How Twilio Manages MySQL Clusters at Scale
Time to read: 4 minutes
October 24, 2018
Written by

Developers at Twilio write, deploy, and operate their own microservices. This aligns engineers with the incentive to write maintainable code and address the shortcomings of their own services. As part of this alignment, each product software development team is responsible for operating and managing their own services, including their database clusters. Our goal as a Platform Organization is to help Twilio product engineering teams succeed by giving them self-service tools and automation to empower their development and operation of Twilio’s services.
If Twilio’s product engineering teams are vertical columns, Twilio’s platform engineering teams are horizontal blocks supporting these columns. Twilio’s Platform engineering teams use metrics such as deployment velocity, product feature velocity, NPS, and incident reduction to track our impact on the rest of the Twilio engineering organization. We have weekly syncs and quarterly surveys where we ask other teams for candid feedback. Through these, we look for opportunities to help empower other developers at Twilio to efficiently deliver code. As a result of this feedback loop, it became clear that MySQL deployments was the top headache for our rapidly growing and developing product teams.
Pain Points Before MySQL Deployments
We noticed that there was a need for a tool to help automate the process of provisioning and managing database clusters because the manual process was consuming too much of an engineer’s time.
One of the most common database operations is changing the database schema. At Twilio, a typical MySQL cluster is made up of one primary, two replicas, one backup and one analytics node. The primary and replicas are responsible for serving traffic. The backup, as the name implies, is used to take nightly backups and the analytics is used to send metrics to Datadog. It is standard procedure to apply the change to one node in the cluster, usually the backup node, and then take a backup. This assures that we have the most up to date data because backups are taken every night. This backup is encrypted and saved in S3 and is pulled down when new nodes are booted. Finally, the cluster must be pivoted to pick up the changes. A pivot is when a candidate primary or a current replica is made the primary and the remaining replicas are pointed to replicate from the new primary.
A typical pivot involved the following steps:
- Manually boot a new cluster into the correct availability zones with the correct number of replicas
- Wait for the cluster to boot, restore from previous encrypted backup and replicate any new data from the primary (could take minutes to hours)
- SSH onto MHA (Master High Availability) monitor and run a “pivot status” script to verify the cluster can be pivoted
- Ensure the pivot status is successful and fix any errors, such as not enough slaves or replication lag
- SSH onto MHA monitor and run “pivot” command to perform pivot
- Repeat the above for each shard of the database cluster
- Repeat above for each environment - Development, Stage, Production
Pivoting is tedious, time consuming, and error prone. It can take a proficient engineer a half day with the potential to consume even more time if something unexpected occurs. This requires the engineer to context switch many times. Other steps are repetitive, such as trying to distribute the cluster across all availability zones for high availability. It is an ideal candidate for automation.
MySQL Deployments
First, we designed a pivot daemon, pivotd, capable of executing pivots. This runs alongside a custom Twilio MySQL manager service called mymanager that is built on top of mha4mysql-manager. Additionally, we added a REST API so we could integrate it with existing Platform tools.
Next, we leveraged our existing architecture, such as our deployment convergence engine, which allows us to easily create new deployments to boot the new cluster in the appropriate availability zones. We added new steps for the remaining work and chained them in a dependency tree.
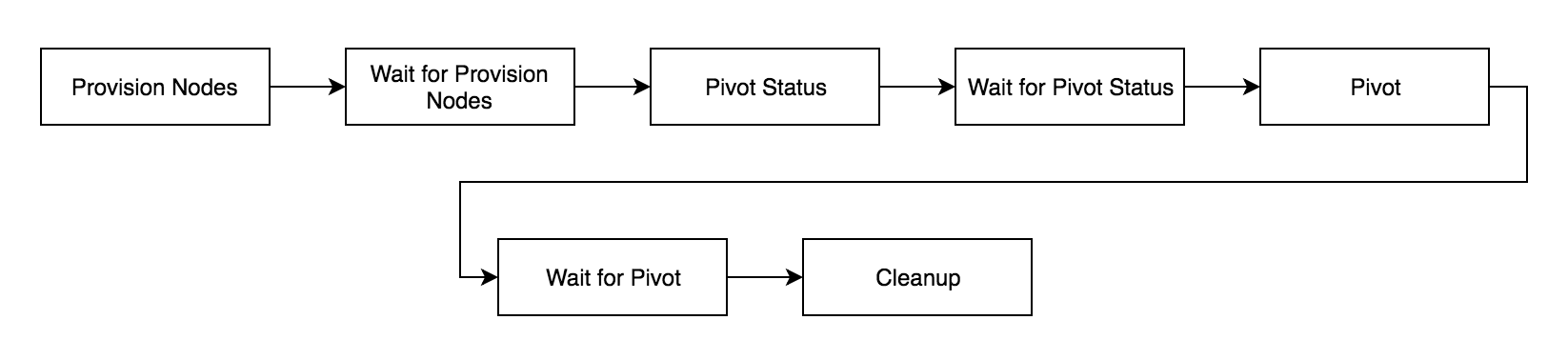
The diagrams below show how the communication between the different services work to execute the Pivot Status, Wait for Pivot Status, Pivot, and Wait for Pivot.
