Le guide ultime du modèle de langage GPT-3 d'OpenAI
Time to read:
August 25, 2020
Rédigé par
Révisé par

Generative Pre-trained Transformer 3 (GPT-3) est un nouveau modèle de langage créé par OpenAI et capable de générer du texte écrit d'une qualité telle qu'il est souvent difficile de le distinguer d'un texte écrit par un humain.
Dans cet article, nous découvrirons comment travailler avec GPT-3 sur une variété de cas d'usage, de son utilisation comme assistant d'écriture à la construction d'un chatbot très sophistiqué. À la fin de cette lecture, vous saurez comment programmer GPT-3 de sorte qu'il puisse discuter avec vous de vos sujets préférés. Voici un exemple d'une courte conversation que j'ai eue avec le bot sur Python et le développement web.

Est-il vraiment aussi bon que ça ?
Vous avez du mal à croire que le GPT-3 puisse générer du texte quasiment impossible à différencier d'une production humaine ? Voici un autre exemple qui vous permettra de juger par vous-même.
Les deux paragraphes suivants ont été générés par le moteur GPT-3 pour se décrire lui-même, après que je l'ai entraîné en lui montrant simplement le premier paragraphe de l'article GPT-3 sur Wikipédia. Veuillez noter que je copie le texte suivant mot pour mot ; c'est exactement ce que GPT-3 a produit, sans aucune modification autre qu’une traduction.
GPT-3 est un réseau neuronal profond qui utilise le mécanisme d'attention pour prédire le mot suivant dans une phrase. Il est entraîné sur un corpus de plus de 1 milliard de mots, et peut générer du texte avec un niveau de précision allant jusqu'au caractère près. L'architecture de GPT-3 repose sur deux composants principaux : un encodeur et un décodeur. L'encodeur prend comme entrée le mot précédent dans la phrase et produit une représentation vectorielle de celui-ci, laquelle est ensuite soumise à un mécanisme d'attention afin de produire la prédiction du mot suivant. Le décodeur prend comme entrée le mot précédent et sa représentation vectorielle, et génère une distribution de probabilité sur l'ensemble des mots possibles à partir de ces entrées.
Les performances de GPT-3 sont comparables aux meilleurs modèles de langage pour la génération de textes, faisant ainsi nettement mieux que les modèles GPT précédents. Le modèle Turing-NLG de Microsoft peut générer du texte avec une précision de l'ordre du caractère sur un jeu de test d'articles Wikipédia, mais nécessite pour cela un volume de données d'entraînement considérable. OpenAI affirme que GPT-3 peut atteindre ce niveau de performance sans aucune donnée d'entraînement supplémentaire après sa phase initiale de pré-entraînement. En outre, GPT-3 est capable de générer des phrases et des paragraphes plus longs que ceux produits par des modèles antérieurs tels que le modèle BERT de Google et le NLP Transformer de Stanford.
Impressionnant, n'est-ce pas ?
Ce que nous allons construire
Nous allons apprendre à travailler avec l'OpenAI Playground, une interface en ligne qui, comme son nom l'indique, vous permet de jouer et de créer des prototypes de solutions basées sur GPT-3.
Nous n'allons pas construire un projet unique spécifique, mais plutôt mettre en œuvre quelques prototypes différents pour un éventail de problèmes différents.
À la fin, nous verrons également comment transférer le travail que vous aurez accompli depuis l'interface Playground vers une application Python autonome.
Conditions préalables
Pour suivre les exemples présentés dans ce tutoriel, la seule chose dont vous avez besoin, c'est une licence OpenAI GPT-3. Au moment même où j'écris ceci, OpenAI exécute un programme bêta pour GPT-3, et vous pouvez directement leur demander une licence bêta.
Si vous souhaitez écrire des applications GPT-3 autonomes en Python, vous devez également installer Python 3.6 ou une version ultérieure. Cela reste toutefois entièrement facultatif, vous pouvez ignorer la section Python si elle ne vous intéresse pas.
L'interface OpenAI Playground
Comme je l'ai dit plus haut, j'ai dû « entraîner » GPT-3 pour qu'il produise en sortie le texte désiré. Cela s'avère étonnamment facile, et vous pouvez le faire depuis l'interface OpenAI Playground. La capture d'écran ci-dessous montre l'instance de Playground dans laquelle j'ai généré le texte présenté plus haut :
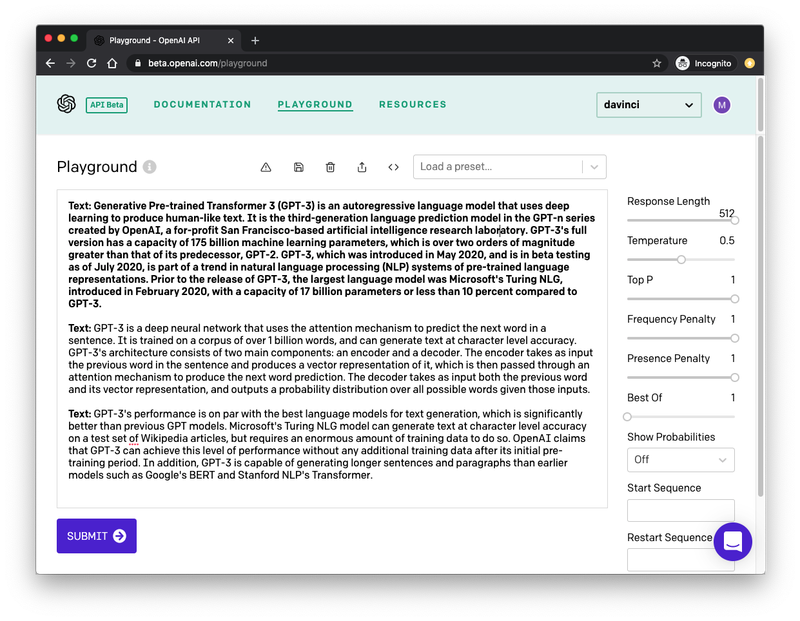
Permettez-moi de vous expliquer les principaux aspects de cette interface.
Dans la barre latérale de droite figurent quelques options permettant de configurer le type de sortie que nous souhaitons que GPT-3 produise. Je reviendrai plus en détail sur ces paramètres dans la suite de cet article.
La grande zone de texte est l'endroit où vous interagissez avec le moteur GPT-3. Le premier paragraphe, qui apparaît en gras, correspond à ce que GPT-3 reçoit en entrée. J'ai précédé ce paragraphe du préfixe Text:, et ai collé ensuite le texte que j'ai copié d'un article Wikipédia. C'est là l'aspect clé de l'entraînement de ce moteur : vous lui enseignez le type de texte que vous voulez qu'il génère en lui donnant des exemples. Dans bien des cas, un seul exemple suffit, mais vous pouvez en fournir davantage.
Le deuxième paragraphe commence par le même préfixe Text:, apparaissant lui aussi en gras. Cette deuxième occurrence du préfixe constitue la dernière partie de l'entrée. Nous donnons à GPT-3 un paragraphe composé du préfixe et d'un exemple de texte, suivi d'une ligne qui ne contient que le préfixe. C'est ce qui permet de signaler à GPT-3 qu'il doit générer du texte afin de compléter le deuxième paragraphe d'une manière qui corresponde au premier du point de vue du ton et du style.
Une fois votre texte d'entraînement défini et vos options paramétrées à votre convenance, il suffit d'appuyer sur le bouton « Submit » en bas de l'écran pour que GPT-3 analyse le texte en entrée et en génère d'autres équivalents. Si vous appuyez une nouvelle fois sur « Submit », GPT-3 s'exécute à nouveau et produit un autre fragment de texte.
Tout ce que j'ai fait pour générer les deux paragraphes ci-dessus, c'est définir mon texte en entrée et appuyer deux fois sur le bouton « Submit » !
Utilisation des préréglages de GPT-3
Allez, c'est parti ! Connectez-vous à l'OpenAI Playground afin de vous familiariser avec l'interface.
Dans le coin supérieur droit de la barre de navigation se trouve une liste déroulante permettant de sélectionner un modèle de langage parmi les différents proposés :
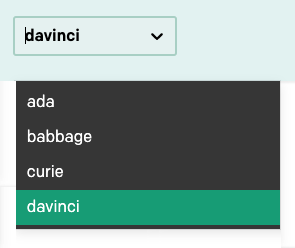
Dans ce tutoriel, nous n'utiliserons que le modèle davinci, qui est le plus avancé à l'heure actuelle. Veillez donc à ce que ce soit bien le modèle sélectionné. Une fois que vous aurez appris à travailler dans l'interface Playground, vous pourrez passer aux autres modèles et expérimenter avec eux également.
Au-dessus de la zone de texte se trouve une autre liste déroulante indiquant « Load a preset... ».
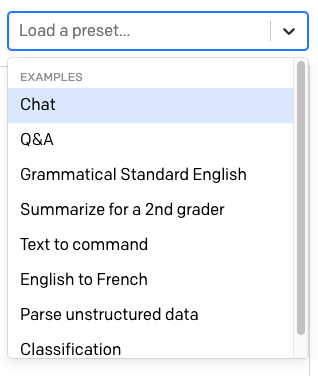
OpenAI y fournit un certain nombre de préréglages prêts à l'emploi pour différentes utilisations de GPT-3.
Sélectionnez le préréglage « English to French ». Lorsque vous choisissez un préréglage, le contenu de la zone de texte est mis à jour avec un texte d'entraînement prédéfini pour celui-ci. Les paramètres de la barre latérale de droite sont également mis à jour.
Dans le cas du modèle « English into French », le texte présente quelques phrases en anglais, chacune accompagnée de sa traduction en français :

