Discovering Issues with HTTP/2 via Chaos Testing
Time to read:
October 27, 2017
Written by

TL;DR
While HTTP/2 provides for a number of improvements over HTTP/1.x, via Chaos Testing we discovered that there are situations where HTTP/2 will perform worse than HTTP/1.
When there is packet loss on the network, congestion controls at the TCP layer will throttle the HTTP/2 streams that are multiplexed within fewer TCP connections. Additionally, because of TCP retry logic, packet loss affecting a single TCP connection will simultaneously impact several HTTP/2 streams while retries occur. In other words, head-of-line blocking has effectively moved from layer 7 of the network stack down to layer 4.
Background & the Service Mesh Space
Service meshes are an increasingly common networking model for cloud native architectures. By putting the logic needed for fast and reliable interservice communications into a sidecar process, developers on independent teams, working in the technology stack of their choice, can get a consistent network transport without requiring libraries or changes to their application code.
In this out-of-process architecture, each application sends and receives messages to/from localhost and is unaware of the network topology. Transparent to the application, the service mesh sidecar can consistently handle issues such as: service discovery, load balancing, circuit breaking, retries, encryption, rate-limiting, etc.
Recently, the service mesh space has been very active, with new projects like Lyft’s Envoy, linkerd, and Traefik, joining nginx and HAProxy in an increasingly innovative landscape.
At Twilio, we were particularly intrigued by Envoy because of its rich feature set, including improved telemetry (via integrations with statsd and LightStep, which we already use), advanced AZ-aware routing capabilities, and consistent way for microservices to communicate with one another over encrypted connections. Additionally, Envoy’s backing by Google, recent inclusion into the CNCF, and rapid community growth gave us confidence that additional improvements to this software proxy would be coming in the future.
Enter HTTP/2
One additional feature built into Envoy seemed particularly interesting to us: Transparently upgrading HTTP/1 traffic to HTTP/2!
HTTP/2 is the newest major revision of the HTTP protocol, and its main improvements over HTTP/1 are that it is a binary/framed protocol, with multiplexing of HTTP requests into several bi-directional streams within persistent TCP connections. HTTP/2 also allows for compressed request/response headers for improved performance.
The support for persistent connections in HTTP/2 was particularly interesting to us because of its potential to reduce network latency between our services. Typically, creating a new TLS connection between hosts requires several round trips: In addition to the 3-way handshake for creating the TCP connection itself, negotiating an encrypted tunnel requires an additional two round trips between the hosts:
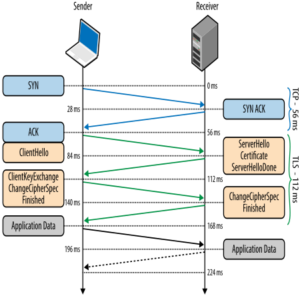
We speculated that being able to create persistent, encrypted TCP connections in a language-agnostic way via a sidecar process would satisfy our need for secure communications at very low latencies. The upgrade to HTTP/2’s other new features without having to make code-changes our existing services was extra icing on the cake.
Of course, we wanted to validate these technical benefits. With that, our team set out to test the benefits of upgrading our services to communicate with HTTP/2.
Chaos Engineering & Our Test Plan
Chaos engineering is a term coined by Netflix several years ago. In short, the core idea of Chaos engineering is to proactively inject failures to your systems. In doing so one can observe how their systems fail and apply improvements so that when a real disaster strikes, your services don’t suffer an outage.
The Principles of Chaos Engineering document describes Chaos Engineering as follows:
Chaos Engineering is the discipline of experimenting on a distributed system
in order to build confidence in the system’s capability
to withstand turbulent conditions in production.
In a distributed system that operates in the cloud, network latency and packet loss are common issues for service to service communications. To help make Twilio more reliable and resilient in the face of these issues, we performed chaos testing using the tc command to add varying combinations of network latency and packet loss to our services. Ex: 0ms/10ms/25ms network latency added; 0%/1%/3% packet loss added.
Our test configuration was setup as follows:
- Two c3.2xlarge instances within the same availability-zone in AWS
- Client running Vegeta at 1,000 HTTP requests/second through the localhost sidecar, with 1KB POST payload and a realistic set of request headers.
