PythonとBeautiful SoupでWebスクレイピングとHTML解析をする方法
Time to read:
October 22, 2019
執筆者
レビュー担当者
インターネットにはあまりに多くのデータがあふれています。しかし、これらのデータがREST APIの形式ではないと、プログラムによってアクセスすることは難しくなります。Beautiful SoupなどのPythonツールを使用すると、Webページから直接データをスクレイピングして解析し、プロジェクトやアプリケーションで使えるようになります。
本稿では、インターネットからMIDIデータをスクレイピングする方法をご紹介します。過去のブログで、Magentaによるニューラルネットワークのトレーニングを使用してクラシックな任天堂ゲームミュージックを作成する方法をご紹介しました。この実装には、昔の任天堂ゲームのMIDIミュージックが必要になります。今回は、Beautiful Soupを使用して、ビデオゲーム音楽アーカイブからMIDIデータを取得する方法をご紹介します。
プロジェクトの準備と依存パッケージの設定
まず、最新バージョンのPython 3とpipがインストールされていることを確認してください。また、依存パッケージをインストールする前に、仮想環境を作成して有効にしてください。
Webページからのデータ取得のHTTPリクエストを作成するRequestsライブラリと、HTMLを解析するBeautiful Soupをインストールする必要があります。
仮想環境を有効にしたら、ターミナルで次のコマンドを実行します。
Beautiful Soup 4を使用します。現時点では、Beautiful Soup 4が最新バージョンで、Beautiful Soup 3は開発とサポートが終了しています。
Beautiful Soupで解析するデータをRequestsでスクレイピングする
実際にアプリケーションを構築する前に、WebページからHTMLを取得するコードを作成し、そのデータを解析する方法を見てみましょう。次のコードは目的のWebページにGETリクエストを送り、そのページのHTMLをもとにBeautifulSoupオブジェクトを作成します。
soupオブジェクトを使用してHTMLのデータを検索します。例えば、上記のコードの後にPythonシェルでsoup.titleを実行すると、Webページのタイトルが取得できます。print(soup.get_text())を実行すると、ページの全テキストを見ることができます。
Beautiful Soupを使う
find()とfind_all()メソッドはとりわけ強力なツールです。soup.find()は、例えばbodyタグなど、見つけたい要素が1つだけと分かっている場合に大変役立ちます。Webページに対してsoup.find(id='banner_ad').textを使用すると、バナー広告のHTML要素のテキストが取得できます。
soup.find_all()はWebスクレイピングで最もよく使われるメソッドです。これによりページのすべてのハイパーリンクを反復してURLを出力できます。
find_allで正規表現やタグ属性などの引数を使用すると、条件を指定して検索を絞り込むことも可能です。Beautiful Soupの便利な機能について詳しくは、Beautiful Soup公式ドキュメントを参照してください。
Beautiful SoupでHTMLを解析する
コンテンツを解析するコードを作成する前に、ブラウザでHTMLを見てみましょう。Webページはそれぞれ異なるため、目的のデータを取得するには少し工夫を凝らし、パターン認識などを試みる必要があります。
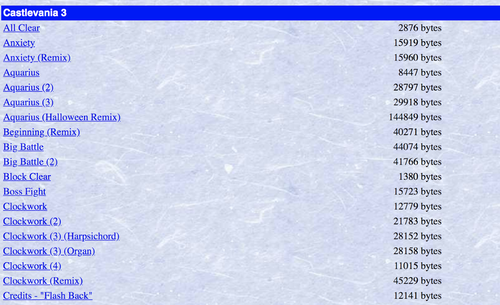
目的は大量のMIDIファイルをダウンロードすることですが、このWebページには多くの重複する曲やリミックスも含まれています。必要なのは各曲一つだけで、最終的にこのデータをもとにニューラルネットワークで正確に任天堂ミュージックを作れるようにするため、手が加えられたリミックスは使用しません。
Webページを解析するコードの作成は、最新ブラウザで利用できる開発者ツールを使って行うことがおすすめです。目的の要素を右クリックすると、その要素のHTMLを詳しく見て、必要なデータにプログラムでアクセスする方法を知ることができます。
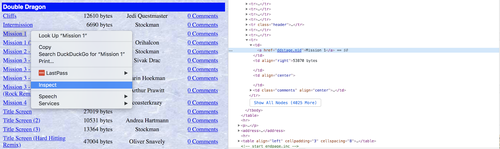
次にfind_allメソッドを使用してページのすべてのリンクを調べます。正規表現を使用して条件を絞り込み、タイトルに括弧が含まれないMIDIファイルのリンクのみを取得します。これにより、重複する曲やリミックスが排除されます。
nes_midi_scraper.pyファイルを作成し、次のコードを追加します。
ページから入手したいすべてのMIDIファイルを絞り込み、リンクタグを出力し、入手したいファイルの総数を出力します。
ターミナルからpython nes_midi_scraper.pyコマンドでコードを実行します。
Webページから目的のMIDIファイルをダウンロードする
目的のMIDIファイルをフィルタリングするコードができたところで、ファイルをすべてダウンロードするコードを作成します。
以下のようにnes_midi_scraper.pyファイルのコードにdownload_track関数を追加し、ループでそれぞれのトラックに対して関数を呼び出します。
download_track関数では、MIDIファイルへのリンクのHTML要素を表すBeautiful Soupオブジェクトを渡します。その際、ファイル名が重複するのを避けるために使用する一意の番号も渡します。
MIDIファイルを保存したいディレクトリからこのコードを実行すると、ターミナルの画面にダウンロードした全2230曲(記事作成時点の数)のMIDIファイルが表示されます。

これは、Beautiful Soupの活用方法のほんの一例に過ぎません。
広大なWorld Wide Webを活用するために
これで、プログラムを使用してWebページのコンテンツを収集できるようになりました。膨大なデータにアクセスし、あらゆるプロジェクトのニーズに応えることができます。1つ注意すべき点があります。WebページのHTMLが変更されるとコードが機能しなくなることがあるため、スクレーピングをベースとするアプリケーションの作成では、指定する要素を最新の状態にしておく必要があります。
ビデオゲーム音楽アーカイブから取得したデータを使って他にできることをお探しなら、MIDIデータを操作するためのMidoを使用してクリーンアップを行ったり、Magentaを使用してニューラルネットワークをトレーニングしたり、任天堂ミュージックが聞ける電話番号を作成してみてはいかがでしょうか?
皆さんが何を構築されるか、とても楽しみです。体験談の共有やご質問など、どうぞお気軽にお問い合わせください。
- メール: sagnew[at]twilio.com
- Twitter: @Sagnewshreds
- Github: Sagnew
- Twitch(ライブストリーミングコード): Sagnewshreds