable. Cada vez que lo envíe, obtendrá uno nuevo, con los prefijos insertados automáticamente.

Uso de varios prefijos
El generador de nombre de variables que hemos utilizado en las últimas secciones sigue el enfoque simple de mostrarle a GPT-3 un texto de muestra para obtener más texto parecido. He utilizado este mismo método para generar los dos párrafos de texto que he presentado al comienzo de este artículo.
Otro método de interacción con GPT-3 es hacer que aplique algún tipo de análisis y transformación al texto de entrada para producir la respuesta. Hasta ahora, solo hemos visto la configuración predefinida de la traducción del inglés al francés como ejemplo de este tipo de interacción. Otras posibilidades son los bots de chat de preguntas y respuestas, que hacen que GPT-3 corrija errores gramaticales en el texto de entrada, incluso los más esotéricos, como convertir las instrucciones de diseño proporcionadas en inglés a HTML.
La característica interesante de estos proyectos es que hay un diálogo entre el usuario y GPT-3, y esto requiere el uso de dos prefijos para marcar por separado las líneas que pertenecen al usuario y a GPT-3.
Para demostrar este tipo de estilo de proyecto, vamos a crear un bot ELI5 (Explain Like I’m 5; explique como si tuviese cinco años) que aceptará un concepto complejo del usuario y devolverá una explicación de él con palabras simples que un niño de cinco años puede entender.
Restablezca Playground al estado inicial predeterminado haciendo clic en el ícono de la papelera.

Para crear el bot ELI5, vamos a mostrar GPT-3 un ejemplo de interacción. La línea que muestra lo que queremos que se explique usará el prefijo thing: y la línea con la explicación va a utilizar eli5:. A continuación, se muestra cómo podemos entrenar a GPT-3 en esta tarea mediante el uso de “micrófono” como ejemplo de nuestro entrenamiento:

Fácil, ¿verdad? Debemos asegurarnos de usar palabras simples en la respuesta que utilizaremos para el entrenamiento, porque queremos que GPT-3 genere otras respuestas de un estilo similar.
La opción “Inject Start Text” (Inyectar texto de inicio) se puede configurar en [enter]eli5:, de modo que Playground agregue de forma automática el prefijo para la línea de GPT-3.

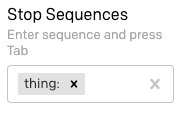
También debemos establecer una secuencia de detención, de modo que GPT-3 sepa cuándo detenerse. Podemos usar thing: aquí, para asegurarnos de que GPT-3 comprenda que no es necesario generar las líneas “Thing” (Cosa). Recuerde que, en este campo, debe presionar la tecla Tab para completar el ingreso de la secuencia de detención.
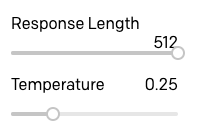
Establecí la longitud de la respuesta en un máximo de 512, ya que la secuencia de detención es cómo hacemos que GPT-3 se detenga. También he movido el deslizador de temperatura a 0,25, de modo que las respuestas no se adornen mucho ni sean demasiado aleatorias, pero esta es un área donde puede jugar con diferentes configuraciones y encontrar lo que funciona mejor para usted.
¿Está listo para probar nuestro bot de ELI5? Este es el primer intento:

Está bastante bien, ¿verdad? Debido a que la temperatura está fijada en un valor distinto de cero, las respuestas que obtenga usted pueden diferir ligeramente de las mías.
Reiniciar texto
Si comenzó a jugar con el bot de ELI5 de la sección anterior, es posible que haya notado que debe volver a escribir el prefijo thing: vez que desea hacer una nueva pregunta al bot.
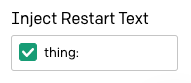
La opción “Inject Restart Text” (Inyectar texto de reinicio) en la barra lateral se puede utilizar para insertar de manera automática un texto después de la respuesta de GPT-3, de modo que podamos usarlo para escribir automáticamente el siguiente prefijo. Ingresé el prefijo thing: seguido de un espacio aquí.
Ahora es mucho más fácil jugar e interactuar con GPT-3 y hacer que nos explique las cosas.