- Originally we ran with 2 minute iterations, but then shifted to 15 minute, overnight runs because of test result that seemed confusing at the time (more on this in the Test Results section ;) )
- Server running nginx with a
return 200location, returning a static 1KB body. - A few tuned sysctls, but otherwise the default for our Linux AMI:
net.core.somaxconnnet.ipv4.tcp_fin_timeoutnet.ipv4.ip_local_port_range
And finally, we wanted to test the following side-car configurations:
- No sidecar (ie. direct client-server)
- HAProxy sidecar
- Single, egress-only Envoy using HTTP/1 (analogous to an HAProxy configuration)
- Double-Envoy using HTTP/1
- Double-Envoy using HTTP/2
- Double-Envoy using HTTP/2 & TLS
HTTP Request Latency Test Results
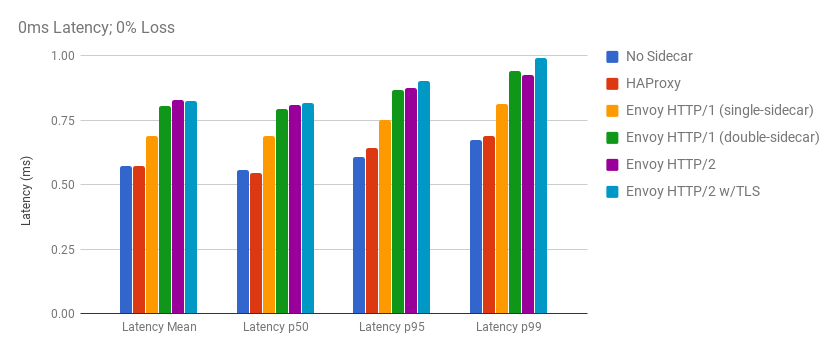
At the baseline, the transparent HTTP/2 upgrading feature of Envoy performed similarly to HAProxy and our no-sidecar configuration. In the above graph where latency and packet loss were not artificially added by our chaos engineers, we can see that the mean/median/p95/p99 request latencies are similar to one another for all scenarios. The differences here are merely fractions of a millisecond for transparently upgrading our traffic to HTTP/2, despite getting extra functionality and benefits from HTTP/2.
The results got much more interesting in our Chaos Testing scenarios though, particularly when 3% packet loss was added:
Here we are looking at just the p99 latencies at 3% packet loss, with varying levels of added network latency being added. Looking across the board one can see that when using HTTP/2, the 99th% request latencies consistently perform worse when there is 3% packet loss (purple and light blue bars).
These results were very confusing to us. Wasn’t HTTP/2 supposed to be better than HTTP/1? HTTP/2 is a binary protocol, has multiplexing, persistent connections, and compressed headers. Shouldn’t HTTP/2 be beating HTTP/1 in every test? How could it possibly be worse?
We initially thought this was something wrong in our testing: Perhaps intermittent networking issues in AWS’s cloud or code-errors in our test automation. We repeatedly ran the tests over nights and weekends, while reviewing the testing code for bugs. Unfortunately, the test results were very repeatable.
Searching for an explanation to this mystery, we decided to look deeper into the data. Using Vegeta’s -dump mode, we could generate a CSV of the network latency for every HTTP request that was performed during the tests. We could then use that CSV to generate a scatter plot graph to see request latency patterns in the underlying data. This gave us significantly more visibility into what was happening with each network request, as compared to the previously seen bar graphs which mask data via their respective aggregations.
The results we discovered via these scatter plot graphs was very shocking!
