How to Add Live Transcriptions to Video Calls with OpenAI’s Whisper

Time to read:
September 25, 2023
Written by
Reviewed by
To build this application the Twilio Programmable Video JavaScript SDK was used to create a video room where room participants can join, communicate, and share transcripts.
To add live transcriptions to this web application you will use an enhanced version of the MediaRecorder API to record the room participants' microphones in a 6-second interval. You will use the Tranformers.js package alongside a Whisper model to transcribe the audio sent by the room participants. You will also use the DataTrack API to share the transcripts among the room participants.
The Twilio Programmable Video JavaScript SDK is a set of utilities that enables you to seamlessly integrate real-time video and voice functionalities into your web or mobile applications.
The MediaRecorder API is a JavaScript interface that provides a standardized way to record media streams in web applications. It allows you to capture audio and video from various sources, such as microphones and webcams, and save the recorded data in a specified format.
Transformers.js is a package intended to be functionally equal to Hugging Face's Python package, meaning that the same pre-trained models may be run using a very similar API.
Whisper is a speech recognition model that can be used for a variety of purposes. It is a multitasking model that can do multilingual voice recognition, speech translation, and language identification.
By the end of this tutorial you will have an application that looks similar to the following:
Tutorial Requirements
To follow this tutorial you will need the following:
- A free Twilio account
- A basic understanding of how to use Twilio and Javascript to build a video web app;
- Node.js v12+, NPM, and Git installed;
- A graphics card (this is optional, Whisper will still run with just a CPU but it will be slower).
Getting the boilerplate code
In this section, you will clone a repository containing the boilerplate code needed to build the video call web application.
Open a terminal window and navigate to a suitable location for your project. Run the following commands to clone the repository containing the boilerplate code and navigate to the boilerplate directory:
This boilerplate code includes an Express.js project that serves the client application and generates the necessary access tokens for utilizing the Twilio Video API within the client application.
This Node.js application comes with the following packages:
dotenv: is a package that allows you to load environment variables from a .env file without additional dependencies.express: is a lightweight Node.js web application framework that offers a wide range of features for creating web and mobile apps. You will use the package to create the application server.multeris a Node.js middleware designed to managemultipart/form-data, it is primarily used for file uploads. You will use this module to receive and store the audio recordings sent by each room participant.node-dev: is a Node.js module used in development to automatically restart Node.js applications when code changes are detected, streamlining the development process.transformers.js: is a Javascript library designed to closely mirror the functionality of Hugging Face's transformers Python library, enabling you to utilize the same pre-trained models through a highly similar API. You will use this library to run the Whisper Tiny model on the server to transcribe the audio recordings.twilio: is a package that allows you to interact with the Twilio API.uuid: is a package that is utilized to generate universally unique Identifiers, It will be used to create a unique identity when creating a Twilio access token.wavefile: is a package that allows you to create, read, write, and process Wav files. It will be used to pre-process the audio recordings before transcribing them.
Use the following command to install the packages mentioned above:
Understanding the directories and files
Excluding the package.json and .gitignore files the project root’s directory has two directories named public and uploads and a file named server.js.
The public directory is where the client application static assets files are stored, it contains three files named index.html, styles.css, and index.js.
The index.html file creates the user interface for the application, including a div to display the main webcam feed, a container below this div to show the transcriptions, buttons to control the call, and a sidebar to display all webcam feeds. The file also links to the styles.css stylesheet and includes scripts for the Twilio Video SDK, Bootstrap, and a file named index.js.
The styles.css file and Bootstrap are used to style the application.
The index.js file contains the code that creates the Local Audio, Video, and Data tracks and then uses these tracks to create a video room.
The uploads directory is where the audio recordings will be stored. It initially contains a sample audio recording file named audio.wav which will be used to test the speech-to-text functionality.
The server.js file sets up an Express.js server that serves static assets from the public directory and handles video call room creation and access token generation using the Twilio Video API. Clients can request to join a room by providing a room name, and the server ensures the room exists and provides them with the necessary access token for the video call.
Collecting and storing your Twilio credentials
Create a new file named .env in your project root directory. This file is where you will store your Twilio account credentials that will be needed to create access tokens for the Twilio Video API. In total, you will need to collect and store three twilio credentials.