La opción “Top P”
El argumento “Top P” (P máximo) es una forma alternativa de controlar la aleatoriedad y la creatividad del texto generado por GPT-3. La documentación de OpenAI recomienda que se utilice solo una función de entre Temperature (Temperatura) y Top P (P máximo), de modo que, cuando utilice una de ellas, asegúrese de que la otra esté configurada en 1.
Quería experimentar y ver cómo variaban las respuestas GPT-3 cuando usaba Top P (P máximo) en lugar de Temperature (Temperatura), por lo que elevé la temperatura a 1 y bajé el P máximo a 0,25:
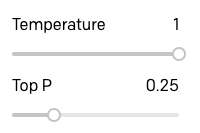
Luego, repetí la sesión mencionada.

Como pueden ver, no hay una gran diferencia, pero creo que la calidad de las respuestas es un poco menor. Considere la respuesta al viaje en el tiempo, que es una explicación realmente deficiente, y también la forma en que GPT-3 repite el concepto de buscar información en dos de las respuestas.
Para ver si podía mejorar estas respuestas un poco, subí la opción Top P (P máximo) hasta 0,5:
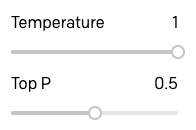
Las respuestas definitivamente son mejores:

Para completar mi investigación sobre Temperature (Temperatura) y Top P (P máximo), probé las mismas consultas con un valor de Temperature (Temperatura) de 0,5:
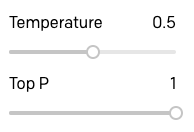
Estos son los resultados:

Claramente, para este tipo de aplicación, una temperatura de 0,5 se pasa un poco, y GPT-3 se vuelve más vago e informal en sus respuestas.
Después de jugar con varios proyectos y probar Temperature (Temperatura) y Top P (P máximo), mi conclusión es que Top P (P máximo) ofrece un mejor control para las aplicaciones en las que se espera que GPT-3 genere texto con exactitud y corrección, mientras que Temperature (Temperatura) funciona mejor para las aplicaciones en las que se buscan respuestas originales, creativas o incluso divertidas.
Para el bot de ELI5, decidí que utilizar la opción Top P (P máximo) en 0,5, ya que es lo que ofrece las mejores respuestas.
Configuraciones predefinidas personalizadas
Hasta ahora, ya hemos jugado con la mayoría de las opciones de configuración y, además, tenemos una primera aplicación interesante, nuestro bot de ELI5.
Antes de continuar para crear otro proyecto, debe guardar el bot de ELI5, junto con las configuraciones que encontró para trabajar de la mejor forma.
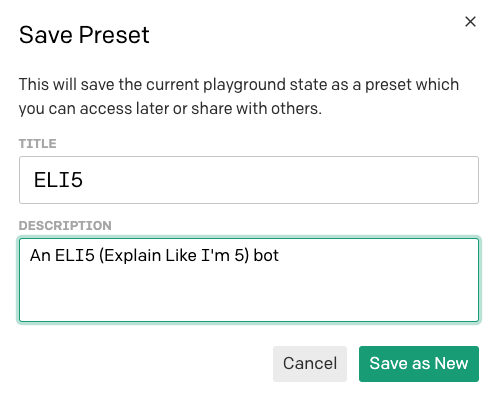
Comience por restablecer el texto para incluir solo la parte del entrenamiento con la definición de un micrófono, además del prefijo thing: en la tercera línea. Una vez que se restablezca el texto al entrenamiento inicial, utilice el ícono de disquete para guardar el proyecto como una configuración predefinida:

Para cada configuración predefinida guardada, puede proporcionar un nombre y una descripción.
Ahora, las configuraciones predefinidas aparecen en el menú desplegable de configuraciones predefinidas y las puede reutilizar con solo seleccionarlas.
Si desea compartir esta configuración predefinida con otras personas, puede utilizar el botón Share (Compartir):

Para compartir una configuración predefinida, se le ofrecerá una URL que puede pasarle a sus amigos:
Tenga en cuenta que cualquier persona que reciba esta URL debe tener acceso a OpenAI Playground para poder usar su configuración predefinida.
Sanciones por frecuencia y presencia
Echemos un vistazo a dos opciones más que aún no hemos explorado. Los controles deslizantes de “Frequency Penalty” (Sanción por frecuencia) and “Presence Penalty” (Sanción por presencia) le permiten controlar el nivel de repetición que se le permite usar a GPT-3 en sus respuestas.