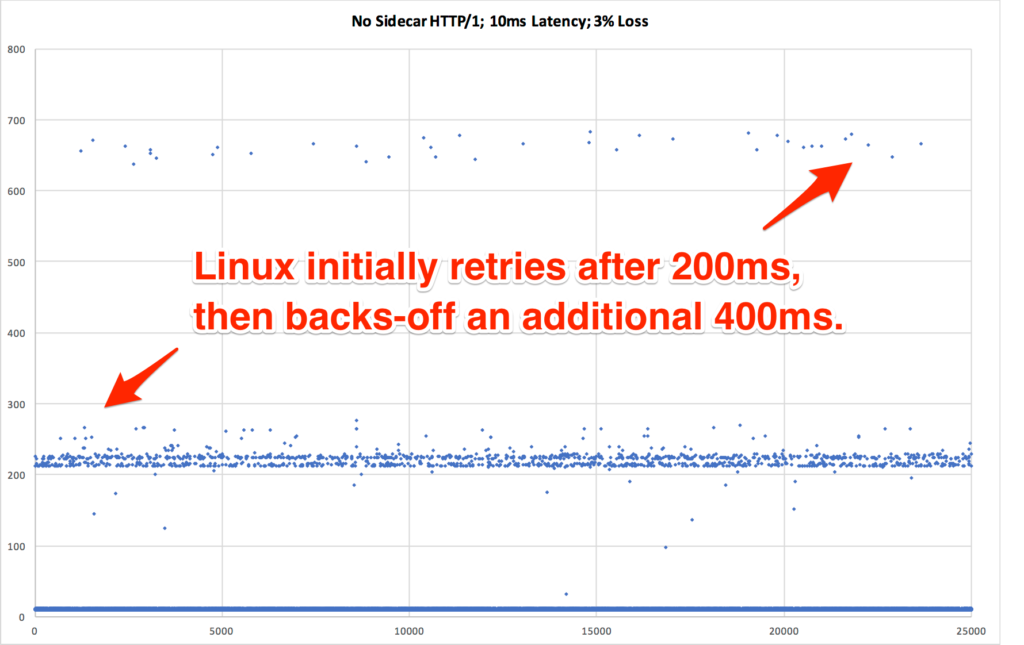
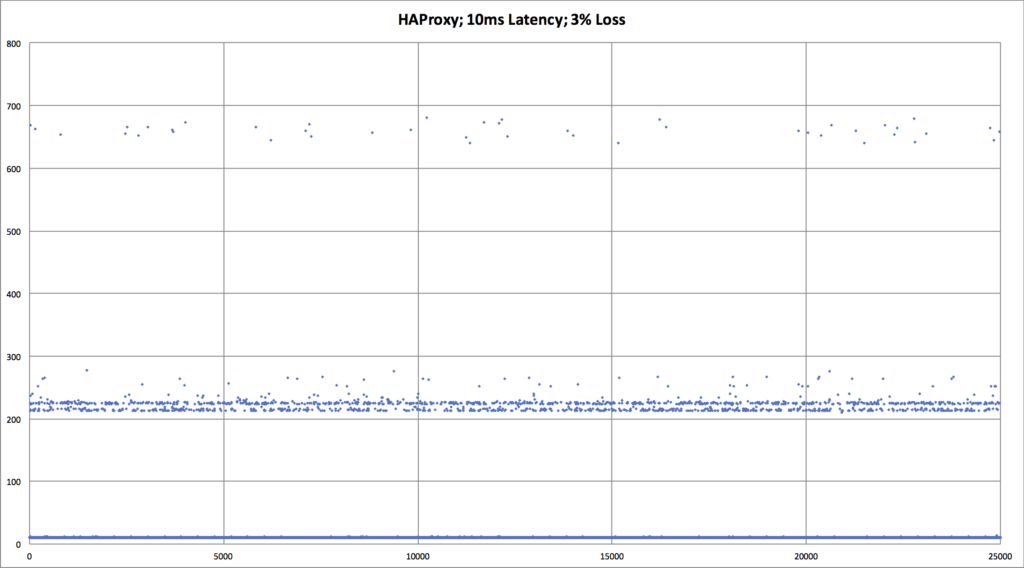
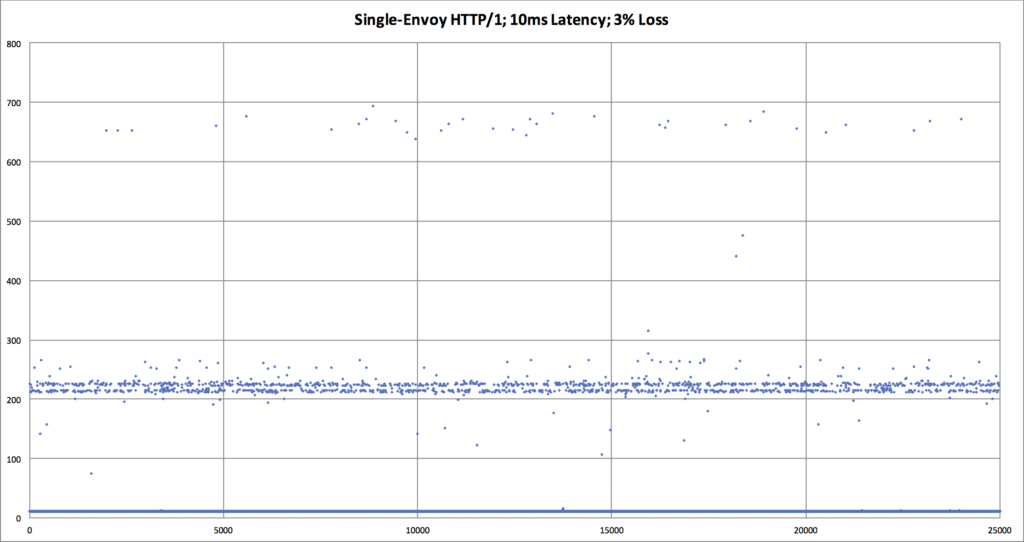
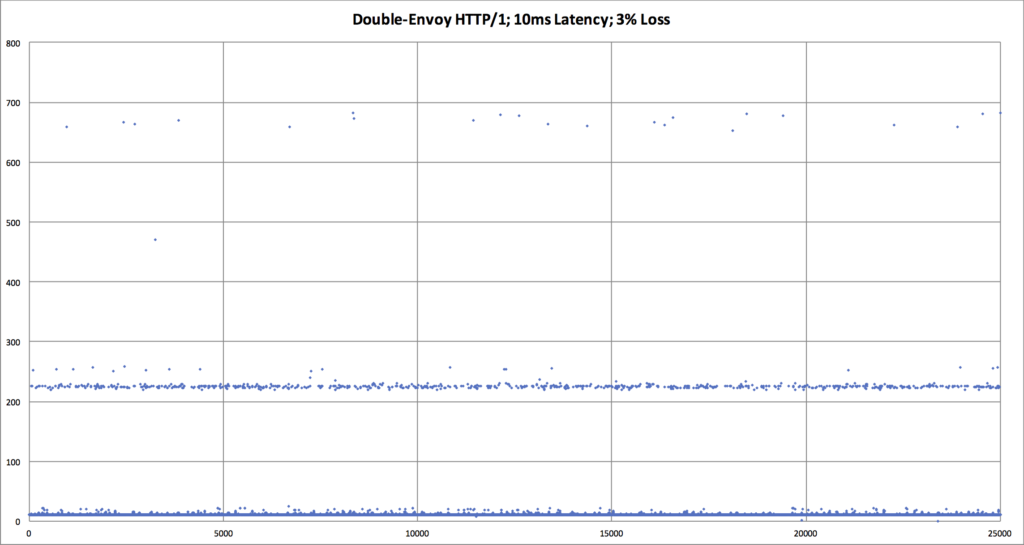
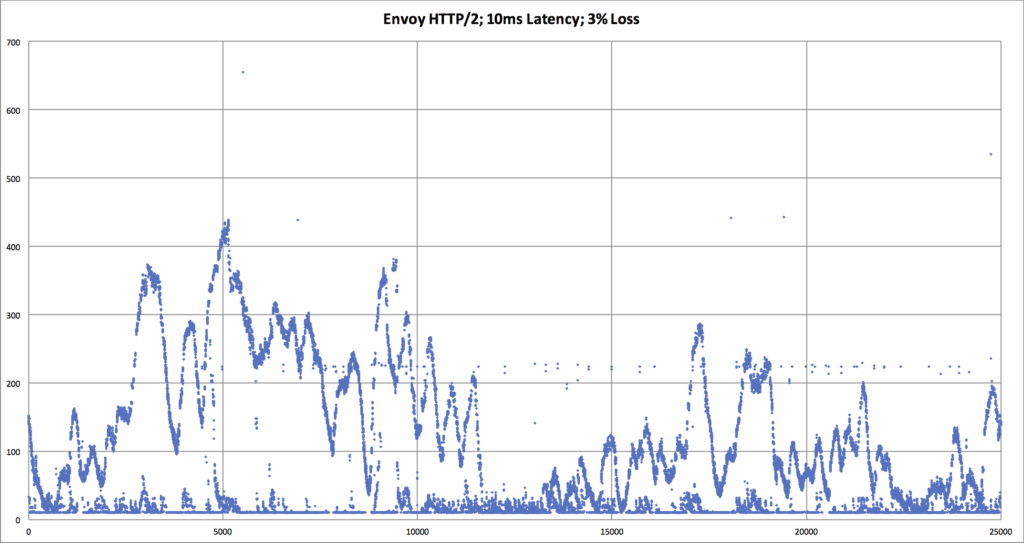
