$0.6Million/Year savings by using S3 for ChangeDataCapture for DynamoDB Table
Time to read:
July 29, 2024
Written by
$0.6Million/Year savings by using S3 for ChangeDataCapture for DynamoDB Table
At Twilio Segment, the objects pipeline processes hundreds of thousands of messages per second and stores the data state in a DynamoDB table. This data is used by the warehouse integrations to keep the customer warehouses up-to-date. The system originally consisted of a Producer service, DynamoDB, and BigTable. We had this configuration for the longest time, with DynamoDB and BigTable being key components which powered our batch pipeline.
We recently revamped our platform by migrating from BigTable to offset the growing cost concerns, consolidate infrastructure to AWS, and simplify the number of components.
In this blog post, we will take a closer look at the objects pipeline, specifically focusing on how the changelog sub-system which powers warehouse products has evolved over time. We will also share how we reduced the operational footprint and achieved significant cost savings by migrating to S3 as our changelog data store.
Why did we need a changelog store?
The primary purpose of changelog in our pipeline was to provide the ability to query newly created/modified DynamoDB Items for downstream systems. In our case, these were warehouse integrations. Ideally, we could have easily achieved this using DynamoDB’s Global Secondary Index which would minimally contain:
- An ID field which uniquely identifies a DynamoDB Item
- A TimeStamp field for sorting and filtering
But due to the very large size of our table, creating a GSI for the table is not cost-efficient. Below are some numbers related to our table:
- Avg size of item is 900 Bytes
- Monthly storage costs $0.25/GB
- Total size of the table today is ~1 PetaByte
The total number of items back then was 399 Billion. Today it is 958 Billion and still growing.
Initial System, V1
In the V1 system, we used BigTable as our changelog as it suited our requirements quite well. It provided low-latency read and write access to data, which made it suitable for real-time applications.
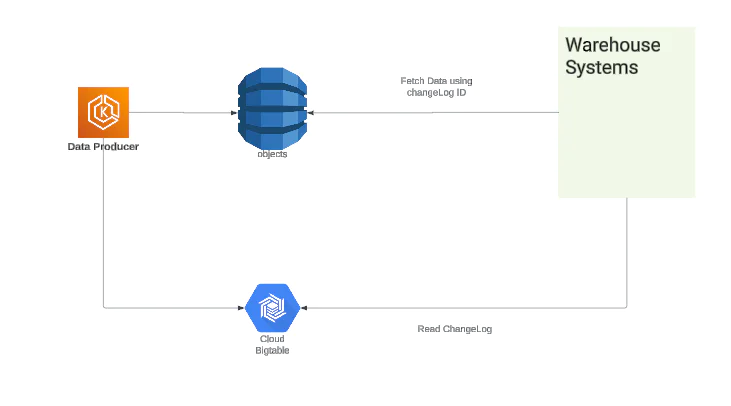
Also, BigTable was designed to scale horizontally, meaning it could handle a large amount of data and traffic. Like any real world system, it was not without trade-offs.
Some of our pain points included:
Responsibility of detection if DynamoDB item has changed or not fell on Producer service
Responsibility of hydrating BigTable fell on Producer service
Infrastructure had to managed across different Public clouds
But there was one large advantage:
The Bigtable costs stood at ~$30K/month which is much lesser than the one time upfront cost of $86K for creating a GSI in existing DynamoDB table of size 376TB and additional monthly ongoing costs of $24K/Month with reserved capacity.
V2 System - Initial Re-Design Considered
Over time operating costs of BigTable increased to $60K/Month as the size of the DynamoDB table grew to 848TB in size. In an effort to alleviate some of the pain points we inherited from V1 and growing costs, we leveraged DynamoDB’s ChangeDataCapture feature. This simplified the business logic on the producer service side.