Comme dans mon propre exemple ci-dessus, chaque ligne commence par un préfixe. Cette application présentant des lignes en anglais et en français, le préfixe diffère afin d'aider GPT-3 à comprendre le schéma.
Notez qu'au bas du texte apparaît un préfixe English: vide. C'est là que nous allons pouvoir saisir le texte que nous souhaiterions que GPT-3 traduise en français. Saisissez maintenant une phrase en anglais, puis appuyez sur le bouton « Submit » pour que GPT-3 génère la traduction française. Voici l'exemple que j'ai utilisé :

Le préréglage ajoute pour vous une autre invite English: vide afin que vous puissiez saisir directement la phrase suivante à traduire.
Tous les préréglages fournis par OpenAI sont faciles à utiliser et suffisamment explicites. Il serait donc judicieux que vous vous amusiez avec d'autres à ce stade. Je vous recommande notamment les préréglages « Q&A » et « Summarize for a 2nd grader ».
Création de vos propres applications GPT-3
Bien qu'il y ait déjà de quoi s'amuser avec les préréglages fournis par l'OpenAI Playground, vous aurez sûrement vos propres idées quant aux utilisations du moteur GPT-3. Dans cette section, nous allons nous intéresser à toutes les options qu'offre l'interface Playground pour vous permettre de créer vos propres applications.
Créer votre propre solution basée sur GPT-3 implique d'écrire le texte en entrée qui va servir à entraîner le moteur, et de régler les paramètres de la barre latérale en fonction de vos besoins.
Pour suivre les exemples de cette section, assurez-vous de rétablir les paramètres par défaut de l'interface Playground. Pour ce faire, supprimez tout le texte de la zone de texte, et si un préréglage est sélectionné, cliquez sur la croix « x » à côté de son nom pour le supprimer.