The first credential required is the Account SID, which is located in the Twilio Console. This credential should be stored in the .env file once obtained:
The second and third required credentials are an API Key SID and API Key Secret, which can be obtained by following this guide. After obtaining both credentials, copy and store them in the .env file:
Go back to your terminal and run the following command to start the application:
Open two tabs on your preferred browser and navigate to http://localhost:3000/ URL and you should see a web page similar to the following:
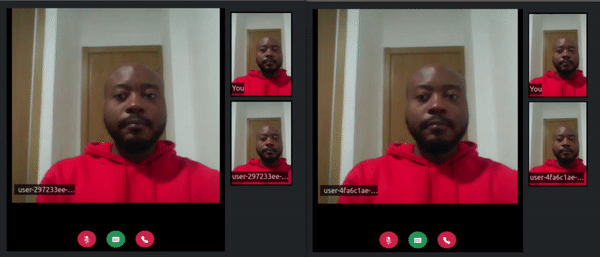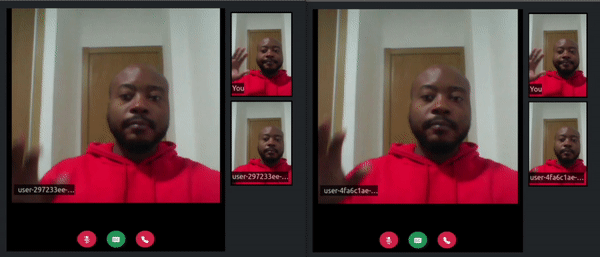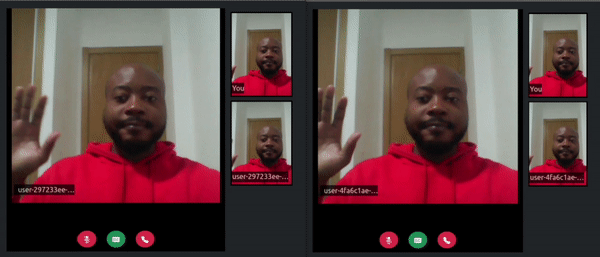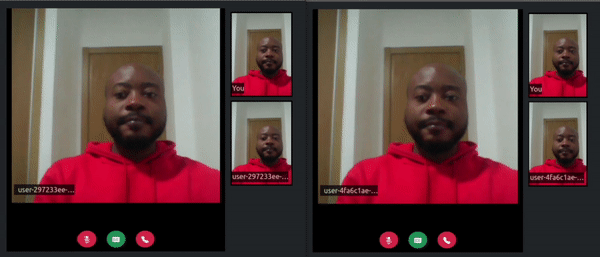
Adding whisper to your application
In this section, you will learn how to use the Transformers.js package alongside a Whisper model to transcribe audio files.
The Transformers.js package is similar to its Python counterpart and relies on the pipeline API. Pipelines offer a user-friendly and high-level API for executing machine learning models.
Pipelines bundle a pre-trained model along with input preprocessing and output post-processing, creating the most straightforward method for utilizing models within the library.
Create a file named whisper.js in your project root directory and add the following code to it:
First, the code imports the fs and wavefile modules and declares a variable named transcriber.
Next, the code declares a function named initialize(). This function utilizes the import() function to load the pipeline function from the transformers.js ES module.
The initialize() function then initializes the transcriber variable by creating a pipeline for automatic speech recognition using the Xenova/whisper-tiny.en model.
Add the following code below the initialize() function:
The code above defines a function named getAudioData() which takes a file path as a parameter. This function is responsible for reading and preprocessing audio data from the given file.
The code reads the audio file at the given file path synchronously using fs.readFileSync() and then converts the file's contents into a buffer.
The buffer is then processed using the wavefile module. The audio is converted to a 32-bit floating point format using .toBitDepth('32f') method and resampled to a rate of 16000 samples per second using .toSampleRate(16000) method.
The code uses conditional logic to check if the audio data contains multiple channels and merge them into a single channel if that is the case. This is done by averaging the values of the channels and scaling them with a factor. The final audio data is stored in the audioData variable.
Add the following code below the getAudioData() function:
The code above defines a function named deleteFile() that takes a file path as a parameter and deletes the audio file located at that path.
Add the following code below the deleteFile() function:
The code defines a function named transcribe() that takes a file path as a parameter and transcribes the speech in the audio file located at that path.
The code inside this function calls the getAudioData() function and passes a file path as an argument to retrieve the preprocessed audio data.
Next, it uses the previously initialized transcriber pipeline to transcribe the audio data into text and stores the value returned in a variable named transcript.
Lastly, it returns the transcript variable.
Add the following code below the transcribe() function:
Here the code defines and calls a function named firstRun().
The code inside this function initializes the transcriber using the initialize() function.
It then transcribes the speech in the audio file named audio.wav located in the uploads directory using the transcribe() function and logs the resulting transcript.
You will use this function mainly to have the pipeline download and cache the Xenova/whisper-tiny.en model before using this script with your server application because when running for the first time, the pipeline can take a while to download and cache the pre-trained model. Subsequent calls will be much faster.
