Getting Started with Apache Spark by Analyzing Pwned Passwords
Time to read:
June 29, 2018
Written by
This post is part of Twilio’s archive and may contain outdated information. We’re always building something new, so be sure to check out our latest posts for the most up-to-date insights.

Apache Spark aims to solve the problem of working with large scale distributed data and with access to over 500 million leaked passwords we have a lot of data to dig through. If you spend any time with the password data set, you’ll notice how simple most passwords are. This is why we’re always thinking about how to encourage stronger passwords and recommend turning on Two-factor authentication everywhere it’s available.
While tools like Excel and Python are great for data analysis, Spark helps solve the problem of what to do once the data you’re working with gets too large to fit into the memory of your local computer.
This tutorial will show you how to get setup for running Spark and introduce the tools and code that allow you to do data manipulation and exploration. Read on to find out how to spot the most common password lengths, suffixes, and more.
500 Million Pwned Passwords 😱
We’re using a combination of the raw pwned password data from Troy Hunt joined with some known common passwords. The pwned password data contains SHA-1 hashes of passwords and a count of the number of times that password has been pwned. Hunt explains more about why he stores the data that way: “[the] point is to ensure that any personal info in the source data is obfuscated such that it requires a concerted effort to remove the protection, but that the data is still usable for its intended purposes”. Our analysis won’t be terribly interesting only looking at hashed passwords, so we already grabbed known common passwords and joined those with our data.
Download the data from GitHub:
Running Zeppelin
We’ll be using Apache Zeppelin to explore the data. Zeppelin is an open source project that allows you to create and run Apache Spark applications from a local web application notebook. It’s similar to Jupyter notebooks if you’ve worked with those in the past. For the purposes of getting familiar with Spark, we’re only going to be looking at local data in this tutorial.
Make sure you have docker installed and running, and run the following command from your terminal to run Zeppelin:
This will grab the project from Docker Hub and run Zeppelin inside of a docker container. It’s important to include the -v flag to mount volumes so that we can access the data from our local machine.
Zeppelin runs on port 8080, so navigate to http://localhost:8080 and you’ll see the Zeppelin interface.
Note – the folder you start zeppelin from becomes your working file directory.
Spark Data Collections
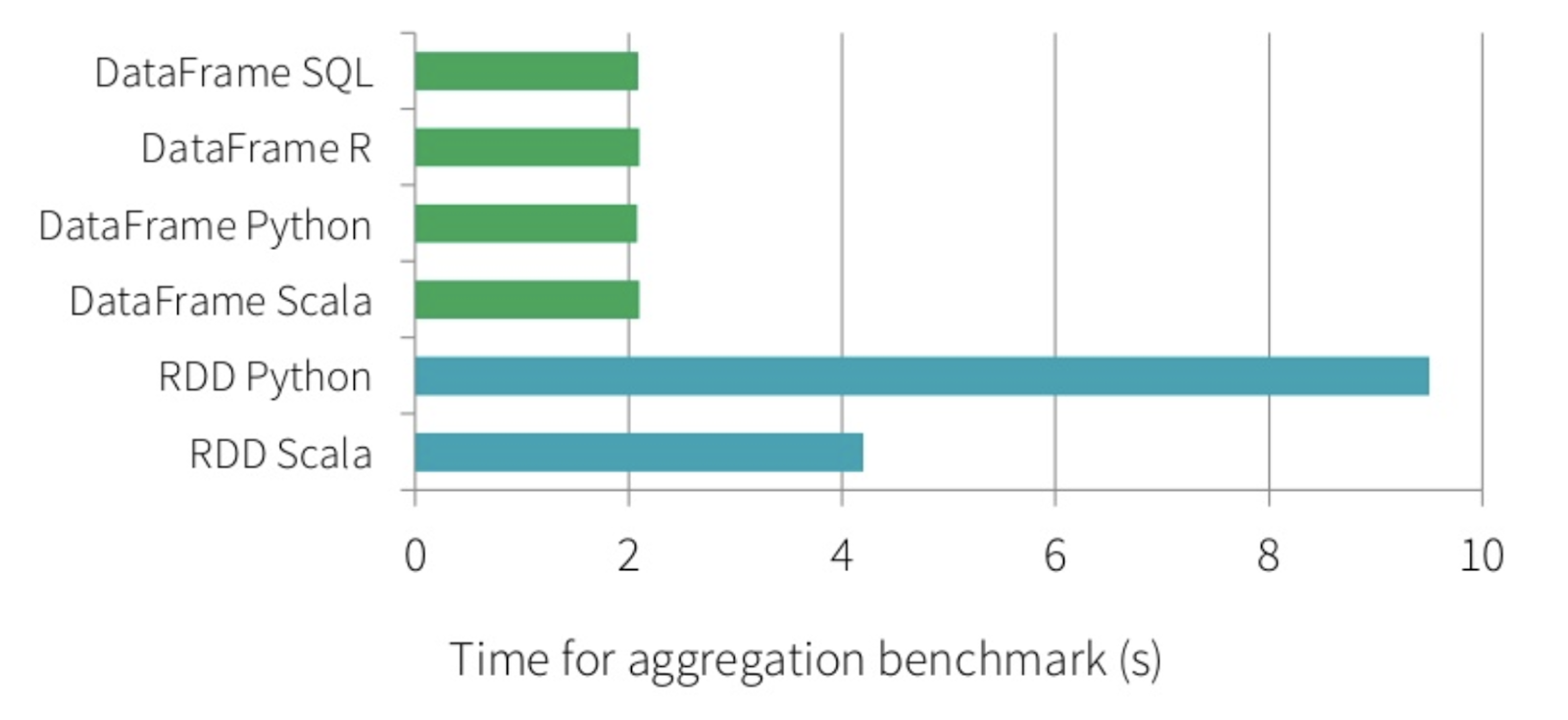
We’re going to be working with Datasets in this post, an abstraction that was introduced recently to the Spark project. Datasets require structured or semi-structured data, are strongly typed, and are about two times faster than their predecessor, the RDD.
https://www.slideshare.net/databricks/composable-parallel-processing-in-apache-spark-and-weld
Spark and Zeppelin have interpreters for Scala, Python, Spark. This post will mostly use Scala code but Spark also has built in support for Python or SQL if that’s more your style.