La sanción por frecuencia funciona reduciendo las posibilidades de que se seleccione de nuevo una palabra a medida que ya se ha utilizado esa palabra más veces. La sanción por presencia no considera la frecuencia con la que se ha utilizado una palabra, sino solo si existe una palabra en el texto.
La diferencia entre estas dos opciones es sutil, pero se puede pensar en la Frequency Penalty (Sanción por frecuencia) como una forma de evitar repeticiones de palabras y la Presence Penalty (Sanción por presencia) como una forma de evitar repeticiones de temas.
No he tenido mucha suerte en entender cómo funcionan estas dos opciones. En general, descubrí que con estas opciones configuradas en los valores predeterminados 0, es probable que GPT-3 no repita debido a la aleatorización que le dan los parámetros de Temperature (Temperatura) o Top P (P máximo). En las pocas situaciones en las que encontré alguna repetición, solo moví ambos deslizadores hasta 1, y eso lo arregló.
Este es un ejemplo en el que le di a GPT-3 una descripción del lenguaje de programación Python (que realmente tomé de su propia respuesta) y, luego, le pedí que me brindara una descripción del lenguaje de JavaScript. Con las opciones de Temperature (Temperatura), Frequency Penalty (Sanciones por frecuencia) y Presence Penalties (Sanciones por presencia) establecidas en cero, esto es lo que obtuve:

Puede ver que esta descripción no es realmente genial. GPT-3 nos dice que JavaScript es un lenguaje de script y que está basado en prototipos de dos veces cada uno. Con los dos parámetros de penalización por repetición configurados en 1, obtengo una definición mucho mejor:

La opción “Best Of”
La opción “Best Of” (Lo mejor) se puede utilizar para que GPT-3 genere varias respuestas a una consulta. Luego, Playground selecciona la mejor y la muestra.

No he encontrado un buen uso de esta opción, porque no me resulta claro cómo se toma una decisión sobre cuál de varias opciones es la mejor. Además, cuando se establece esta opción en cualquier valor que no sea 1, Playground deja de mostrar las respuestas a medida que se generan en tiempo real, porque necesita recibir la lista completa de respuestas para elegir la mejor.
Mostrar las probabilidades de palabras
La última opción en la barra lateral de configuración es “Show Probabilities” (Mostrar probabilidades), que es una opción de depuración que le permite ver por qué se seleccionaron determinados tokens.
Vuelva a cargar la configuración predefinida de ELI5. Establezca la opción “Show Probabilities” (Mostrar probabilidades) en “Most Likely” (Más probable) y, luego, vuelva a ejecutar el inicio con la palabra “book” (reservar). El texto resultante tendrá un color:
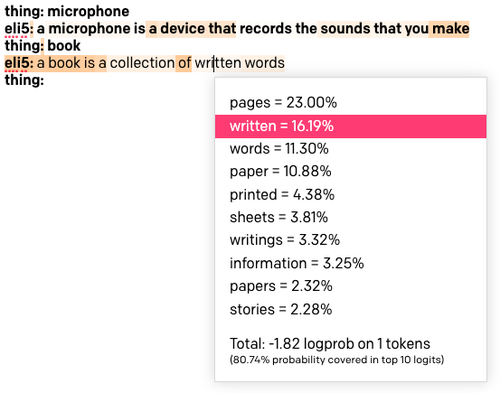
Mientras más oscuro sea el fondo de una palabra, más probable es que se elija la palabra. Si hace clic en una palabra, verá una lista de todas las palabras que se consideraron en esa posición del texto. Como pueden ver arriba, hice clic en la palabra “written” (escrito), que tiene un color bastante claro, y resulta que era la segunda elección favorita después de la palabra “pages” (páginas). Se eligió esta palabra en lugar de la favorita debido a la aleatorización de la configuración de Top P (P máximo) o Temperature (Temperatura).
Cuando se configure esta opción como “Least likely” (Menos probable), la coloración funciona al revés, con los fondos más oscuros asignados a las palabras que se seleccionaron a pesar de que no son una opción probable.
Si configura la opción “Full Spectrum” (Espectro completo), verá tanto las palabras menos probables como las más probables coloreadas, con tonos verdes para las más probables y tonos rojos para las menos probables.