Go back to your terminal and use the following command to run this script:
Wait a few seconds and you should get an output similar to this:
Run the command above as many times as you wish and watch how subsequent calls are much faster since the model has already been downloaded and cached.
Go back to your whisper.js file and uncomment the line where the code calls the deleteFile() function located inside the transcribe() function.
Next, comment out the firstRun() function call, and export the initialize() and transcribe() functions by adding the code below the firstRun() function:
Open your server.js file and add the following code to the bottom of the import statements section:
Here the code imports the initialize() and the transcribe() functions and calls the initialize() function to initialize the transformers.js pipeline.
Add the following code below the /join-room route:
The code above defines a route named /uploadAudio. This route uses the multer module to handle audio file uploads and the transcribe() function to transcribe the audio file. These audio files are microphone recordings of the room participants who have enabled the transcription functionality.
The code first uses conditional logic to check if a file was uploaded in the request received.
If a file wasn’t uploaded a response stating the request failed is sent back to the client.
If a file was uploaded the code calls the transcribe() function from the whisper.js module to transcribe the uploaded audio file and then sends the transcription result in a response.
Adding live transcriptions to the application
In this section, first, you will use the MediaRecorder API to allow the room participants to record their microphones. Next, you will upload the recordings to the server where they will be transcribed. Lastly, you will use the DataTrack API to share the transcript returned among the room participants and then you display it below the main webcam feed.
Open up the index.html file, go to the bottom of the body tag and add a script named transcription.js of type module to it:
Create a file named transcription.js within the public folder and add the following code to it:
The code first uses the Skypack CDN to import the extendable-media-recorder and extendable-media-recorder-wav-encoder packages. These packages will allow the application to use the MediaRecorder API to record the room participant’s microphones in the WAV format which is what the whisper module you created earlier expects to receive.
Next, it defines 3 variables named isMuted, isTranscribing, mediaRecorder which will be used to keep track of whether the room participant microphone is muted or not, whether the transcription functionality is enabled or not, and store the MediaRecorder instance respectively.
Finally, it defines variables named btnMuteUnmute, btnTranscribe, and btnHangup that will hold the Mute/Unmute, Transcribe, and HangUp buttons respectively. As the names suggest these buttons will allow the room participants to mute/unmute the microphone, toggle live transcription, and end the video call.
Add the following code below the btnHangup:
Here, you defined and called a function named initializeWaveEncoder() which is responsible for initializing the MediaRecorder wav encoder.
Add the following code below the initializeWaveEncoder() function call:
This code defines a function named handleMuteUnmute(). Its purpose is to toggle the mute/unmute status of a local audio track within your video call application.
The code begins with a conditional statement that checks if the room is undefined. If that is the case, the function immediately returns indicating that the user hasn’t joined a room yet.
The code then checks if the isMuted variable is set to false. If that is the case the code sets the isMuted variable to true and changes the Mute/Unmute button color to green, the icon to a microphone icon, and the tooltip text to Unmute to indicate that the microphone is muted.
However, if the isMuted variable is set to true, the code sets the variable to false and changes the Mute/Unmute button color to red and the icon to a microphone with a slash, and the tooltip text to Mute to indicate that the microphone isn’t muted.
Add the following code to the bottom of the handleMuteUnmute() function:
The code above iterates over each audio track that belongs to the local participant and for each track found it disables the track if the isMuted variable is set to true (microphone muted) and enables the track if isMuted is set to false (microphone unmuted).
Add the following code below the handleMuteUnmute() function:
This code defines a function named transcribe. This function is responsible for toggling the live transcription feature, which can enable or disable real-time transcription of the video call audio content.
This code also begins with a conditional statement that checks if the room is undefined. If that is the case the function immediately returns indicating that the user hasn’t joined a room yet.
The code then checks if the isTranscribing is set to false meaning that the transcription feature is disabled.
If that is the case, the code sets isTranscribing to true. The code then changes the Transcribe button color to red, and the tooltip to Disable live captions to indicate that the transcription is active.
Next, it retrieves the audio stream from the local participant's audio element, initializes and stores a MediaRecorder instance in a variable named mediaRecorder using the audio stream, and specifies the MIME type as 'audio/wav'.
Finally, it calls a function named recordAudio() to start recording audio.
Add the following code to the else statement in the transcribe() function:
If isTranscribing is set to true meaning the transcription feature is enabled, the code sets isTranscribing to false.
Next, it changes the Transcribe button color to green, and the tooltip to Enable live captions to indicate that the transcription is disabled.