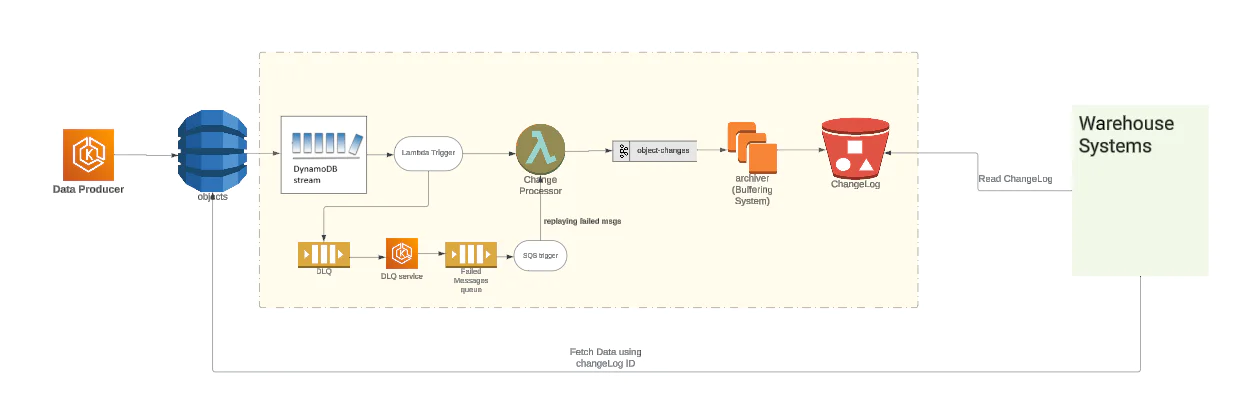
We also introduced newer components like archiver which buffers the changelog entries to a file and uploads them to a partitioned path in the S3 bucket. The Partitioned Path made it easier for downstream systems to query the newly/changed entries to DynamoDB.
Example S3 partition path: <Prefix>/<ProjectID>/<Date>/<Hour_part_of_day>
We ran into some pain points, including:
More moving parts, more points of failure
An increase in operational footprint
The introduction of Lambdas to consume CDC warranted additional components like DLQ Component, Triggers on SQS 🤦
Data migration required additional tooling/efforts
Human intervention was required during lambda outages
But we also saw some advantages:
The introduction of S3 as a changelog store was initially 6 times cheaper than BigTable
Simplified producer logic
The system worked well with lower traffic but proved sub-optimal for handling higher traffic. Our efforts to address it by tuning lamba configuration with higher batch size and more parallelization factor didn’t yield expected outcome, rather proved to be more expensive both in cost and operations.
V3 System
We took our learnings from earlier implementations, so the V3 System uses the best of both implementations. It consolidates all the components to a single Public Cloud (we use AWS) while keeping the costs low. The total cost of the V3 System is less than $10K/month compared to $60K/month with BigTable.
The Producer service writes to object-changes topics using semantic partitioning. The semantic partitioning helps with more effective aggregation of the changelog messages belonging to the same project ID going to the same files. By directly writing to object-changes kafka-topic instead of depending on DynamoDB CDC, we managed to get rid of unnecessary components like DLQ, Lambdas, Lambda Processor, and CDC there by improving overall operational footprint.
This design also minimized data migration efforts from BigTable to S3 without disrupting live traffic. The migration tool simply reads changelog data from BigTable and publishes to object-changes kafka topics. The changelog files are surfaced to correct S3 partitioned paths based on the timestamp field present in kafka message payload.