Implementación de un bot de chat
Dada la gran cantidad de texto que se ha utilizado para crear el modelo de lenguaje GPT-3, es posible crear bots altamente avanzados que pueden ofrecer una conversación aparentemente inteligente acerca de muchos temas diferentes.
Como último proyecto, vamos a crear un bot de chat de formato libre que puede utilizar para chatear con GPT-3 acerca de cualquier cosa que desee. A continuación, se muestra una sesión de chat de ejemplo sobre Python y el desarrollo web que tenía con este bot:

En la captura de pantalla, puede ver que el entrenamiento es solo las dos primeras líneas, en las que ingresé un saludo entre un ser humano y la IA. Las palabras que usé aquí son informales, porque quería que el bot fuera divertido e interesante para chatear. Si desea crear un bot de chat más “serio”, tendrá que adaptar estas líneas según corresponda.
Restablezca los valores predeterminados de Playground y, a continuación, ingrese las dos primeras líneas que se mencionan arriba (o las que sean similares que usted desee). En la tercera línea, agregue prefijo Human: y déjela lista para que ingresemos texto.
En términos de configuración, esto es lo que he utilizado:
- Response Length (Longitud de respuesta): 512
- Temperature (Temperatura): 0,9
- Top P (P máximo): 1
- Frequency Penalty (Sanciones por frecuencia): 1
- Presence Penalty (Sanciones por presencia): 1
- Best Of (Lo mejor de): 1
- Show Probabilities (Mostrar probabilidades): Off (Desactivado)
- Inject Start Text (Inyectar texto de inicio):
↵AI: - Inject Restart Text (Inyectar texto de reinicio):
↵: - Stop Sequences (Secuencias de detención):
↵human:y↵
La mayoría de las configuraciones anteriores deben ser claras en función de los ejemplos de la sección anterior, pero esta es la primera vez que he utilizado más de una secuencia de detención. Cuando se utilizan altos niveles de aleatorización, ya sea con Temperature (Temperatura) o Top P (P máximo), descubrí que GPT-3 a veces responde mediante la generación de varios párrafos. Para evitar que el chat obtenga respuestas de varios párrafos muy grandes e inconexos, agregué un carácter de nueva línea como una segunda secuencia de detención, de modo que cada vez que GPT-3 intente pasar a un nuevo párrafo la secuencia de detención provoque que la respuesta termine ahí.
Intente chatear con el bot acerca de cualquier tema que desee, pero tenga en cuenta que, esta vez, el modelo de lenguaje no sabe sobre eventos actuales porque su configuración de entrenamiento no incluye ningún dato a partir de octubre del 2019. Por ejemplo, si bien he notado que el bot tiene mucho conocimiento sobre los coronavirus en general, no conoce nada de la pandemia de la COVID-19.
Una vez que haya llegado a la configuración que más le gusta, restablezca el texto al entrenamiento inicial y guarde el chat como una configuración predefinida. En la siguiente sección, vamos a trasladar este chat a Python.
Migración desde Playground a Python
OpenAI ha puesto a disposición un paquete de Python para que interactúe con GPT-3, por lo que la tarea de trasladar una aplicación desde Playground no es complicada.
Para seguir esta parte del tutorial, debe tener instalado Python 3.6 o una versión más reciente en su computadora. Comencemos por crear un directorio del proyecto en el que crearemos nuestro proyecto de Python:
Para este proyecto, utilizaremos las prácticas recomendadas de Python, de modo que crearemos un entorno virtual en el que vamos a instalar el paquete de OpenAI. Si utiliza un sistema operativo Unix o Mac, introduzca los siguientes comandos:
Los que siguen el tutorial en Windows, ingresen los siguientes comandos en una ventana del símbolo del sistema:
Envío de una consulta a GPT-3
El código que se necesita para enviar una consulta al motor de GPT-3 se puede obtener directamente desde Playground. Seleccione la configuración predefinida para el chat que guardó anteriormente (o su configuración predefinida favorita) y, luego, haga clic en el botón “Export Code” (Exportar código) en la barra de herramientas:

Ahora verá una ventana emergente que muestra un fragmento de Python que puede copiar en el portapapeles. Este es el código que se generó para la configuración predefinida para mi chat:
Si bien esto es realmente muy útil y puede ayudarnos mucho, hay un par de cosas que hay que tener en cuenta.
Las opciones Inject Start Text” (Inyectar texto de inicio) e Inject Restart Text” (Inyectar texto de reinicio) se definen como las variables start_sequence y restart_sequence, pero no se utilizan en la llamada de API real. Esto se debe a que estas opciones de Playground no existen en la API de OpenAI y las implementa directamente la página web de Playground, por lo que tendremos que replicar su funcionalidad directamente en Python.
Además, hemos visto cómo podemos ejecutar varias interacciones con GPT-3 de manera continua, donde cada consulta nueva incluye las indicaciones y las respuestas de las anteriores. Esta acumulación de contenido también se implementa mediante Playground y debe replicarse con la lógica de Python.
Con el fragmento anterior del código Python como base, he creado una función gpt3() que imita el comportamiento de Playground. Copie el siguiente código en un archivo con el nombre gpt3.py:
En primer lugar, en este código estoy importando la clave de OpenAI desde una variable de entorno, ya que es más seguro que agregar su clave directamente en el código como sugiere OpenAI.
La función gpt3() toma todos los argumentos que hemos visto antes que definen cómo ejecutar una consulta a GPT-3. El único argumento requerido es prompt, que es el texto real de la consulta. Para todos los demás argumentos, he agregado valores predeterminados que coinciden con Playground.
Dentro de la función, ejecuto una solicitud a GPT-3 mediante un código similar al fragmento sugerido. Para la indicación, agregué el texto de inicio aprobado para duplicar la comodidad de no tener que agregarlo de forma manual como lo obtenemos de Playground.
La respuesta de GPT-3 es un objeto que tiene la siguiente estructura:
A partir de estos datos, solo nos interesa el texto real de la respuesta, así que utilicé la expresión response.choices[0].text para recuperarla. El motivo por el que choices aparece como una lista es que existe una opción en la API de OpenAI para solicitar varias respuestas a una consulta (la opción “Best Of” “Lo mejor de” en Playground). No estamos utilizando esa opción, por lo que la lista choices siempre tendrá una sola entrada para nosotros.
Después de colocar el texto de la respuesta en la variable answer, creo una nueva indicación que incluye el aviso original concatenado con la respuesta y el texto de reinicio, exactamente cómo lo hace Playground. El propósito de generar una nueva indicación es devolverlo al agente de llamada para que se pueda usar en una llamada de seguimiento. La función gpt3() devuelve la respuesta independiente y el nuevo mensaje.
Tenga en cuenta que no he utilizado todas las funciones de la API en este código. La Documentación de la API de OpenAI es la mejor referencia para obtener más información sobre todas las funciones disponibles, así que asegúrese de echarle un vistazo en caso de que encuentre algo útil para su proyecto.
Creación de una función de chat
Con la ayuda de la función gpt3() de la sección anterior, ahora podemos crear una aplicación de chat. Coloque el siguiente código en un archivo llamado chat.py:
La única dependencia utilizada por esta aplicación es la función gpt3() de la sección anterior, que se importa en la parte superior.