Température
L'un des réglages les plus importants pour contrôler la sortie produite par le moteur GPT-3 est la température. Celui-ci contrôle le caractère aléatoire du texte généré. Une valeur de 0 rend le moteur déterministe, ce qui signifie qu'il générera toujours la même sortie pour un texte en entrée donné. Avec une valeur de 1, le moteur prendra le plus de risques et se montrera très créatif.
Quand je crée un prototype d'application, j'aime commencer en réglant la température sur 0, donc commençons par là. Le paramètre « Top P » qui apparaît sous la température permet également de contrôler dans une certaine mesure le caractère aléatoire de la réponse, donc veillez à ce qu'il soit réglé sur sa valeur par défaut de 1. Laissez aussi tous les autres paramètres réglés sur leurs valeurs par défaut.
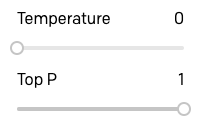
Avec cette configuration, GPT-3 se comportera de manière très prévisible. C'est donc un bon point de départ pour faire quelques essais.
Vous pouvez maintenant taper du texte, puis appuyer ensuite sur « Submit » pour voir comment GPT-3 ajoute du texte supplémentaire. Dans l'exemple ci-dessous, j'ai tapé le texte Python is et laissé GPT-3 compléter la phrase.

Incroyable, n'est-ce pas ?
Avant de continuer, sachez que GPT-3 n'aime pas les chaînes d'entrée qui se terminent par une espace, pouvant entraîner des comportements étranges, voire imprévisibles. Si vous avez tendance à ajouter un espace après le dernier mot de votre entrée, gardez alors à l'esprit que cela peut causer des problèmes. L'interface Playground affichera un message d'avertissement si vous laissez par erreur un ou plusieurs espaces à la fin de votre entrée.
Augmentez maintenant la température à 0.5. Supprimez le texte généré ci-dessus, en ne laissant une fois de plus que Python is, puis cliquez sur « Submit ». GPT-3 va désormais prendre plus de libertés dans la manière dont il va compléter la phrase. Voici ce que j'ai obtenu :

Quand vous essaierez ceci, vous obtiendrez probablement un résultat différent. Et si vous essayez plusieurs fois, il sera différent à chaque fois.
N'hésitez pas à essayer différentes valeurs de température afin de voir comment elles influent sur la créativité dont GPT-3 fait preuve dans ses réponses. Une fois que vous êtes prêt à continuer, réglez à nouveau la température sur 0 et relancez la requête Python is initiale.
Longueur de réponse
Les textes complétés dans la section précédente étaient vraiment bons, mais vous avez sans doute remarqué que GPT-3 s'arrête souvent au beau milieu d'une phrase. Pour contrôler la quantité de texte générée, vous pouvez utiliser le paramètre « Response Length ».
Le paramètre par défaut de la longueur de réponse est 64, ce qui signifie que GPT-3 ajoutera 64 jetons au texte, un jeton désignant un mot ou un signe de ponctuation.
Avec la réponse initiale à l'entrée Python is, une température réglée sur 0 et une longueur de 64 jetons, vous pouvez appuyer une deuxième fois sur le bouton « Submit » pour que GPT-3 ajoute un autre jeu de 64 jetons à la fin.

Mais là encore, bien sûr, on retrouve une phrase incomplète à la fin. Une astuce simple que vous pouvez utiliser consiste à définir la longueur sur une valeur supérieure à ce dont vous avez besoin, puis à ignorer le passage incomplet qui se trouve à la fin. Nous verrons plus tard comment enseigner à GPT-3 à s'arrêter au bon endroit.
Préfixes
Comme vous l'avez vu, quand j'ai généré les deux paragraphes de démonstration au début de cet article, j'ai précédé chaque paragraphe du préfixe Text:. Vous avez vu aussi que le préréglage de traduction de l'anglais vers le français utilisait les préfixes English: et French: sur les lignes correspondantes.
L'utilisation d'un préfixe court pour chaque ligne de texte est un outil très utile pour aider GPT-3 à mieux comprendre la réponse attendue. Prenons une application simple dans laquelle nous voulons que GPT-3 génère des noms de variables métasyntaxiques que nous pouvons utiliser lors de l'écriture de code. Il s'agit de variables de texte fantôme telles que foo et bar, souvent utilisées dans les exemples de codage.
Nous pouvons entraîner GPT-3 en lui montrant l'une de ces variables et en le laissant en générer d'autres. En suivant l'exemple précédent, nous pouvons utiliser foo comme entrée, mais cette fois nous appuierons sur Entrée et déplacerons le curseur sur une nouvelle ligne, afin de dire à GPT-3 que nous voulons que la réponse soit sur la ligne suivante. Malheureusement, cela ne fonctionne pas, car GPT-3 ne « saisit » pas ce que nous voulons :