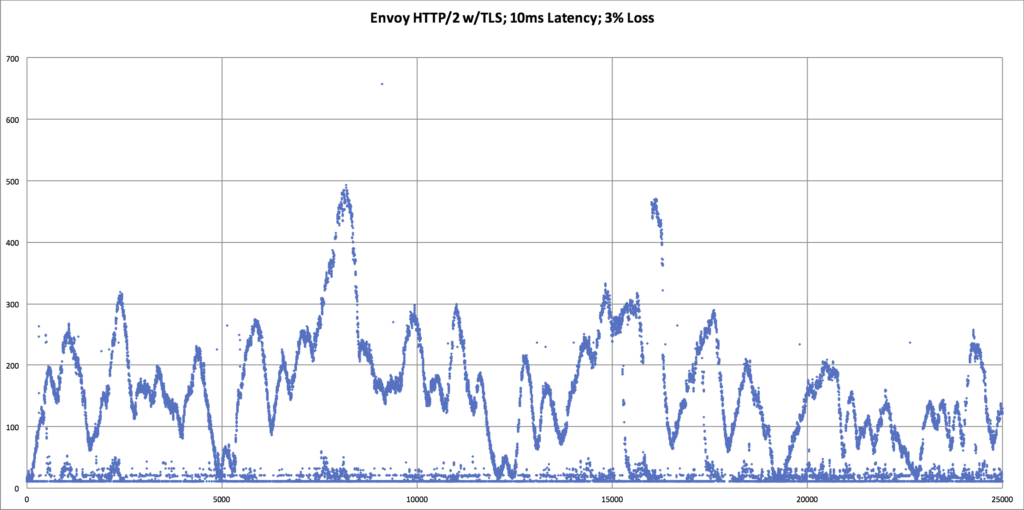
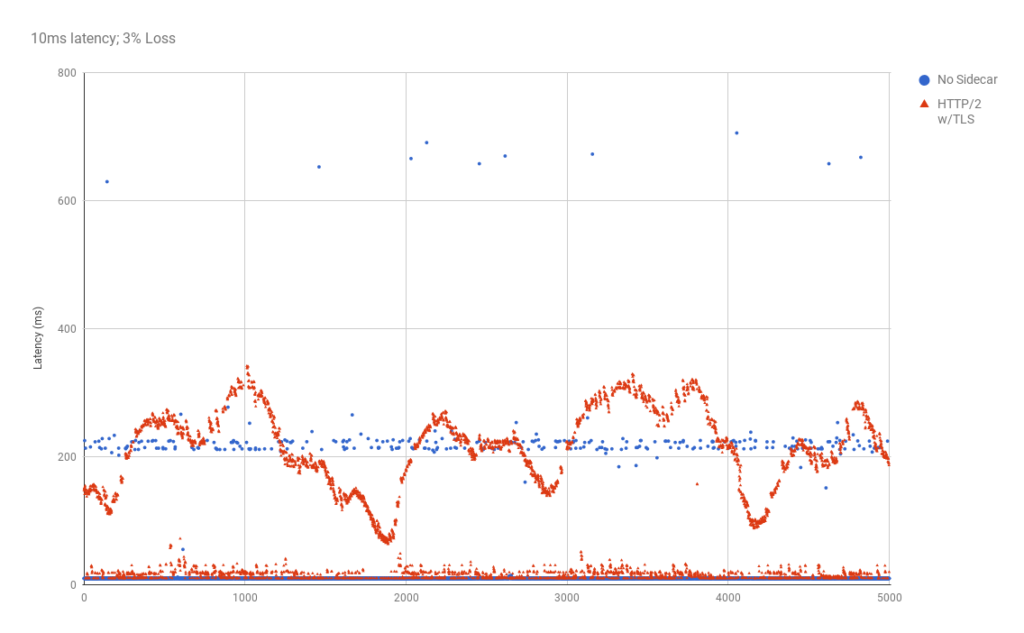
| An overlay comparing HTTP/1 vs HTTP/2, when there is packet loss. We can now see that the p99 request latency for HTTP/2 is worse. We need an explanation for why, though. |
Interpretation of HTTP/2 Test Results
The obvious question from the above graphs are: “What’s up with HTTP/2? Why do the request latency times look sinusoidal?”