Finally, it uses the mediaRecorder.stop() method to stop the MediaRecorder.
Add the following code below the transcribe() function:
This code defines the function named recordAudio() which is responsible for handling the recording of audio data using the MediaRecorder API and the extendable-media-recorder package.
The code first initializes an empty array called chunks. This array will be used to store audio data in chunks as it's recorded. It then uses the mediaRecorder.start() method to start the MediaRecorder, initiating the recording process.
Next, the code sets up an interval timer which It's configured to call mediaRecorder.stop() every 6 seconds. This timer effectively stops the recording process every 6 seconds thus limiting the audio recording to 6 seconds.
Next, it sets an event handler for the onstart event of the MediaRecorder. When the recording starts, it logs a message to the console indicating that the recorder has started.
Finally, it sets an event handler for the ondataavailable event of the MediaRecorder. This event is fired when audio data becomes available for the recorder.
Inside this event handler, there's a conditional check that checks whether the microphone is not muted. If it's not muted, the audio data e.data is pushed into the chunks array.
Add the remaining MediaRecorder event handler to the bottom of the recordAudio() function:
This code sets an event handler for the onstop event of the MediaRecorder. This event is fired when the recording stops, either due to manual stopping (pressing the Transcribe button) or because the 6-second interval timer triggered it.
Inside this event handler, the code first logs a message to the console indicating that the recorder has stopped.
The code then creates a Blob object named blob by assembling all the recorded audio data stored in the chunks array and sets the Blob type to audio/wav.
Next, It calls the uploadAudio() function passing the blob as an argument, to upload the recorded audio data.
After uploading the recorded data it resets the chunks array to an empty array.
Finally, if isTranscribing is set to true, indicating that transcription is still active, it restarts the MediaRecorder using the mediaRecorder.start() method. However, if isTranscribing is set to false, it clears the interval timer, effectively stopping the periodic recording.
Add the following code below the recordAudio() function:
This code defines a function named uploadAudio() which is responsible for uploading audio data to the /uploadAudio endpoint created earlier.
The code first creates a URL from the provided blob object and uses part of the URL to create a filename for the audio file.
The code then creates a new File object named file using the blob as its content and the filename as its name.
Next, the code creates an empty FormData object named formData and appends the file object to it with the field name 'audio'.
Add the following code to the bottom of the uploadAudio() function:
The code added uses the fetch API to send an HTTP POST request containing the formData to the server at the '/uploadAudio' endpoint.
After the POST request is complete, the code checks if the request was successful and if that is the case it calls a function named showTranscript() with the transcript data and the local participant's identity as arguments and a function named sendTranscript() function with the transcript data as an argument.
Add the following code below the uploadAudio() function:
Here, the code defines two functions named sendTranscript() and hangUp() .
The sendTranscript() function uses the DataTrack API to send a message containing the local participant microphone recording transcript to the remote participants in the room.
The hangUp() function checks if a room exists and if that is the case it disconnects from the room and redirects the user to the Twilio Programmable Video API page.
Add the following code below the hangUp() function:
Here you added click event listeners for the Mute/Unmute, Transcribe, and HangUp buttons.
When a button is clicked, it invokes the corresponding function (handleMuteUnmute(), transcribe(), or hangUp()), which carry out the intended action associated with that button, such as muting/unmuting audio, toggling live transcription, or ending a call.
Open the index.js file and add the following code to the bottom of this file:
This code defines the showTranscript() function which is responsible for displaying the recording transcript in a user-friendly format on the web page below the main webcam feed.
It creates HTML paragraph elements for each recording transcript, uses the participant’s identity to create a formatted username, sets the text content, and manages the display of these messages within a container where the username appears before the transcript.
It ensures that only two transcripts are shown at a time, replacing the oldest transcript with the newest one when necessary.
Add the following code to the message track event handler inside the handleTrackSubscription() function (located around line 109):
Here you are calling the showTranscript() function and passing the transcript stored in the message received and the participant’s identity as arguments to display the transcript on the web page.