Le problème ici est que nous ne disons pas clairement à GPT-3 que ce que nous voulons, c'est avoir plus de lignes similaires à celle que nous avons saisie.
Essayons d'ajouter un préfixe pour voir si cela améliore notre entraînement. Ce que nous allons faire, c'est utiliser comme entrée var: foo, mais nous allons aussi forcer GPT-3 à suivre notre schéma en tapant var: sur la deuxième ligne. Parce que la deuxième ligne est maintenant incomplète par rapport à la première, nous indiquons plus clairement que nous voulons que « quelque chose comme foo » y soit ajouté.
Et cela fonctionne beaucoup mieux :

Séquences d'arrêt
Dans tous les exemples que nous avons essayés, nous sommes confrontés au problème que GPT-3 génère un flux de texte jusqu'à la longueur demandée puis s'arrête, souvent au milieu d'une phrase. L'option « Stop Sequences », située en bas de la barre latérale droite, vous permet de définir une ou plusieurs séquences qui, lorsqu'elles sont générées, forcent GPT-3 à s'arrêter.
Si on suit l'exemple de la section précédente, disons que nous aimerions n'avoir qu'une seule nouvelle variable à chaque fois que nous invoquons le moteur GPT-3. Dans la mesure où nous précédons chaque ligne du préfixe var:, et où nous amorçons le moteur en saisissant le préfixe seul dans la dernière ligne de l'entrée, nous pouvons utiliser ce même préfixe comme séquence d'arrêt.
Recherchez le champ « Stop Sequences » dans la barre latérale et saisissez var: puis appuyez sur Tab.
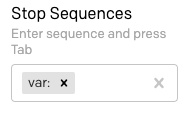
Maintenant, réinitialisez le texte d'entrée de sorte d'avoir var: foo sur la première ligne et uniquement var: sur la deuxième ligne, puis cliquez sur « Submit ». Le résultat est maintenant une variable unique :

Tapez à nouveau var: sur la troisième ligne du texte d'entrée et soumettez à nouveau, et vous en obtiendrez une de plus.

Démarrer le texte
Nous faisons des progrès. Nous arrivons à faire en sorte que GPT-3 nous donne les réponses que nous attendons. Notre ennui, maintenant, c'est que chaque fois que nous voulons demander une réponse, nous devons saisir manuellement le préfixe pour la ligne que GPT-3 doit compléter.
L'option « Inject Start Text » située dans les paramètres indique à l'interface Playground quel texte ajouter automatiquement à l'entrée avant d'envoyer une requête à GPT-3. Placez le curseur dans ce champ et tapez var:.

Maintenant, réinitialisez le texte vers une seule ligne indiquant var: foo. Appuyez sur Entrée pour placer le curseur au début de la deuxième ligne, puis sur « Submit » pour voir la variable suivante. Chaque fois que vous appuierez sur « Submit », vous en obtiendrez une nouvelle, et les préfixes seront insérés automatiquement.

Utilisation de plusieurs préfixes
Le générateur de noms de variables utilisé dans les dernières sections suit une approche simple, qui est de montrer à GPT-3 un exemple de texte pour obtenir davantage de texte similaire. J'ai utilisé cette même méthode pour générer les deux paragraphes de texte présentés au début de cet article.
Une autre méthode d'interaction avec le GPT-3 consiste à lui faire appliquer une sorte d'analyse et de transformation au texte d'entrée afin de produire la réponse. Jusqu'à présent, nous avons uniquement vu que le préréglage de traduction de l'anglais au français comme exemple de ce type d'interaction. Parmi les autres possibilités figurent les chatbots de questions-réponses, la correction par GPT-3 d'erreurs grammaticales dans le texte d'entrée, et d'autres encore plus ésotériques telles que la conversion d'instructions de conception données en anglais au format HTML.
L'avantage dans ces projets, c'est qu'il y a un dialogue entre l'utilisateur et GPT-3, ce qui exige l'utilisation de deux préfixes afin de marquer séparément les lignes qui appartiennent à l'utilisateur et celles qui appartiennent à GPT-3.
Pour illustrer ce type de style de projet, nous allons construire un bot ELI5 (Explain Like I'm 5), qui acceptera de l'utilisateur un concept complexe et en donnera en sortie une explication utilisant des mots simples qu'un enfant de cinq ans pourra comprendre.
Rétablissez l'état initial par défaut de votre interface Playground en cliquant sur l'icône en forme de corbeille.

Pour créer le bot ELI5, nous allons montrer à GPT-3 un exemple d'interaction. La ligne indiquant le concept que nous voulons que le moteur explique va utiliser le préfixe thing:, tandis que la ligne sur laquelle apparaîtra l'explication va utiliser eli5:. Voici comment nous pouvons entraîner GPT-3 à cette tâche en utilisant le « microphone » comme exemple d'entraînement :

Facile, n'est-ce pas ? Nous devons veiller à bien utiliser des mots simples dans la réponse qui servira à l'entraînement, car nous voulons que GPT-3 génère d'autres réponses dans un style similaire.
L'option « Inject Start Text » peut être définie sur [enter]eli5:, de sorte que l'interface Playground ajoute automatiquement le préfixe pour la ligne de GPT-3.