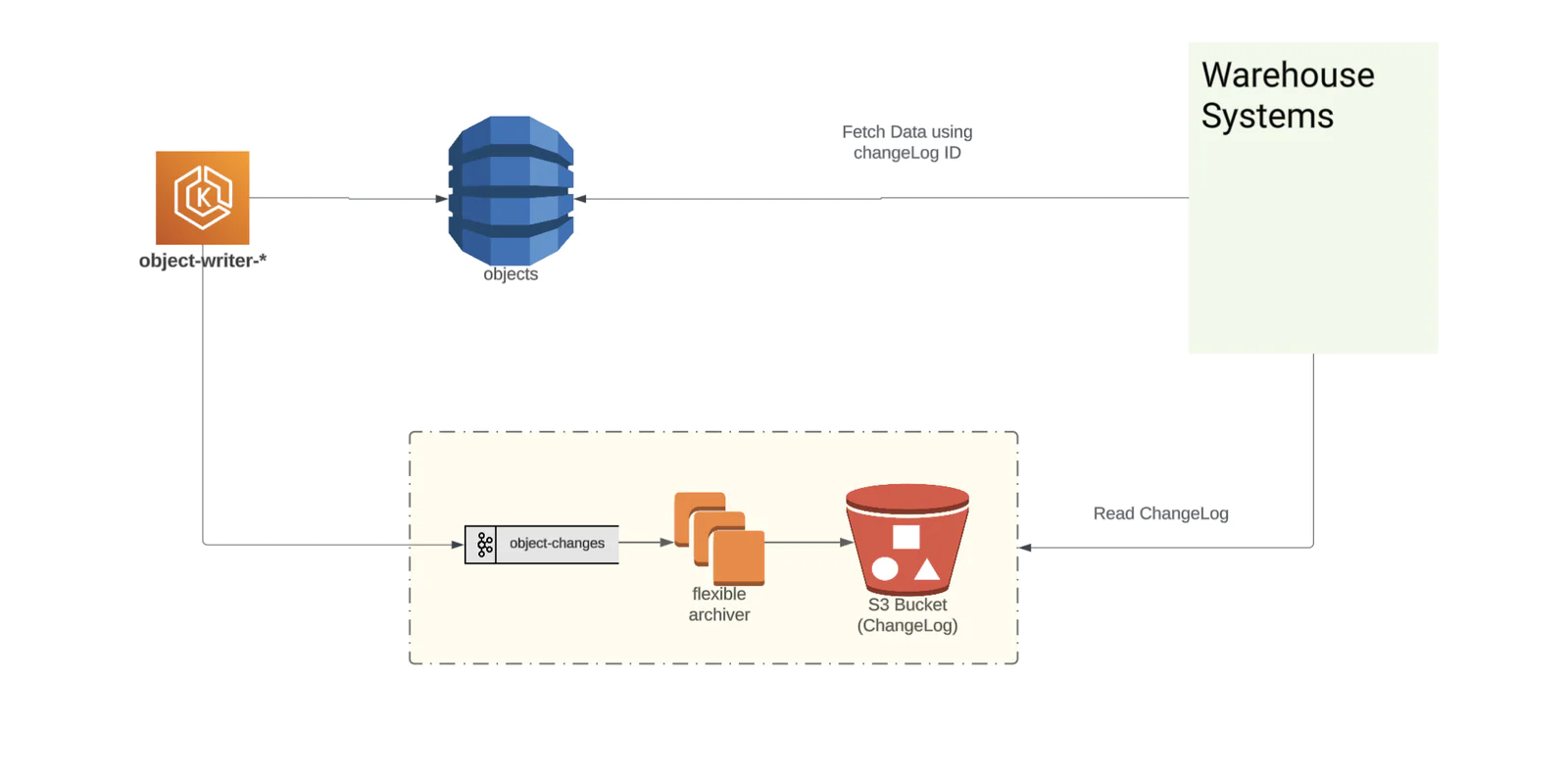
We had one main pain point:
Responsibility of detection if a DynamoDB item has changed or not fell back on Producer service
And a lot more advantages:
Less components compared to the V2 system, less points of failures
Reduced on-call fatigue and operational footprint.
Costs less than $10K/Month
Simplified data migration efforts
Conclusion
By optimizing objects pipeline by transitioning from BigTable to S3 as changelog data store, we greatly reduced the costs and improved operational efficiency. The current system, V3 has led to an annual cost savings of over $0.6Million.
Acknowledgements
Huge thanks to the entire team which made this possible : Akash Kashyap, Y Nguyen, Dominic Barnes, Sowjanya Paladugu, Anthony Vylushchak, Annie Zhao, Emily Jia.
Ready to see what Twilio Segment can do for you?

The Customer Data Platform Report 2025
Drawing on anonymized insights from thousands of Twilio customers, the Customer Data Platform report explores how companies are using CDPs to unlock the power of their data.



Related Resources
Twilio Docs
From APIs to SDKs to sample apps
API reference documentation, SDKs, helper libraries, quickstarts, and tutorials for your language and platform.
Resource Center
The latest ebooks, industry reports, and webinars
Learn from customer engagement experts to improve your own communication.
Ahoy
Twilio's developer community hub
Best practices, code samples, and inspiration to build communications and digital engagement experiences.