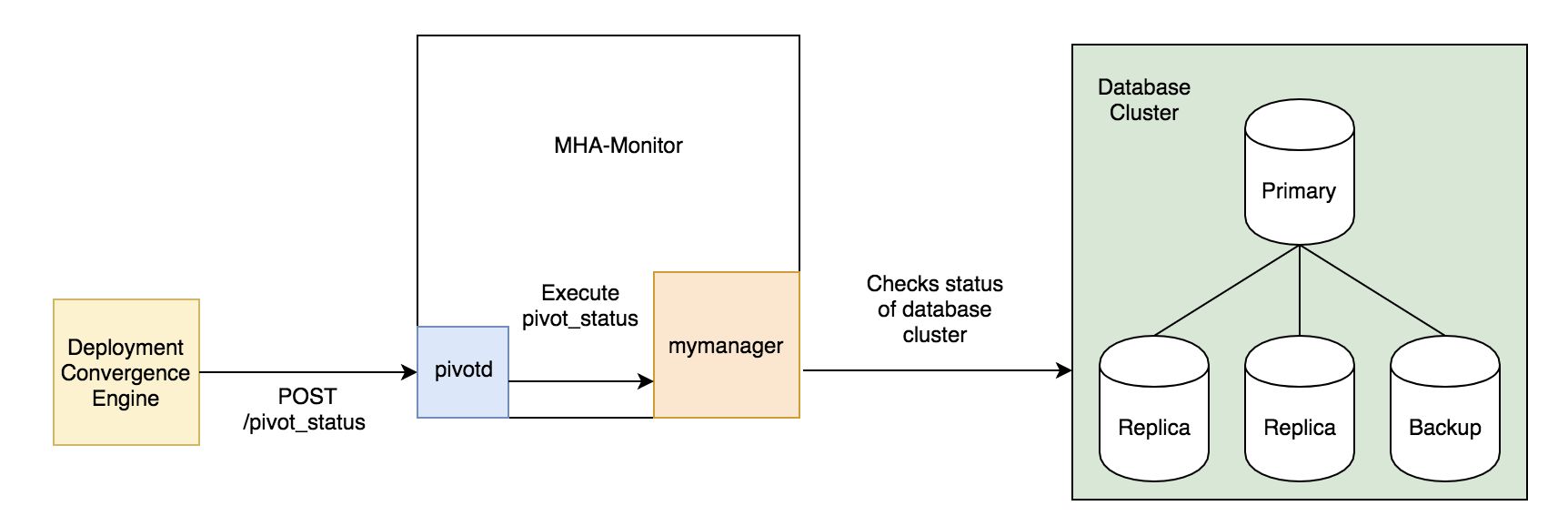
1. Pivot Status: The Deployment Convergence Engine initiates the pivot status by sending a POST request to pivotd. Pivotd executes a pivot status command and mymanager actually checks the status of the cluster.
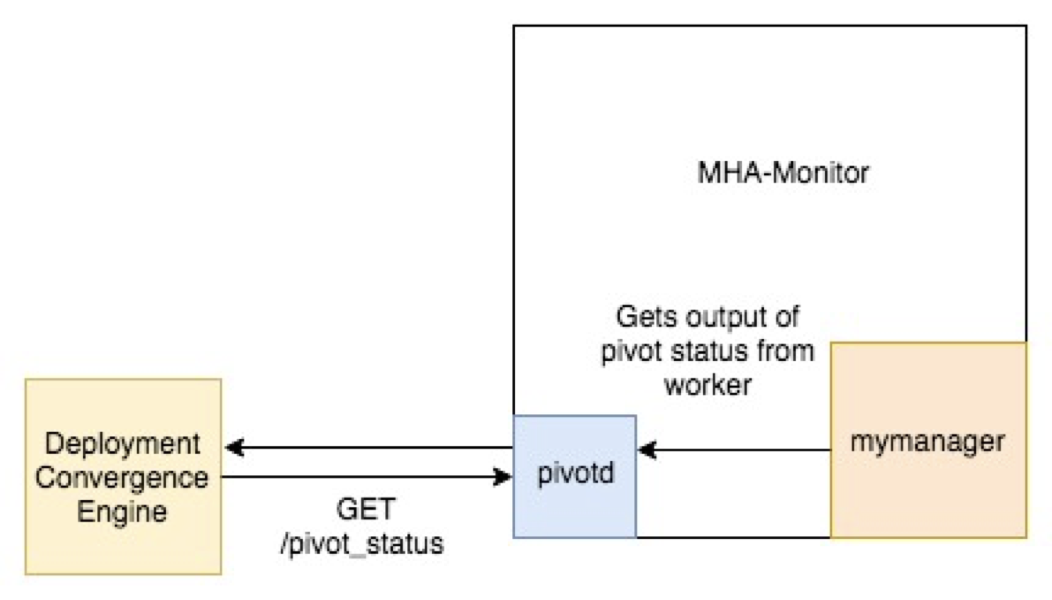
2. Wait for Pivot Status: The Deployment Convergence Engine gets the results of the pivot status by sending GET requests to pivotd at regular intervals until the pivot status completes. Pivotd gets the results of the pivot status from mymanager.