Nous devons également définir une séquence d'arrêt afin que GPT-3 sache quand s'arrêter. Nous pouvons utiliser ici thing:, afin de garantir que GPT-3 comprenne que les lignes « thing » n'ont pas besoin d'être générées. N'oubliez pas que dans ce champ, vous devez appuyer sur la touche Tab pour terminer la saisie de la séquence d'arrêt.
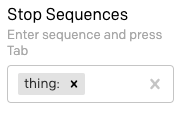
J'ai défini la longueur de réponse sur la valeur maximale de 512, puisque la séquence d'arrêt est la façon dont nous indiquons à GPT-3 de s'arrêter. J'ai également déplacé le curseur de température sur 0.25, de sorte que les réponses ne soient pas trop embellies ou aléatoires, mais sur ce point vous pouvez vous amuser avec différents réglages et trouver ce qui fonctionne le mieux pour vous.
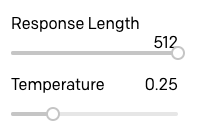
Prêt à essayer notre robot ELI5 ? Voici une première tentative :

C'est plutôt bon, n'est-ce pas ? La température étant réglée sur une valeur différente de zéro, les réponses que vous obtiendrez pourront différer légèrement des miennes.
Redémarrer le texte
Si vous avez commencé à vous amuser avec le bot ELI5 de la section précédente, vous avez peut-être remarqué que vous devez retaper le préfixe thing: à chaque fois que vous voulez poser une nouvelle question au bot.
L'option « Inject Restart Text » de la barre latérale peut être utilisée pour insérer automatiquement du texte après la réponse de GPT-3, nous pouvons donc l'utiliser pour saisir automatiquement le préfixe suivant. J'ai saisi ici le préfixe thing: suivi d'une espace.
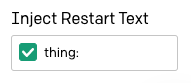
Il est maintenant beaucoup plus facile de s'amuser et d'interagir avec GPT-3 et de faire en sorte qu'il nous explique des choses !

L'option « Top P »
L'argument « Top P » constitue un autre moyen de contrôler le caractère aléatoire et la créativité du texte généré par GPT-3. La documentation d'OpenAI recommande de n'utiliser que l'un des deux paramètres Temperature et Top P. Par conséquent, lorsque vous utilisez l'un d'eux, assurez-vous que l'autre est bien réglé sur 1.
Curieux d'expérimenter et de voir à quel point les réponses de GPT-3 varieraient en utilisant le paramètre Top P au lieu de Temperature, j'ai augmenté la température à 1 et baissé Top P à 0.25 :
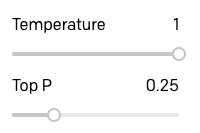
J'ai ensuite répété la session ci-dessus.

Comme vous pouvez le voir, il n'y a pas une différence énorme, mais je crois que la qualité des réponses est un peu inférieure. Voyez comme la réponse au voyage dans le temps est une très mauvaise explication, et comme GPT-3 fait référence à l'idée de trouver des informations dans deux des réponses.
Pour voir si je pouvais améliorer un peu ces réponses, j'ai augmenté le paramètre Top P jusqu'à 0.5 :
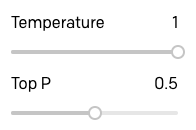
Les réponses sont nettement meilleures :

Pour conclure mes recherches sur les paramètres Temperature et Top P, j'ai essayé les mêmes requêtes avec une valeur de température de 0.5 :
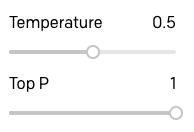
Voici les résultats :

De toute évidence, pour ce type d'application, une température de 0.5 est un peu trop élevée, et GPT-3 devient plus vague et adopte un ton plus informel dans ses réponses.
Après m'être amusé avec plusieurs projets et avoir essayé les paramètres Temperature et Top P, j'en conclus que Top P offre un meilleur contrôle pour les applications dans lesquelles GPT-3 est censé générer du texte précis et exact, tandis que Temperature fonctionne mieux pour les applications où l'on recherche des réponses originales, créatives, voire amusantes.
Pour le bot ELI5, j'ai décidé qu'utiliser le paramètre Top P réglé sur 0.5 est ce qui fournit les meilleures réponses.
Préréglages personnalisés
Nous nous sommes à présent amusés avec la plupart des options de configuration, et disposons d'une première application intéressante, notre bot ELI5.
Avant de passer à la construction d'un autre projet, je vous suggère d'enregistrer le bot ELI5, ainsi que les paramètres qui d'après vous fonctionnent le mieux pour vous.
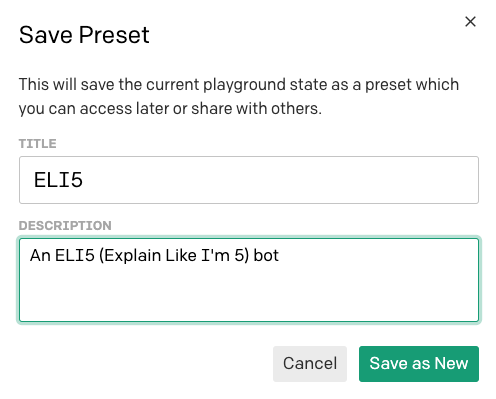
Commencez par réinitialiser le texte afin qu'il n'inclue que la portion d'entraînement avec la définition d'un microphone, plus le préfixe thing: sur la troisième ligne. Une fois que vous avez réinitialisé le texte sur l'entraînement initial, utilisez l'icône en forme de disquette pour enregistrer le projet en tant que préréglage :

Pour chaque préréglage enregistré, vous pouvez indiquer un nom et une description.
Le préréglage apparaît alors dans la liste déroulante des préréglages et vous pouvez l'invoquer simplement en le sélectionnant.
Si vous souhaitez partager ce préréglage avec d'autres utilisateurs, vous pouvez utiliser le bouton de partage :

Pour partager un préréglage, vous recevrez une URL que vous pourrez transmettre à vos amis :
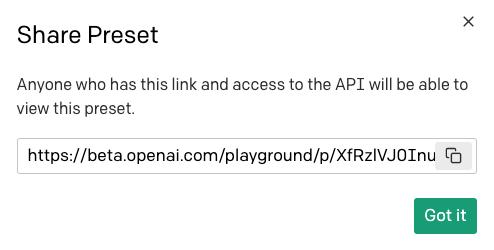
Notez que toute personne qui reçoit cette URL doit avoir accès à OpenAI Playground pour pouvoir utiliser votre préréglage.
Pénalités de fréquence et de présence
Voyons maintenant deux autres options que nous n'avons pas encore explorées. Les curseurs « Frequency Penalty » et « Presence Penalty » vous permettent de contrôler le niveau de répétition auquel GPT-3 a droit dans ses réponses.