Use the following command to start the server application:
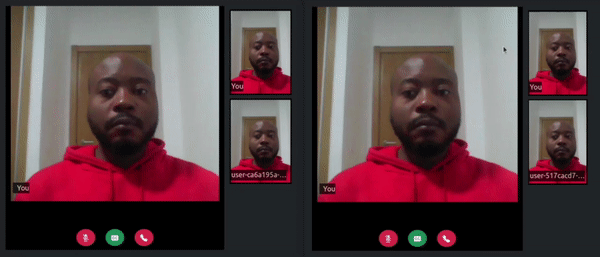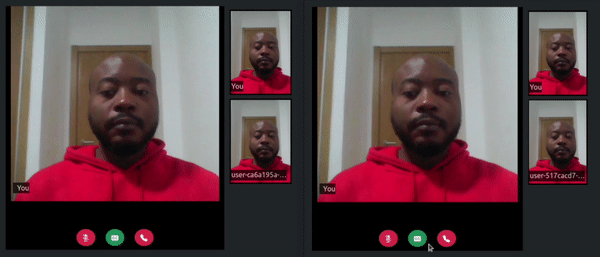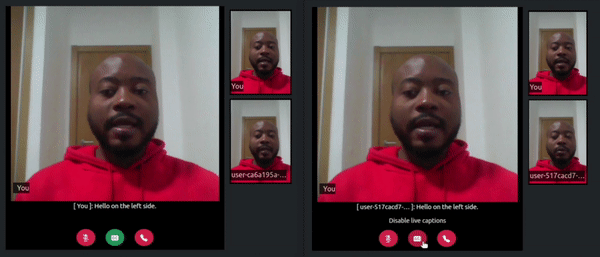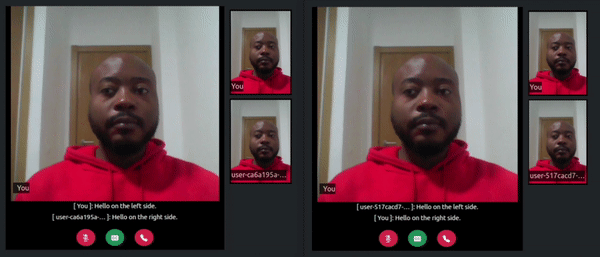
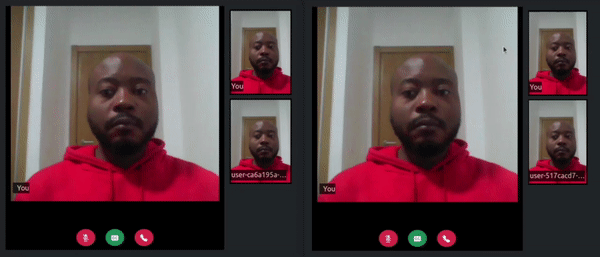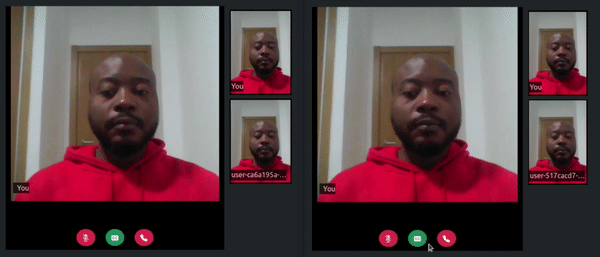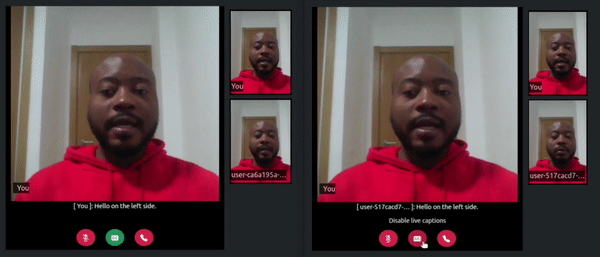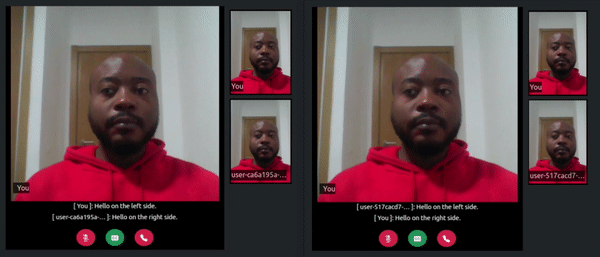
Once the server starts, refresh the tabs where you visited the http://localhost:3000/ URL. In one of the tabs click on the transcribe button, say something, and watch how a live transcript will appear in both the local and remote room participant’s tabs
Conclusion
In this tutorial, you learned how to add live transcriptions to a video call web app. First, you cloned a video call web app project, got familiarized with the code, and learned how the Twilio Video API creates a video room where room participants could join and communicate with each other. Next, you learned how to use the Tranformers.js package alongside the Whisper Tiny model to transcribe audio files and then added this functionality to the server application. Lastly, you used the MediaRecorder API to allow the room participants to record their microphones, send the recording to the server, transcribe the recording, use the DataTrack API to share the transcript among the room participants, and then display the transcript below the webcam feed.

Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.