La función chat() crea una variable prompt a la que se asigna al intercambio realizado que entrena a GPT-3 en relación con la estructura del chat. Luego, ingresamos en el bucle de chat, el cual comienza solicitando al usuario que escriba su mensaje mediante la función input() de Python. El mensaje del usuario se adjunta a la indicación y, a continuación, se llama a gpt3() con la indicación y los ajustes de configuración deseados. La función gpt3() da una respuesta y la indicación actualizada. Mostramos al usuario la respuesta y, a continuación, en la siguiente repetición del bucle, repetiremos este ciclo, mediante un aviso actualizado que incluye la última interacción.
El chat finaliza cuando el usuario presiona Ctrl-C para finalizar el script de Python.
Ejecución del bot de Python
Para probar esta aplicación, primero debe establecer la variable de entorno OPENAI_KEY. Si utiliza Mac OS X o Linux, haga lo siguiente:
En el símbolo del sistema de Windows, puede hacerlo de la siguiente manera:
Puede encontrar su clave OpenAI en la página de Developer Quickstart (Inicio rápido de desarrollador). De las dos claves que se muestran en esta página, utilice la que está etiquetada como “Secret” (Secreto).
Una vez que haya configurado la clave en su entorno, inicie el chat escribiendo python chat.py y comience a chatear con el bot. A continuación, se muestra un ejemplo de interacción con él:
Trabajo con otros lenguajes además de Python
Puede adaptar el ejemplo de Python a otros lenguajes, pero es posible que no tenga una biblioteca de OpenAI disponible. Esto no es un problema, ya que la API de OpenAI es una API de HTTP bastante estándar a la que puede acceder a través de solicitudes HTTP sin procesar.
Para aprender a enviar una solicitud de una configuración predefinida de Playground, puede utilizar el mismo botón “Export Code” (Exportar código), pero esta vez seleccione la pestaña “cURL” para ver la solicitud de HTTP.
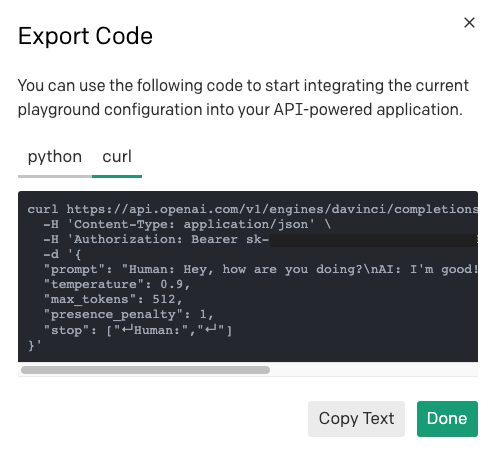
Puede utilizar el comando cURL para comprender qué debe ser la URL, los encabezados y la carga útil y, luego, traducirlo al cliente de HTTP elegido en su lenguaje de programación.
Conclusión
¡Este fue un largo viaje! Espero que ahora tenga una buena comprensión de la API de OpenAI y de cómo trabajar con GPT-3.
¿Desea aprender a utilizar GPT-3 con Twilio y Python? He escrito un tutorial del bot de chat de SMS de GPT-3, y mi colega, Sam Agnew, escribió también un divertido tutorial de GPT-3 de fan fiction de Dragon Ball.
¡Me encantaría ver las increíbles aplicaciones que construye con GPT-3!
Publicaciones relacionadas
-
 Los 11 mejores proveedores de servicios de email marketing en 2026Nathalia Velez Ryan Jesse Sumrak
Los 11 mejores proveedores de servicios de email marketing en 2026Nathalia Velez Ryan Jesse Sumrak -
 Más de 19 consejos para evitar que tus correos electrónicos vayan a la carpeta de correo no deseado en 2026Jesse Sumrak
Más de 19 consejos para evitar que tus correos electrónicos vayan a la carpeta de correo no deseado en 2026Jesse Sumrak -
 Construya una cabina de fotos con un Arduino Yun, una Cámara Web y DropboxGreg Baugues
Construya una cabina de fotos con un Arduino Yun, una Cámara Web y DropboxGreg Baugues
Recursos relacionados
Twilio Docs
Desde API hasta SDK y aplicaciones de muestra
Documentación de referencia de API, SDK, bibliotecas auxiliares, inicios rápidos y tutoriales para su idioma y plataforma.
Centro de Recursos
Los últimos libros electrónicos, informes de la industria y seminarios web
Aprenda de los expertos en participación del cliente para mejorar su propia comunicación.
Ahoy
Centro de la comunidad de desarrolladores de Twilio
Mejores prácticas, ejemplos de códigos e inspiración para crear comunicaciones y experiencias de participación digital.