La pénalité de fréquence fonctionne en réduisant pour chaque nouvelle utilisation d'un mot la probabilité qu'il soit de nouveau sélectionné. La pénalité de présence ne tient pas compte de la fréquence à laquelle un mot a été utilisé, mais seulement de sa présence dans le texte.
La différence entre ces deux options est subtile, mais on peut voir la pénalité de fréquence comme un moyen d'empêcher les répétitions de mots, et la pénalité de présence comme un moyen d'empêcher que des sujets ne se répètent.
Mes tentatives de comprendre le fonctionnement de ces deux options n'ont pas été très heureuses. En général, j'ai constaté qu'en réglant ces options sur leurs valeurs par défaut de 0, GPT-3 a peu de chances de se répéter du fait de la randomisation que lui donnent les paramètres Temperature et/ou Top P. Dans les quelques situations où j'ai trouvé certaines répétitions, je me suis contenté de déplacer les deux curseurs jusqu'à 1 et cela a corrigé le problème.
Voici un exemple où j'ai donné à GPT-3 une description du langage de programmation Python (repris de sa propre réponse), et où je lui ai demandé ensuite de me donner une description du langage JavaScript. Avec la température et les pénalités de fréquence et de présence toutes réglées sur zéro, voici ce que j'ai obtenu :

Vous pouvez voir que cette description n'est pas si bonne que ça. GPT-3 nous dit à deux reprises que JavaScript est un langage de script et qu'il est basé sur des prototypes. En réglant les deux paramètres de pénalité de répétition sur 1, j'obtiens une bien meilleure définition :

L'option « Best of »
L'option « Best of » peut être utilisée pour que GPT-3 génère plusieurs réponses à une requête. L'interface Playground sélectionne ensuite la meilleure et l'affiche.

Je n'ai pas vraiment trouvé de bonne utilisation de cette option, parce que la manière dont l'interface décide laquelle des différentes options est la meilleure me paraît peu claire. En outre, lorsque vous réglez cette option sur toute autre valeur que 1, l'interface Playground cesse d'afficher les réponses à mesure qu'elles sont générées en temps réel, car elle doit recevoir la liste complète des réponses pour pouvoir choisir la meilleure.
Affichage des probabilités des mots
La dernière option de la barre latérale de paramètres est « Show Probabilities », une option de débogage qui vous permet de voir pourquoi certains jetons ont été sélectionnés.
Chargez à nouveau le préréglage ELI5. Réglez « Show Probabilities » sur « Most Likely » puis relancez la requête avec le mot « book ». Le texte résultant apparaîtra en couleur :
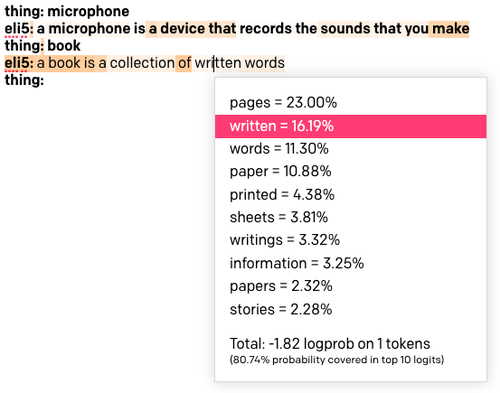
Plus l'arrière-plan d'un mot est sombre, plus ce mot était susceptible d'être choisi. Si vous cliquez sur un mot, vous verrez une liste de tous les mots qui avaient été envisagés à cette position dans le texte. Vous pouvez voir ci-dessus que j'ai cliqué sur le mot « written », qui a une couleur assez claire, et il s'avère que c'était le deuxième choix préféré après le mot « pages ». Ce mot a été choisi à la place du mot préféré en raison de la randomisation des paramètres Top P et/ou Temperature.
Lorsque cette option est réglée sur « Least Likely », la couleur des arrière-plans fonctionne à l'inverse, les plus sombres étant affectés aux mots sélectionnés alors même qu'ils ne faisaient pas partie des choix les plus probables.
Si vous définissez l'option sur « Full Spectrum », vous verrez à la fois les mots les moins et les plus probables en couleur, les mots les plus probables indiqués par des tons verts et les mots les moins probables par des tons rouges.