Imagine the following scenarios:
- HTTP/1: Each HTTP request has it’s own TCP connection, and each TCP connection is independently trying to determine its own respective optimal TCP congestion window (CWND).
- If packet loss is encountered by any one of those TCP connections, the other connections are not affected.
- If packet loss is encountered by several of the TCP connections, the total throughput is a function of a relatively large number of TCP connections.
- HTTP/2: There are fewer TCP connections, which are persistent. Each TCP connection has several HTTP/2 streams multiplexed within it.
- When packet loss occurs, all streams within that TCP connection will suffer two penalties:
- Penalty #1: All HTTP streams within the TCP connection are simultaneously held-up while waiting for re-transmit of the lost packet. ie. Head-of-line blocking for HTTP requests has moved from Layer 7 to Layer 4.
- Penalty #2: TCP window size will drop dramatically, and all streams will be simultaneously throttled down.
- When packet loss occurs, all streams within that TCP connection will suffer two penalties:
- Since there are also fewer TCP connections than in the HTTP/1 scenario, the total throughput will necessarily be lower than w/HTTP/1. (ie. N bad connections > M bad connections, when N > M) In other words, one of HTTP/2’s strengths is also one of its big weaknesses.
It is important to remember that the issues identified here are not specific to Envoy. At Twilio, we are still moving forward with Envoy as our service mesh sidecar because it fulfils a business need of providing a transparent and consistent service mesh between our microservices, whether it be over HTTP/1 or HTTP/2.
Additionally, one should remember that latency and packet loss in these tests was introduced synthetically with tc. In the real world, one is not likely to see several hours of sustained packet loss at precisely 3.00%. Twilio has a sophisticated set of tools to monitor network conditions, and now that we are attuned to the weaknesses of HTTP/2, we can be be alerted to when those conditions may be adversely affecting our platform, for use cases where we are using HTTP/2. Additionally, Envoy provides significantly more metrics and visibility via its statsd & Lightstep integrations, which adds to our monitoring toolbox.
Finally, if you’re looking for some additional reading that relates to all of this, I highly recommend reading the RFC for QUIC, a UDP-based Transport for HTTP/2. In section 5.4, the authors from Google specifically call out these issues with HTTP/2 over TCP, and details their suggestions for a next-generation protocol which moves flexible congestion controls to the application layer.
Closing Thoughts
Cloud services can have wildly different technology requirements. Imagine, for example: A marketing SaaS vs. a messaging app vs. a streaming video service.
Twilio operates a global communications network that needs to be up around the clock, and it’s important for us to understand how our services will behave in a variety of situations, at scale. Through chaos testing, we were able to identify architectural tradeoffs in HTTP/2 that cause it to perform worse than HTTP/1 when there is packet loss in the network.
Depending on your use-cases though, HTTP/2 may be right for you. That decision should be based on a full technology evaluation, which should include a healthy dose of chaos engineering. In doing that, you can ensure that your services will be able to operate with exceptional reliability and resiliency, at scale.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.