Creating our first Notebook
Let’s make sure everything works as expected in Zeppelin. Create a new notebook from the Notebook dropdown.
Name your notebook and choose spark as the default interpreter.
Let’s start by reading in a file. Spark has built in capabilities for reading data in CSV, JSON, text, and more. Copy the following code into the notebook cell to read in our CSV data:
If you’re getting a Path does not exist exception, make sure you ran the docker run command from inside the password-data folder. Run the code by pressing SHIFT ENTER or clicking the Play button in the upper right hand corner of the cell. You should see output that looks like this:
Viewing the schema is useful for understanding the shape of our data, but we can also look at the data itself with the following code:
You can now see some of the most common passwords and the number of times they’ve been seen in a data breach. We’re using the SQL domain specific language for Spark SQL to grab this data, which allows us to select, filter, and sort the data.
Analyzing Pwned Passwords
Now that we have data to work with we can start looking into some more interesting analyses. Spark SQL provides some built in functions for working with our Datasets. Let’s find out what the most common length of a pwned password is by adding a column that gives us the length of each password
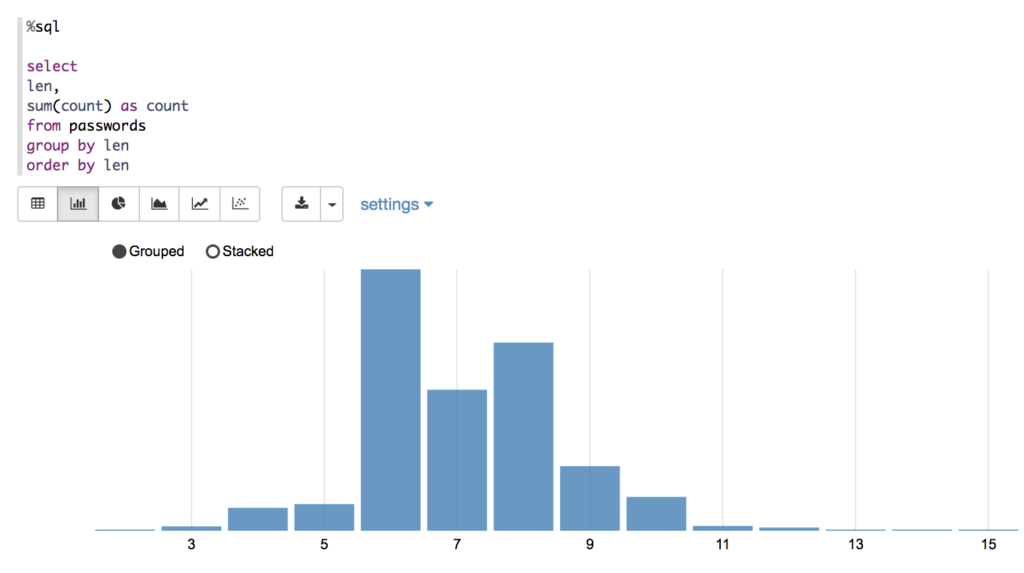
Our output proves that the most common lengths are 6 and 8 characters, which makes sense since those are common minimum password length requirements.
Check out the documentation to see a list of methods available on Datasets. Try running a few other queries on the data that look for common patterns like suffixes.
Using Python or SQL instead of Scala
Remember when we set up our interpreter to default to spark? One of the neatest things about working with Zeppelin is that you can work with other interpreters in the same notebook. Try pasting the following Python code into a new cell.
Don’t forget the %pyspark at the top, that’s what tells Zeppelin which interpreter to use.
You can also write raw SQL. First you need to establish a temp view that your SQL interpreter can read. Add that like so using the default spark interpreter:
In a new cell, try writing some SQL code to see what the most common password lengths are.
This gives us a similar answer to what we wrote in Scala above. What we lack in compile time safety we gain in nifty data visualizations. These are built into Zeppelin and allow you to display your data in graph form with the click of a button. Here’s the bar chart that shows the most common password lengths.
Analyze Away
Now that you have some of the basics of working with Spark, Spark SQL, and Zeppelin, try using the tools to explore your own data. I talked about this extensively at GOTO Chicago this year, and you can check out that video on YouTube or peruse the slides.
I’ve uploaded an example notebook with this code to ZEPL – check that out and get some more inspiration for the type of queries you can run. There are plenty more ways to analyze password data if you’re still looking for inspiration.
Spark is an awesome project for working with distributed data and I’ve compiled some resources to keep you going:
For more use cases for Troy Hunt’s pwned passwords API, check out my post on how to use the API from 7 different languages. If you have any questions about Spark, Scala, or Security, find me on Twitter @kelleyrobinson.


Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.