Implémentation d'un chatbot
Du fait de la grande quantité de texte utilisée pour créer le modèle de langage GPT-3, il est possible de construire des robots très avancés capables de tenir une conversation apparemment intelligente sur un grand nombre de sujets différents.
Pour notre dernier projet, nous allons créer un chatbot libre qui vous permettra de discuter avec GPT-3 de tout ce que vous aimez. Voici un exemple de session de chat au sujet de Python et de développement web que j'ai eue avec ce bot :

Vous pouvez voir dans la capture d'écran que l'entraînement ne correspond qu'aux deux premières lignes, dans lesquelles j'ai saisi des salutations fictives entre un humain et l'IA. Les mots que j'ai utilisés ici sont informels, parce que je voulais qu'il soit amusant et intéressant de discuter avec le bot. Si vous vouliez créer un chatbot plus « sérieux », il vous faudrait ajuster ces lignes en conséquence.
Rétablissez les paramètres par défaut de votre interface Playground, puis saisissez les deux premières lignes ci-dessus (ou des lignes similaires que vous trouvez à votre goût). Dans la troisième ligne, ajoutez le préfixe Human: en laissant la ligne libre pour que l'on puisse y saisir du texte.
En termes de paramètres, voici que j'ai utilisé :
- Response Length : 512
- Temperature : 0.9
- Top P : 1
- Frequency Penalty : 1
- Presence Penalty : 1
- Best Of : 1
- Show Probabilities : Off
- Inject Start Text:
↵AI: - Inject Restart Text:
↵Human: - Stop Sequences:
↵Human:et↵
La plupart des paramètres ci-dessus devraient être clairs au vu des exemples de la section précédente, mais c'est la première fois que j'utilise plus d'une séquence d'arrêt. Lors de l'utilisation de taux élevés de randomisation, que ce soit avec Temperature ou avec Top P, j'ai constaté que GPT-3 répond parfois en générant plusieurs paragraphes. Pour éviter que le chat ne devienne trop long et ne se répète sur un grand nombre de paragraphes, j'ai ajouté un caractère de saut de ligne comme deuxième séquence d'arrêt, de sorte que chaque fois que GPT-3 tente de créer un nouveau paragraphe, la séquence d'arrêt entraîne la fin de la réponse.
Essayez de discuter avec le bot de n'importe quel sujet que vous aimez, mais gardez à l'esprit qu'à ce stade, le modèle de langage ne connaît pas les événements actuels car son jeu d'entraînement n'inclut aucune donnée ultérieure à octobre 2019. Par exemple, bien que j'aie pu constater que le bot était très bien informé sur les coronavirus en général, il ne connaît rien de la pandémie de COVID-19.
Une fois que vous avez déterminé vos paramètres favoris, réinitialisez le texte vers l'entraînement initial et enregistrez la discussion comme préréglage. Dans la section suivante, nous allons transférer cette discussion vers Python.
Migration de Playground vers Python
OpenAI a mis à disposition un package Python permettant d'interagir avec GPT-3, rendant ainsi la tâche de migration d'une application depuis l'interface Playground facile.
Pour suivre cette partie du tutoriel, Python 3.6 ou une version ultérieure doit être installé sur votre ordinateur. Commençons par créer un répertoire de projet dans lequel nous allons créer notre projet Python :
Dans ce projet nous allons utiliser les meilleures pratiques Python. Pour ce faire, nous allons créer un environnement virtuel dans lequel nous allons installer le package OpenAI. Si vous utilisez un système d'exploitation Unix ou Mac OS, saisissez les commandes suivantes :
Pour ceux qui suivent le didacticiel sous Windows, entrez les commandes suivantes dans une fenêtre d'invite de commande :
Envoyer une requête GPT-3
Le code nécessaire pour envoyer une requête au moteur GPT-3 peut être obtenu directement depuis l'interface Playground. Sélectionnez le préréglage enregistré pour la discussion que vous avez sauvegardée précédemment (ou votre préréglage favori), puis cliquez sur le bouton « Exporter Code » dans la barre d'outils :