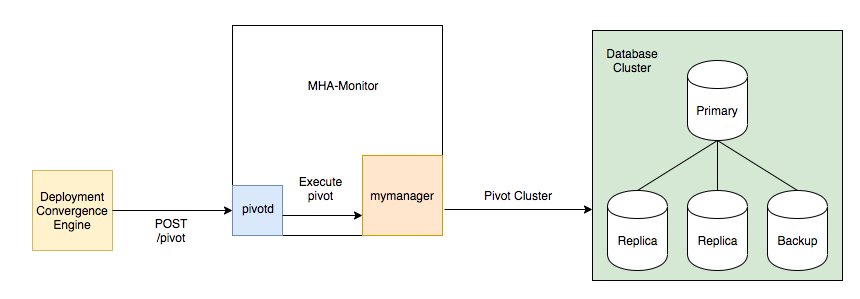
3. Pivot: The Deployment Convergence Engine initiates the pivot by sending a POST request to pivotd. Pivotd tells mymanager to execute the pivot and mymanager pivots the cluster.
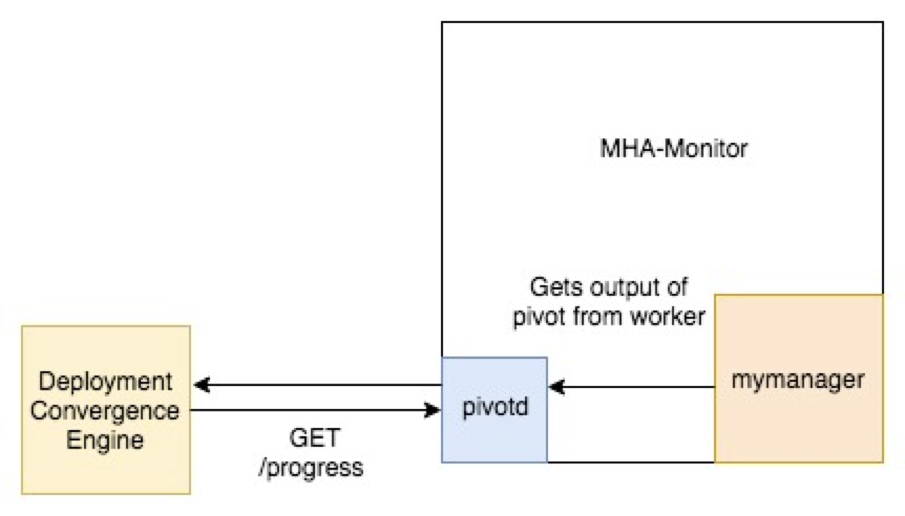
4. Wait for Pivot: The Deployment Convergence Engine gets the results of the pivot by sending GET requests to pivotd at regular intervals until the pivot completes. Pivotd gets the results of the pivot from mymanager.
Users fill out a declarative form with information about their cluster, the information is validated to prevent user errors or unsafe behavior, and the automated system does the rest of the work. As a result, pivoting a database becomes as simple as deploying a stateless service.
MySQL Deployments Wins
MySQL deployments saves time so that more time can be put into designing and building products, not deploying them. Automation also prevents engineers from making errors such as not booting replica nodes into a high availability formation and suffering later when their database cluster goes down. We are challenged to think at scale with a growing company and growing number of MySQL clusters. With this mindset, we’ve seen our deployment velocity outpace the increasing number of engineers at Twilio. This next generation of deployment strategies will allow Twilio’s developers to deliver new software swiftly and reliably.


Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.