Une fenêtre contextuelle contenant un extrait de code Python que vous pouvez copier dans le presse-papiers s'affiche. Il s'agit du code qui a été généré pour mon préréglage de discussion :
Bien qu'il soit vraiment très utile et puisse nous mener assez loin, il convient de prendre note de certains points.
Les options « Inject Start Text » et « Inject Restart Text » sont définies comme les variables start_sequence et restart_sequence, mais ne sont pas utilisées dans la requête API réelle. Cela est dû au fait que ces options de Playground n'existent pas dans l'API OpenAI et sont mises en œuvre directement par la page web Playground. Nous devrons donc répliquer leurs fonctionnalités directement dans Python.
De plus, nous avons vu comment exécuter plusieurs interactions d'affilée avec GPT-3, où chaque nouvelle requête comprend les invites et les réponses des requêtes précédentes. Cette accumulation de contenu est également implémentée par l'interface Playground et doit être répliquée avec la logique de Python.
En utilisant l'extrait de code Python ci-dessus comme base, j'ai créé une fonction gpt3() qui imite le comportement de Playground. Copiez le code ci-dessous dans un fichier nommé gpt3.py:
Tout d'abord, dans ce code, j'importe la clé OpenAI à partir d'une variable d'environnement, car c'est plus sûr que d'ajouter votre clé directement dans le code comme suggéré par OpenAI.
La fonction gpt3() reprend tous les arguments que nous avons vus auparavant définissant comment exécuter une requête GPT-3. Le seul argument requis est prompt, qui est le texte réel de la requête. Pour tous les autres arguments, j'ai ajouté des valeurs par défaut qui correspondent à Playground.
À l'intérieur de la fonction, j'exécute une requête GPT-3 utilisant un code similaire à l'extrait de code suggéré. Pour l'invite, j'ai ajouté le texte de début utilisé précédemment, afin de reproduire le côté pratique qu'offre l'interface Playground de ne pas avoir à l'ajouter manuellement.
La réponse de GPT-3 est un objet dont la structure est la suivante :
À partir de ces données, seul le texte réel de la réponse nous intéresse, donc j'ai utilisé l'expression response.choices[0].text pour le récupérer. La raison pour laquelle choices est renvoyé sous forme de liste est qu'il existe dans l'API OpenAI une option permettant de demander plusieurs réponses à une requête (elle est en fait utilisée par le paramètre « Best Of » dans Playground). Nous n'utilisons pas cette option, donc la liste choices n'aura toujours qu'une seule entrée pour nous.
Après avoir mis le texte de la réponse dans la variable answer, je crée une nouvelle invite qui inclut l'invite d'origine concaténée avec la réponse et le texte de redémarrage, exactement comme le fait Playground. L'objectif de la génération d'une nouvelle invite est de la renvoyer à l'appelant afin qu'elle puisse être utilisée dans un appel de suivi. La fonction gpt3() renvoie à la fois la réponse autonome et la nouvelle invite.
Notez que je n'ai pas utilisé toutes les fonctionnalités de l'API dans ce code. La documentation OpenAI API est la meilleure référence pour en savoir plus sur toutes les fonctionnalités disponibles. Veillez donc à vous y référer si vous trouvez quelque chose qui puisse être utile à votre projet.
Créer une fonction de chat
Sur la base de la fonction gpt3() de la section précédente, nous pouvons maintenant créer une application de chat. Placez le code suivant dans un fichier appelé chat.py:
La seule dépendance utilisée par cette application est la fonction gpt3() de la section précédente, que nous importons en haut.
La fonction chat() crée une variable prompt qui est affectée à l'échange fictif entraînant GPT-3 sur la structure du chat. Nous entrons ensuite dans la boucle du chat, qui commence par demander à l'utilisateur de saisir son message à l'aide de la fonction Python input(). Le message utilisateur est ajouté à l'invite, puis gpt3() est appelée avec l'invite et les paramètres de configuration souhaités. La fonction gpt3() renvoie une réponse et l'invite mise à jour. Nous montrons à l'utilisateur la réponse, puis dans l'itération suivante de la boucle, nous allons répéter le cycle, cette fois en utilisant une invite mise à jour incluant la dernière interaction.
La discussion se termine lorsque l'utilisateur appuie sur Ctrl-C pour arrêter le script Python.
Exécution du bot Python
Pour tester cette application, vous devez d'abord définir la variable d'environnement OPENAI_KEY. Si vous utilisez Mac OS X ou Linux, procédez comme suit :
Dans l'invite de commande Windows, vous pouvez le faire comme suit :
Vous trouverez votre clé OpenAI sur la page Developer Quickstart. À partir des deux clés indiquées sur cette page, utilisez celle intitulée « Secret ».
Une fois la clé configurée dans votre environnement, démarrez le chat en tapant python chat.py et commencez à discuter avec le bot ! Voici un exemple d'interaction que vous pourrez obtenir :
Utilisation d'autres langages que Python
Vous pouvez adapter l'exemple Python à d'autres langages, mais il se peut qu'aucune bibliothèque OpenAI ne soit disponible. Ce n'est pas un problème, car l'API OpenAI est une API HTTP relativement standard à laquelle vous pouvez accéder par le biais de requêtes HTTP brutes.
Pour apprendre comment envoyer une requête pour un préréglage Playground donné, vous pouvez utiliser le même bouton « Exporter Code », mais cette fois, sélectionnez l'onglet « curl » pour afficher la requête HTTP.
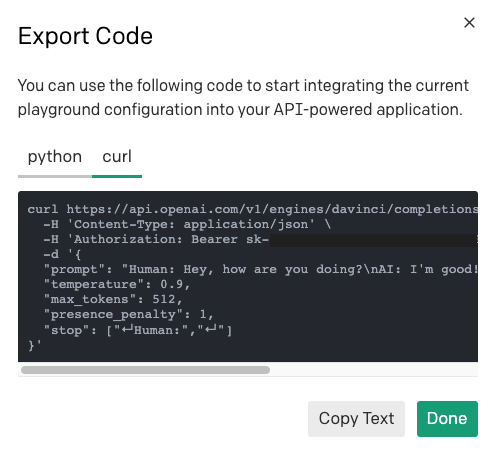
Vous pouvez utiliser la commande curl pour comprendre ce que l'URL, les en-têtes et la charge utile doivent être, puis traduire le tout vers le client HTTP de votre choix dans votre langage de programmation.
Conclusion
Que le voyage fut long ! J'espère que vous comprenez désormais comment fonctionne l'API OpenAI et comment travailler avec GPT-3.
Voulez-vous apprendre à utiliser GPT-3 avec Twilio et Python ? J'ai écrit un de création d'un chatbot SMS GPT-3, et mon collègue Sam Agnew a également réalisé un tutoriel de fan fiction Dragon Ball GPT-3 très amusant.
J'adorerais voir les super applications que vous construisez avec GPT-3 !
Miguel Grinberg est développeur Python pour le contenu technique chez Twilio. Contactez-le à mgrinberg [at] twilio [dot] com si vous avez un projet Python que vous souhaitez partager sur ce blog !



Ressources connexes
Twilio Docs
Des API aux SDK en passant par les exemples d'applications
Documentation de référence sur l'API, SDK, bibliothèques d'assistance, démarrages rapides et didacticiels pour votre langage et votre plateforme.
Centre de ressources
Les derniers ebooks, rapports de l'industrie et webinaires
Apprenez des experts en engagement client pour améliorer votre propre communication.
Ahoy
Le hub de la communauté des développeurs de Twilio
Meilleures pratiques, exemples de code et inspiration pour créer des expériences de communication et d'engagement numérique.